 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Transformers Learn to Plan via Multi-Token Prediction
Apr 13, 2026While next-token prediction (NTP) has been the standard objective for training language models, it often struggles to capture global structure in reasoning tasks. Multi-token prediction (MTP) has recently emerged as a promising alternative, yet its underlying mechanisms remain poorly understood. In this paper, we study how MTP facilitates reasoning, with a focus on planning. Empirically, we show that MTP consistently outperforms NTP on both synthetic graph path-finding tasks and more realistic reasoning benchmarks, such as Countdown and boolean satisfiability problems. Theoretically, we analyze a simplified two-layer Transformer on a star graph task. We prove that MTP induces a two-stage reverse reasoning process: the model first attends to the end node and then reconstructs the path by tracing intermediate nodes backward. This behavior arises from a gradient decoupling property of MTP, which provides a cleaner training signal compared to NTP. Ultimately, our results highlight how multi-token objectives inherently bias optimization toward robust and interpretable reasoning circuits.
Milestones over Outcome: Unlocking Geometric Reasoning with Sub-Goal Verifiable Reward
Jan 08, 2026Multimodal Large Language Models (MLLMs) struggle with complex geometric reasoning, largely because "black box" outcome-based supervision fails to distinguish between lucky guesses and rigorous deduction. To address this, we introduce a paradigm shift towards subgoal-level evaluation and learning. We first construct GeoGoal, a benchmark synthesized via a rigorous formal verification data engine, which converts abstract proofs into verifiable numeric subgoals. This structure reveals a critical divergence between reasoning quality and outcome accuracy. Leveraging this, we propose the Sub-Goal Verifiable Reward (SGVR) framework, which replaces sparse signals with dense rewards based on the Skeleton Rate. Experiments demonstrate that SGVR not only enhances geometric performance (+9.7%) but also exhibits strong generalization, transferring gains to general math (+8.0%) and other general reasoning tasks (+2.8%), demonstrating broad applicability across diverse domains.
GeoBench: Rethinking Multimodal Geometric Problem-Solving via Hierarchical Evaluation
Dec 30, 2025Geometric problem solving constitutes a critical branch of mathematical reasoning, requiring precise analysis of shapes and spatial relationships. Current evaluations of geometric reasoning in vision-language models (VLMs) face limitations, including the risk of test data contamination from textbook-based benchmarks, overemphasis on final answers over reasoning processes, and insufficient diagnostic granularity. To address these issues, we present GeoBench, a hierarchical benchmark featuring four reasoning levels in geometric problem-solving: Visual Perception, Goal-Oriented Planning, Rigorous Theorem Application, and Self-Reflective Backtracking. Through six formally verified tasks generated via TrustGeoGen, we systematically assess capabilities ranging from attribute extraction to logical error correction. Experiments reveal that while reasoning models like OpenAI-o3 outperform general MLLMs, performance declines significantly with increasing task complexity. Key findings demonstrate that sub-goal decomposition and irrelevant premise filtering critically influence final problem-solving accuracy, whereas Chain-of-Thought prompting unexpectedly degrades performance in some tasks. These findings establish GeoBench as a comprehensive benchmark while offering actionable guidelines for developing geometric problem-solving systems.
Learning Adaptive and Temporally Causal Video Tokenization in a 1D Latent Space
May 22, 2025We propose AdapTok, an adaptive temporal causal video tokenizer that can flexibly allocate tokens for different frames based on video content. AdapTok is equipped with a block-wise masking strategy that randomly drops tail tokens of each block during training, and a block causal scorer to predict the reconstruction quality of video frames using different numbers of tokens. During inference, an adaptive token allocation strategy based on integer linear programming is further proposed to adjust token usage given predicted scores. Such design allows for sample-wise, content-aware, and temporally dynamic token allocation under a controllable overall budget. Extensive experiments for video reconstruction and generation on UCF-101 and Kinetics-600 demonstrate the effectiveness of our approach. Without additional image data, AdapTok consistently improves reconstruction quality and generation performance under different token budgets, allowing for more scalable and token-efficient generative video modeling.
