 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLM4VLA: Revisiting Vision-Language-Models in Vision-Language-Action Models
Jan 06, 2026Vision-Language-Action (VLA) models, which integrate pretrained large Vision-Language Models (VLM) into their policy backbone, are gaining significant attention for their promising generalization capabilities. This paper revisits a fundamental yet seldom systematically studied question: how VLM choice and competence translate to downstream VLA policies performance? We introduce VLM4VLA, a minimal adaptation pipeline that converts general-purpose VLMs into VLA policies using only a small set of new learnable parameters for fair and efficient comparison. Despite its simplicity, VLM4VLA proves surprisingly competitive with more sophisticated network designs. Through extensive empirical studies on various downstream tasks across three benchmarks, we find that while VLM initialization offers a consistent benefit over training from scratch, a VLM's general capabilities are poor predictors of its downstream task performance. This challenges common assumptions, indicating that standard VLM competence is necessary but insufficient for effective embodied control. We further investigate the impact of specific embodied capabilities by fine-tuning VLMs on seven auxiliary embodied tasks (e.g., embodied QA, visual pointing, depth estimation). Contrary to intuition, improving a VLM's performance on specific embodied skills does not guarantee better downstream control performance. Finally, modality-level ablations identify the visual module in VLM, rather than the language component, as the primary performance bottleneck. We demonstrate that injecting control-relevant supervision into the vision encoder of the VLM yields consistent gains, even when the encoder remains frozen during downstream fine-tuning. This isolates a persistent domain gap between current VLM pretraining objectives and the requirements of embodied action-planning.
GeoX: Geometric Problem Solving Through Unified Formalized Vision-Language Pre-training
Dec 16, 2024



Despite their proficiency in general tasks, Multi-modal Large Language Models (MLLMs) struggle with automatic Geometry Problem Solving (GPS), which demands understanding diagrams, interpreting symbols, and performing complex reasoning. This limitation arises from their pre-training on natural images and texts, along with the lack of automated verification in the problem-solving process. Besides, current geometric specialists are limited by their task-specific designs, making them less effective for broader geometric problems. To