 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniCoder: Unified Visual-to-Code Generation via Symbolic Rewards and Reference-Guided Code Optimization
Jun 30, 2026Visual-to-Code generation, which transforms scientific plots, vector graphics, and webpages into executable scripts, demands a level of pixel-precise alignment that standard Multimodal Large Language Models (MLLMs) fail to achieve through Supervised Fine-Tuning (SFT) alone. While Reinforcement Learning (RL) offers a theoretical pathway to bridge this gap, its application is hindered by two fundamental obstacles: (1) \textit{Reward Coarseness}, where semantic metrics like CLIP scores fail to penalize fine-grained element deviations, and (2) \textit{Exploration Stagnation}, where the sparse, heterogeneous code search space prevents the policy from bootstrapping valid trajectories. To overcome these limitations, we introduce UniCoder, a unified RL framework that integrates two novel mechanisms. First, we propose \textbf{Symbolic Attribute Alignment}, which employs a lightweight auxiliary LLM to parse generated code into discrete visual attributes (e.g., hex colors, coordinate limits), enabling dense, element-wise reward computation. Second, to escape local optima, we devise \textbf{Reference-Guided Code Optimization}, a strategy that dynamically injects ground-truth trajectories into low-performing rollout groups, transforming blind exploration into guided policy improvement. Extensive experiments on ChartMimic, UniSVG, Design2Code and ScreenBench benchmarks demonstrate that our 8B-parameter model not only surpasses all open-source baselines but also achieves state-of-the-art performance comparable to proprietary models, establishing a new paradigm for generalized visual-to-code synthesis.
Scaling the Horizon, Not the Parameters: Reaching Trillion-Parameter Performance with a 35B Agent
Jun 29, 2026We introduce Agents-A1, a 35B Mixture-of-Experts Agentic Model that reaches trillion-parameter-level performance by scaling the agent horizon. We investigate agent-horizon scaling from two perspectives: scaling long-horizon trajectories and scaling heterogeneous agent abilities. To support this goal, we build a long-horizon knowledge-action infrastructure that connects external knowledge, actions, observations, and verifier outcomes, producing agentic trajectories with an average length of 45K tokens. Based on this, we train Agents-A1 with a three-stage recipe. First, we perform full-domain supervised fine-tuning to align the base model with broad agentic behaviors. Second, we train domain-level teacher models to capture specialized expertise in each domain. Third, we propose a multi-teacher domain-routed on-policy distillation with salient vocabulary alignment to improve knowledge transfer efficiency across different domains, unifying six heterogeneous domains into one deployable student model. Agents-A1 achieves strong and broad performance for long-horizon agent benchmarks. Compared with 1T-parameter model such as Kimi-K2.6 and DeepSeek-V4-pro, Agents-A1 achieves leading results on SEAL-0 (56.4), IFBench (80.6), HiPhO (46.4), FrontierScience-Olympiad (79.0), and MolBench-Bind (56.8), and remains highly competitive on SciCode (44.3), HLE (47.6) and BrowseComp (75.5). We hope this work provides the community with a practical path for scaling the horizon using a 35B agent that can reach or match the performance of 1T models on long-horizon tasks.
Agents-K1: Towards Agent-native Knowledge Orchestration
Jun 11, 2026Current LLM-based research agents have advanced through agent orchestration, yet largely overlook scientific knowledge orchestration. Existing works often reduce papers to abstracts, surface mentions, and flat \texttt{cites} edges, omitting key entities, claims, evidence, mechanisms, and method lineages essential for scientific reasoning. To this end, we introduce \textbf{Agents-K1}, an end-to-end knowledge orchestration pipeline that converts raw documents into agent-native scientific knowledge graphs. Agents-K1 integrates three components under a unifying theoretical foundation: a multimodal parser whose five-module schema captures entities, multimodal evidence, citations, and typed inter-entity relations across the full paper rather than abstracts alone; a 4B information-extraction backbone trained with GRPO under a rule-based reward; and a graphanything CLI, a tri-source agent interface that unifies web search, multimodal graph retrieval, and cross-document traversal. On top of this, we process 2.46 million scientific papers across six subjects to produce \textbf{Scholar-KG}, of which we release a one-million-paper subset, and the full Scholar-KG is accessible via the SCP link below. The same pipeline can be extended to general-domain corpora and to schema-conformant data synthesis. Extensive experiments demonstrate that Agents-K1 achieves superior performance in scientific information extraction, knowledge graph construction, and multi-hop scientific reasoning.