Beyond Theorem Proving: Formulation, Framework and Benchmark for Formal Problem-Solving
May 07, 2025As a seemingly self-explanatory task, problem-solving has been a significant component of science and engineering. However, a general yet concrete formulation of problem-solving itself is missing. With the recent development of AI-based problem-solving agents, the demand for process-level verifiability is rapidly increasing yet underexplored. To fill these gaps, we present a principled formulation of problem-solving as a deterministic Markov decision process; a novel framework, FPS (Formal Problem-Solving), which utilizes existing FTP (formal theorem proving) environments to perform process-verified problem-solving; and D-FPS (Deductive FPS), decoupling solving and answer verification for better human-alignment. The expressiveness, soundness and completeness of the frameworks are proven. We construct three benchmarks on problem-solving: FormalMath500, a formalization of a subset of the MATH500 benchmark; MiniF2F-Solving and PutnamBench-Solving, adaptations of FTP benchmarks MiniF2F and PutnamBench. For faithful, interpretable, and human-aligned evaluation, we propose RPE (Restricted Propositional Equivalence), a symbolic approach to determine the correctness of answers by formal verification. We evaluate four prevalent FTP models and two prompting methods as baselines, solving at most 23.77% of FormalMath500, 27.47% of MiniF2F-Solving, and 0.31% of PutnamBench-Solving.
TrustGeoGen: Scalable and Formal-Verified Data Engine for Trustworthy Multi-modal Geometric Problem Solving
Apr 22, 2025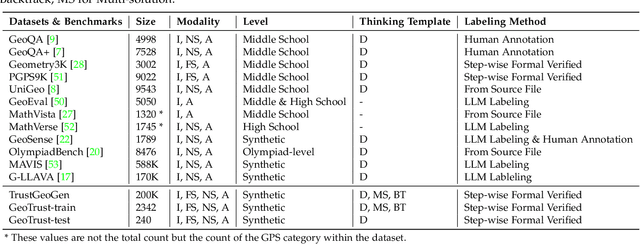
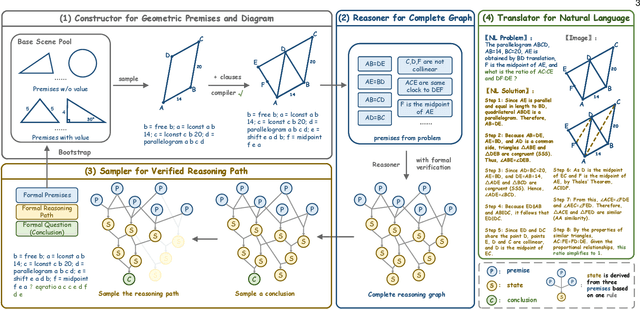
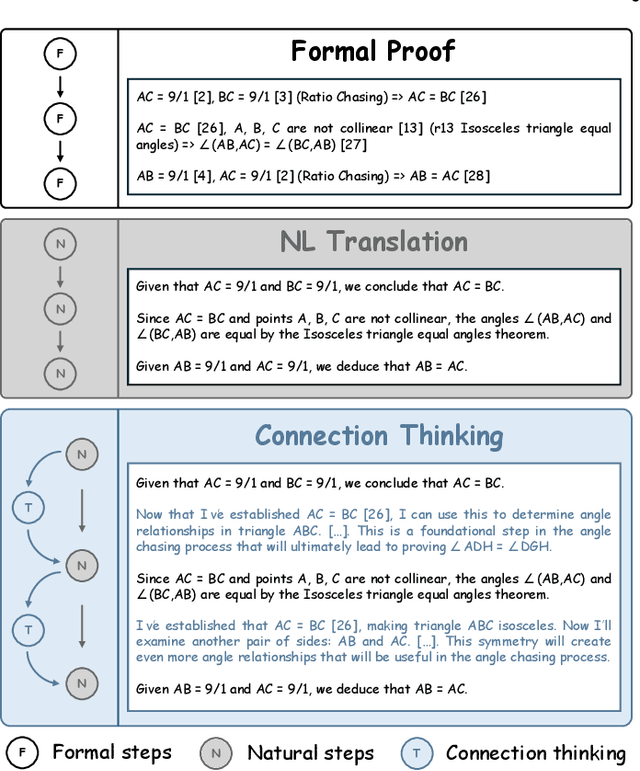
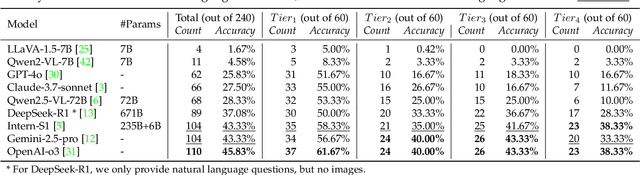
Mathematical geometric problem solving (GPS) often requires effective integration of multimodal information and verifiable logical coherence. Despite the fast development of large language models in general problem solving, it remains unresolved regarding with both methodology and benchmarks, especially given the fact that exiting synthetic GPS benchmarks are often not self-verified and contain noise and self-contradicted information due to the illusion of LLMs. In this paper, we propose a scalable data engine called TrustGeoGen for problem generation, with formal verification to provide a