this end, we present GeoX, a multi-modal large model focusing on geometric understanding and reasoning tasks. Given the significant differences between geometric diagram-symbol and natural image-text, we introduce unimodal pre-training to develop a diagram encoder and symbol decoder, enhancing the understanding of geometric images and corpora. Furthermore, we introduce geometry-language alignment, an effective pre-training paradigm that bridges the modality gap between unimodal geometric experts. We propose a Generator-And-Sampler Transformer (GS-Former) to generate discriminative queries and eliminate uninformative representations from unevenly distributed geometric signals. Finally, GeoX benefits from visual instruction tuning, empowering it to take geometric images and questions as input and generate verifiable solutions. Experiments show that GeoX outperforms both generalists and geometric specialists on publicly recognized benchmarks, such as GeoQA, UniGeo, Geometry3K, and PGPS9k.
Chimera: Improving Generalist Model with Domain-Specific Experts
Dec 08, 2024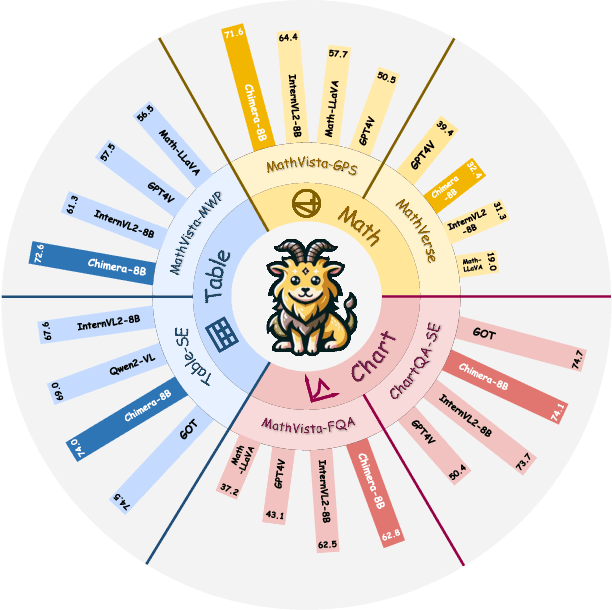
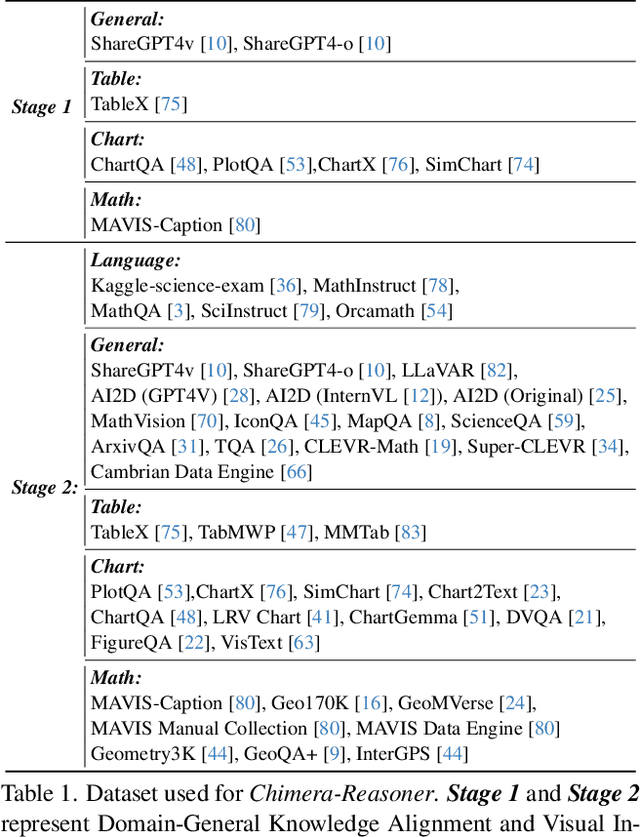
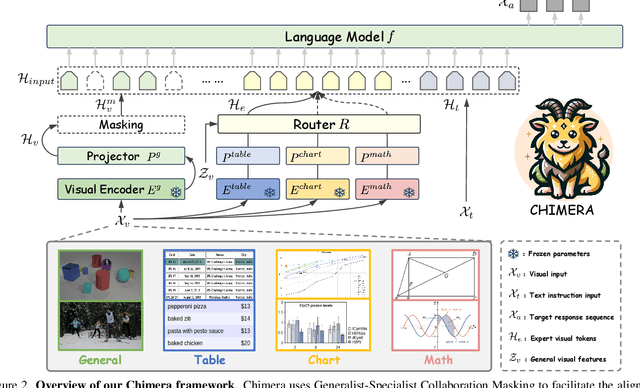
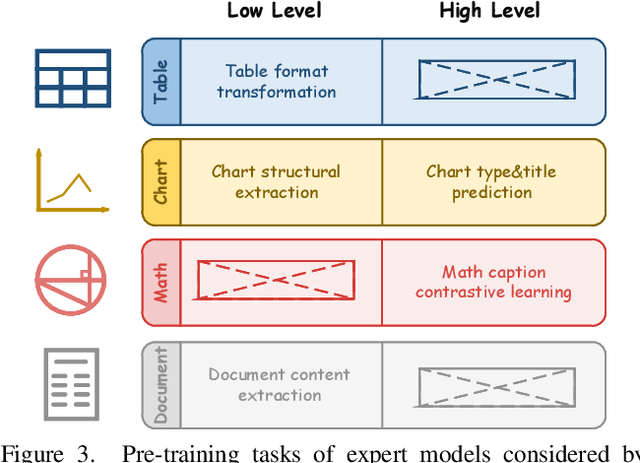
Recent advancements in Large Multi-modal Models (LMMs) underscore the importance of scaling by increasing image-text paired data, achieving impressive performance on general tasks. Despite their effectiveness in broad applications, generalist models are primarily trained on web-scale datasets dominated by natural images, resulting in the sacrifice of specialized capabilities for domain-specific tasks that require extensive domain prior knowledge. Moreover, directly integrating expert models tailored for specific domains is challenging due to the representational gap and imbalanced optimization between the generalist model and experts. To address these challenges, we introduce Chimera, a scalable and low-cost multi-modal pipeline designed to boost the ability of existing LMMs with domain-specific experts. Specifically, we design a progressive training strategy to integrate features from expert models into the input of a generalist LMM. To address the imbalanced optimization caused by the well-aligned general visual encoder, we introduce a novel Generalist-Specialist Collaboration Masking (GSCM) mechanism. This results in a versatile model that excels across the chart, table, math, and document domains, achieving state-of-the-art performance on multi-modal reasoning and visual content extraction tasks, both of which are challenging tasks for assessing existing LMMs.