MLEvolve: A Self-Evolving Framework for Automated Machine Learning Algorithm Discovery
Jun 04, 2026Large language model (LLM) agents are increasingly applied to long-horizon tasks such as scientific discovery and machine learning engineering (MLE), where sustained self-evolution becomes a key capability. However, existing MLE agents suffer from inter-branch information isolation, memoryless search, and lack of hierarchical control, which together hinder long-horizon optimization. We present MLEvolve, an LLM-based self-evolving multi-agent framework for end-to-end machine learning algorithm discovery. By extending tree search to Progressive MCGS, MLEvolve enables cross-branch information flow through graph-based reference edges and gradually shifts the search from broad exploration to focused exploitation with an entropy-inspired progressive schedule. To allow the agent to evolve with accumulated experience, we introduce Retrospective Memory, which combines a cold-start domain knowledge base with a dynamic global memory for task-specific experience retrieval and reuse. For stable long-horizon iteration, we further decouple strategic planning from code generation with adaptive coding modes. Evaluation on MLE-Bench shows that MLEvolve achieves state-of-the-art performance across multiple dimensions including average medal rate and valid submission rate under a 12-hour budget (half the standard runtime). Moreover, MLEvolve also outperforms specialized algorithm discovery methods including AlphaEvolve on mathematical algorithm optimization tasks, demonstrating strong cross-domain generalization. Our code is available at https://github.com/InternScience/MLEvolve.
Intern-S1-Pro: Scientific Multimodal Foundation Model at Trillion Scale
Mar 26, 2026We introduce Intern-S1-Pro, the first one-trillion-parameter scientific multimodal foundation model. Scaling to this unprecedented size, the model delivers a comprehensive enhancement across both general and scientific domains. Beyond stronger reasoning and image-text understanding capabilities, its intelligence is augmented with advanced agent capabilities. Simultaneously, its scientific expertise has been vastly expanded to master over 100 specialized tasks across critical science fields, including chemistry, materials, life sciences, and earth sciences. Achieving this massive scale is made possible by the robust infrastructure support of XTuner and LMDeploy, which facilitates highly efficient Reinforcement Learning (RL) training at the 1-trillion parameter level while ensuring strict precision consistency between training and inference. By seamlessly integrating these advancements, Intern-S1-Pro further fortifies the fusion of general and specialized intelligence, working as a Specializable Generalist, demonstrating its position in the top tier of open-source models for general capabilities, while outperforming proprietary models in the depth of specialized scientific tasks.
InternAgent-1.5: A Unified Agentic Framework for Long-Horizon Autonomous Scientific Discovery
Feb 09, 2026We introduce InternAgent-1.5, a unified system designed for end-to-end scientific discovery across computational and empirical domains. The system is built on a structured architecture composed of three coordinated subsystems for generation, verification, and evolution. These subsystems are supported by foundational capabilities for deep research, solution optimization, and long horizon memory. The architecture allows InternAgent-1.5 to operate continuously across extended discovery cycles while maintaining coherent and improving behavior. It also enables the system to coordinate computational modeling and laboratory experimentation within a single unified system. We evaluate InternAgent-1.5 on scientific reasoning benchmarks such as GAIA, HLE, GPQA, and FrontierScience, and the system achieves leading performance that demonstrates strong foundational capabilities. Beyond these benchmarks, we further assess two categories of discovery tasks. In algorithm discovery tasks, InternAgent-1.5 autonomously designs competitive methods for core machine learning problems. In empirical discovery tasks, it executes complete computational or wet lab experiments and produces scientific findings in earth, life, biological, and physical domains. Overall, these results show that InternAgent-1.5 provides a general and scalable framework for autonomous scientific discovery.
Exploring Reasoning Reward Model for Agents
Jan 29, 2026Agentic Reinforcement Learning (Agentic RL) has achieved notable success in enabling agents to perform complex reasoning and tool use. However, most methods still relies on sparse outcome-based reward for training. Such feedback fails to differentiate intermediate reasoning quality, leading to suboptimal training results. In this paper, we introduce Agent Reasoning Reward Model (Agent-RRM), a multi-faceted reward model that produces structured feedback for agentic trajectories, including (1) an explicit reasoning trace , (2) a focused critique that provides refinement guidance by highlighting reasoning flaws, and (3) an overall score that evaluates process performance. Leveraging these signals, we systematically investigate three integration strategies: Reagent-C (text-augmented refinement), Reagent-R (reward-augmented guidance), and Reagent-U (unified feedback integration). Extensive evaluations across 12 diverse benchmarks demonstrate that Reagent-U yields substantial performance leaps, achieving 43.7% on GAIA and 46.2% on WebWalkerQA, validating the effectiveness of our reasoning reward model and training schemes. Code, models, and datasets are all released to facilitate future research.