principled benchmark, which we believe lays the foundation for the further development of methods for GPS. The engine synthesizes geometric data through four key innovations: 1) multimodal-aligned generation of diagrams, textual descriptions, and stepwise solutions; 2) formal verification ensuring rule-compliant reasoning paths; 3) a bootstrapping mechanism enabling complexity escalation via recursive state generation and 4) our devised GeoExplore series algorithms simultaneously produce multi-solution variants and self-reflective backtracking traces. By formal logical verification, TrustGeoGen produces GeoTrust-200K dataset with guaranteed modality integrity, along with GeoTrust-test testset. Experiments reveal the state-of-the-art models achieve only 49.17\% accuracy on GeoTrust-test, demonstrating its evaluation stringency. Crucially, models trained on GeoTrust achieve OOD generalization on GeoQA, significantly reducing logical inconsistencies relative to pseudo-label annotated by OpenAI-o1. Our code is available at https://github.com/Alpha-Innovator/TrustGeoGen
SurveyForge: On the Outline Heuristics, Memory-Driven Generation, and Multi-dimensional Evaluation for Automated Survey Writing
Mar 06, 2025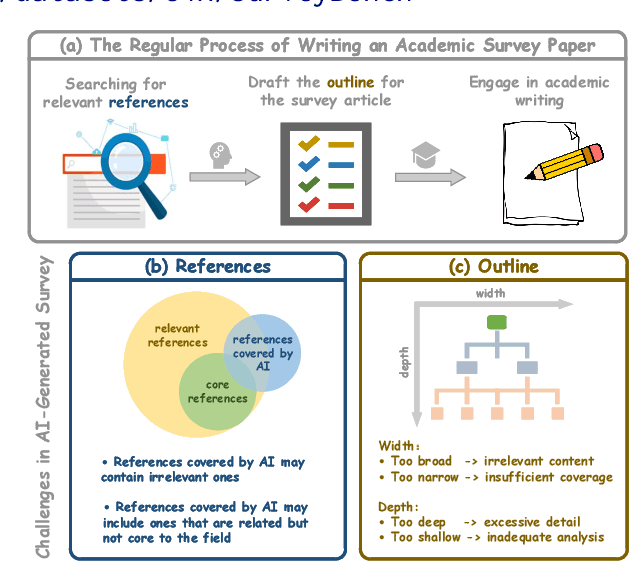



Survey paper plays a crucial role in scientific research, especially given the rapid growth of research publications. Recently, researchers have begun using LLMs to automate survey generation for better efficiency. However, the quality gap between LLM-generated surveys and those written by human remains significant, particularly in terms of outline quality and citation accuracy. To close these gaps, we introduce SurveyForge, which first generates the outline by analyzing the logical structure of human-written outlines and referring to the retrieved domain-related articles. Subsequently, leveraging high-quality papers retrieved from memory by our scholar navigation agent, SurveyForge can automatically generate and refine the content of the generated article. Moreover, to achieve a comprehensive evaluation, we construct SurveyBench, which includes 100 human-written survey papers for win-rate comparison and assesses AI-generated survey papers across three dimensions: reference, outline, and content quality. Experiments demonstrate that SurveyForge can outperform previous works such as AutoSurvey.