Lightweight Model Pre-training via Language Guided Knowledge Distillation
Jun 17, 2024



This paper studies the problem of pre-training for small models, which is essential for many mobile devices. Current state-of-the-art methods on this problem transfer the representational knowledge of a large network (as a Teacher) into a smaller model (as a Student) using self-supervised distillation, improving the performance of the small model on downstream tasks. However, existing approaches are insufficient in extracting the crucial knowledge that is useful for discerning categories in downstream tasks during the distillation process. In this paper, for the first time, we introduce language guidance to the distillation process and propose a new method named Language-Guided Distillation (LGD) system, which uses category names of the target downstream task to help refine the knowledge transferred between the teacher and student. To this end, we utilize a pre-trained text encoder to extract semantic embeddings from language and construct a textual semantic space called Textual Semantics Bank (TSB). Furthermore, we design a Language-Guided Knowledge Aggregation (LGKA) module to construct the visual semantic space, also named Visual Semantics Bank (VSB). The task-related knowledge is transferred by driving a student encoder to mimic the similarity score distribution inferred by a teacher over TSB and VSB. Compared with other small models obtained by either ImageNet pre-training or self-supervised distillation, experiment results show that the distilled lightweight model using the proposed LGD method presents state-of-the-art performance and is validated on various downstream tasks, including classification, detection, and segmentation. We have made the code available at https://github.com/mZhenz/LGD.
M3DBench: Let's Instruct Large Models with Multi-modal 3D Prompts
Dec 17, 2023



Recently, 3D understanding has become popular to facilitate autonomous agents to perform further decisionmaking. However, existing 3D datasets and methods are often limited to specific tasks. On the other hand, recent progress in Large Language Models (LLMs) and Multimodal Language Models (MLMs) have demonstrated exceptional general language and imagery tasking performance. Therefore, it is interesting to unlock MLM's potential to be 3D generalist for wider tasks. However, current MLMs' research has been less focused on 3D tasks due to a lack of large-scale 3D instruction-following datasets. In this work, we introduce a comprehensive 3D instructionfollowing dataset called M3DBench, which possesses the following characteristics: 1) It supports general multimodal instructions interleaved with text, images, 3D objects, and other visual prompts. 2) It unifies diverse 3D tasks at both region and scene levels, covering a variety of fundamental abilities in real-world 3D environments. 3) It is a large-scale 3D instruction-following dataset with over 320k instruction-response pairs. Furthermore, we establish a new benchmark for assessing the performance of large models in understanding multi-modal 3D prompts. Extensive experiments demonstrate the effectiveness of our dataset and baseline, supporting general 3D-centric tasks, which can inspire future research.
LL3DA: Visual Interactive Instruction Tuning for Omni-3D Understanding, Reasoning, and Planning
Nov 30, 2023


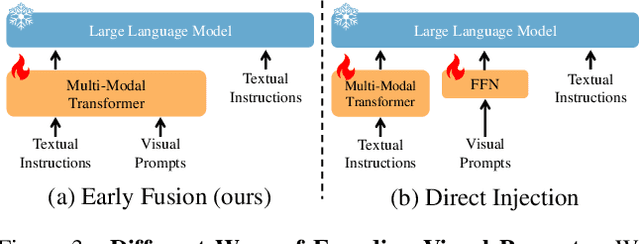
Recent advances in Large Multimodal Models (LMM) have made it possible for various applications in human-machine interactions. However, developing LMMs that can comprehend, reason, and plan in complex and diverse 3D environments remains a challenging topic, especially considering the demand for understanding permutation-invariant point cloud 3D representations of the 3D scene. Existing works seek help from multi-view images, and project 2D features to 3D space as 3D scene representations. This, however, leads to huge computational overhead and performance degradation. In this paper, we present LL3DA, a Large Language 3D Assistant that takes point cloud as direct input and respond to both textual-instructions and visual-prompts. This help LMMs better comprehend human interactions and further help to remove the ambiguities in cluttered 3D scenes. Experiments show that LL3DA achieves remarkable results, and surpasses various 3D vision-language models on both 3D Dense Captioning and 3D Question Answering.
Vote2Cap-DETR++: Decoupling Localization and Describing for End-to-End 3D Dense Captioning
Sep 06, 2023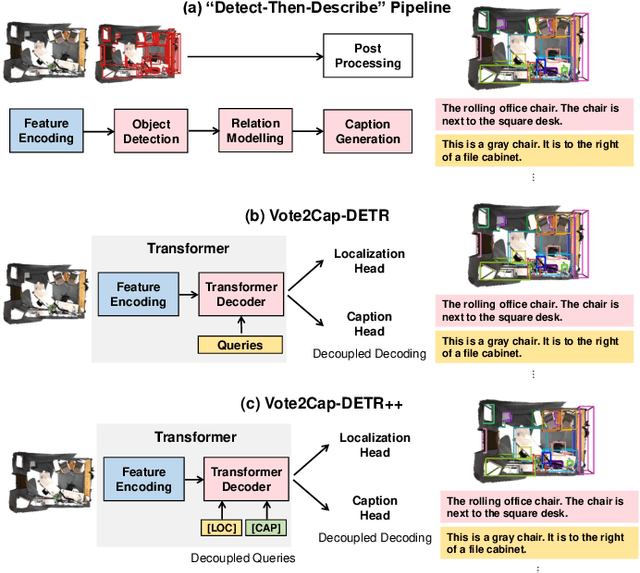
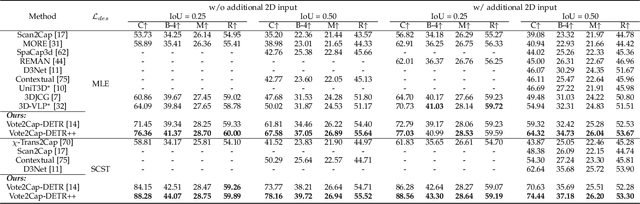
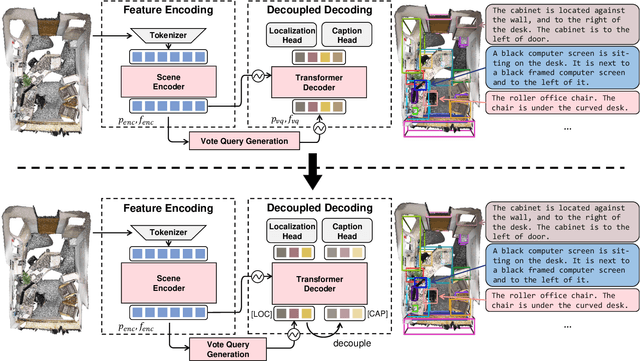
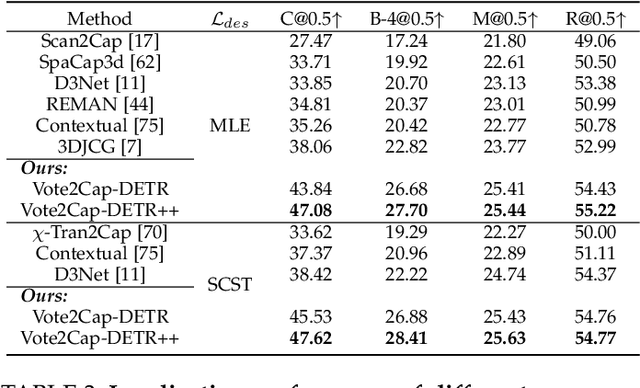
3D dense captioning requires a model to translate its understanding of an input 3D scene into several captions associated with different object regions. Existing methods adopt a sophisticated "detect-then-describe" pipeline, which builds explicit relation modules upon a 3D detector with numerous hand-crafted components. While these methods have achieved initial success, the cascade pipeline tends to accumulate errors because of duplicated and inaccurate box estimations and messy 3D scenes. In this paper, we first propose Vote2Cap-DETR, a simple-yet-effective transformer framework that decouples the decoding process of caption generation and object localization through parallel decoding. Moreover, we argue that object localization and description generation require different levels of scene understanding, which could be challenging for a shared set of queries to capture. To this end, we propose an advanced version, Vote2Cap-DETR++, which decouples the queries into localization and caption queries to capture task-specific features. Additionally, we introduce the iterative spatial refinement strategy to vote queries for faster convergence and better localization performance. We also insert additional spatial information to the caption head for more accurate descriptions. Without bells and whistles, extensive experiments on two commonly used datasets, ScanRefer and Nr3D, demonstrate Vote2Cap-DETR and Vote2Cap-DETR++ surpass conventional "detect-then-describe" methods by a large margin. Codes will be made available at https://github.com/ch3cook-fdu/Vote2Cap-DETR.