GeoX: Geometric Problem Solving Through Unified Formalized Vision-Language Pre-training
Dec 16, 2024



Despite their proficiency in general tasks, Multi-modal Large Language Models (MLLMs) struggle with automatic Geometry Problem Solving (GPS), which demands understanding diagrams, interpreting symbols, and performing complex reasoning. This limitation arises from their pre-training on natural images and texts, along with the lack of automated verification in the problem-solving process. Besides, current geometric specialists are limited by their task-specific designs, making them less effective for broader geometric problems. To this end, we present GeoX, a multi-modal large model focusing on geometric understanding and reasoning tasks. Given the significant differences between geometric diagram-symbol and natural image-text, we introduce unimodal pre-training to develop a diagram encoder and symbol decoder, enhancing the understanding of geometric images and corpora. Furthermore, we introduce geometry-language alignment, an effective pre-training paradigm that bridges the modality gap between unimodal geometric experts. We propose a Generator-And-Sampler Transformer (GS-Former) to generate discriminative queries and eliminate uninformative representations from unevenly distributed geometric signals. Finally, GeoX benefits from visual instruction tuning, empowering it to take geometric images and questions as input and generate verifiable solutions. Experiments show that GeoX outperforms both generalists and geometric specialists on publicly recognized benchmarks, such as GeoQA, UniGeo, Geometry3K, and PGPS9k.
Chimera: Improving Generalist Model with Domain-Specific Experts
Dec 08, 2024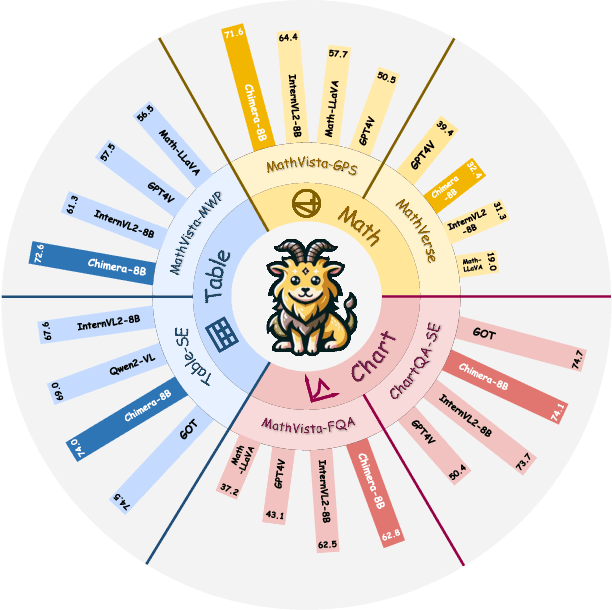
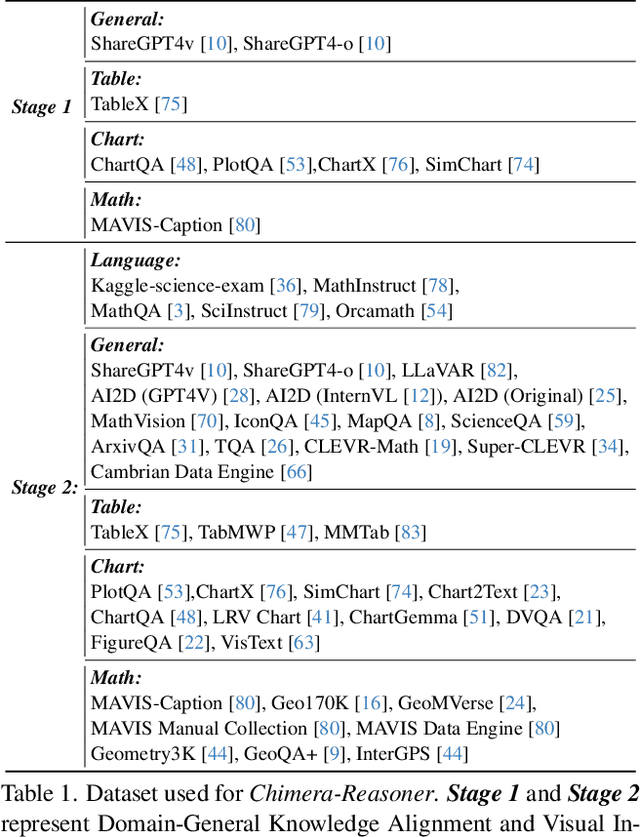
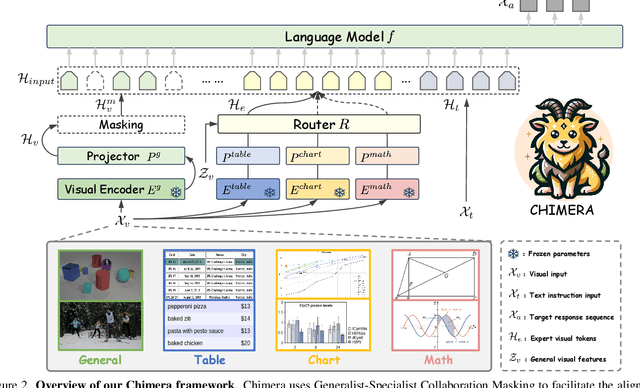
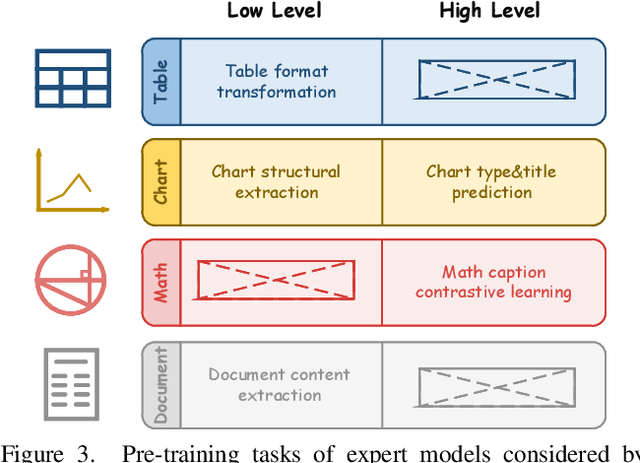
Recent advancements in Large Multi-modal Models (LMMs) underscore the importance of scaling by increasing image-text paired data, achieving impressive performance on general tasks. Despite their effectiveness in broad applications, generalist models are primarily trained on web-scale datasets dominated by natural images, resulting in the sacrifice of specialized capabilities for domain-specific tasks that require extensive domain prior knowledge. Moreover, directly integrating expert models tailored for specific domains is challenging due to the representational gap and imbalanced optimization between the generalist model and experts. To address these challenges, we introduce Chimera, a scalable and low-cost multi-modal pipeline designed to boost the ability of existing LMMs with domain-specific experts. Specifically, we design a progressive training strategy to integrate features from expert models into the input of a generalist LMM. To address the imbalanced optimization caused by the well-aligned general visual encoder, we introduce a novel Generalist-Specialist Collaboration Masking (GSCM) mechanism. This results in a versatile model that excels across the chart, table, math, and document domains, achieving state-of-the-art performance on multi-modal reasoning and visual content extraction tasks, both of which are challenging tasks for assessing existing LMMs.
Training-Free Adaptive Diffusion with Bounded Difference Approximation Strategy
Oct 13, 2024



Diffusion models have recently achieved great success in the synthesis of high-quality images and videos. However, the existing denoising techniques in diffusion models are commonly based on step-by-step noise predictions, which suffers from high computation cost, resulting in a prohibitive latency for interactive applications. In this paper, we propose AdaptiveDiffusion to relieve this bottleneck by adaptively reducing the noise prediction steps during the denoising process. Our method considers the potential of skipping as many noise prediction steps as possible while keeping the final denoised results identical to the original full-step ones. Specifically, the skipping strategy is guided by the third-order latent difference that indicates the stability between timesteps during the denoising process, which benefits the reusing of previous noise prediction results. Extensive experiments on image and video diffusion models demonstrate that our method can significantly speed up the denoising process while generating identical results to the original process, achieving up to an average 2~5x speedup without quality degradation.