MME-Reasoning: A Comprehensive Benchmark for Logical Reasoning in MLLMs
May 27, 2025Logical reasoning is a fundamental aspect of human intelligence and an essential capability for multimodal large language models (MLLMs). Despite the significant advancement in multimodal reasoning, existing benchmarks fail to comprehensively evaluate their reasoning abilities due to the lack of explicit categorization for logical reasoning types and an unclear understanding of reasoning. To address these issues, we introduce MME-Reasoning, a comprehensive benchmark designed to evaluate the reasoning ability of MLLMs, which covers all three types of reasoning (i.e., inductive, deductive, and abductive) in its questions. We carefully curate the data to ensure that each question effectively evaluates reasoning ability rather than perceptual skills or knowledge breadth, and extend the evaluation protocols to cover the evaluation of diverse questions. Our evaluation reveals substantial limitations of state-of-the-art MLLMs when subjected to holistic assessments of logical reasoning capabilities. Even the most advanced MLLMs show limited performance in comprehensive logical reasoning, with notable performance imbalances across reasoning types. In addition, we conducted an in-depth analysis of approaches such as ``thinking mode'' and Rule-based RL, which are commonly believed to enhance reasoning abilities. These findings highlight the critical limitations and performance imbalances of current MLLMs in diverse logical reasoning scenarios, providing comprehensive and systematic insights into the understanding and evaluation of reasoning capabilities.
NovelSeek: When Agent Becomes the Scientist -- Building Closed-Loop System from Hypothesis to Verification
May 22, 2025
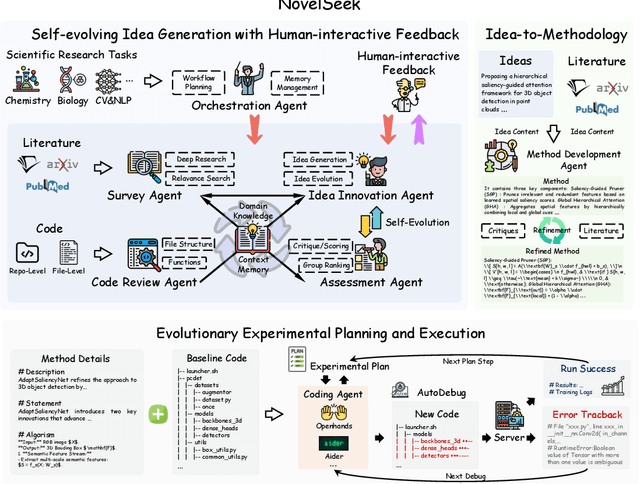

Artificial Intelligence (AI) is accelerating the transformation of scientific research paradigms, not only enhancing research efficiency but also driving innovation. We introduce NovelSeek, a unified closed-loop multi-agent framework to conduct Autonomous Scientific Research (ASR) across various scientific research fields, enabling researchers to tackle complicated problems in these fields with unprecedented speed and precision. NovelSeek highlights three key advantages: 1) Scalability: NovelSeek has demonstrated its versatility across 12 scientific research tasks, capable of generating innovative ideas to enhance the performance of baseline code. 2) Interactivity: NovelSeek provides an interface for human expert feedback and multi-agent interaction in automated end-to-end processes, allowing for the seamless integration of domain expert knowledge. 3) Efficiency: NovelSeek has achieved promising performance gains in several scientific fields with significantly less time cost compared to human efforts. For instance, in reaction yield prediction, it increased from 27.6% to 35.4% in just 12 hours; in enhancer activity prediction, accuracy rose from 0.52 to 0.79 with only 4 hours of processing; and in 2D semantic segmentation, precision advanced from 78.8% to 81.0% in a mere 30 hours.
Video-R1: Reinforcing Video Reasoning in MLLMs
Mar 27, 2025



Inspired by DeepSeek-R1's success in eliciting reasoning abilities through rule-based reinforcement learning (RL), we introduce Video-R1 as the first attempt to systematically explore the R1 paradigm for eliciting video reasoning within multimodal large language models (MLLMs). However, directly applying RL training with the GRPO algorithm to video reasoning presents two primary challenges: (i) a lack of temporal modeling for video reasoning, and (ii) the scarcity of high-quality video-reasoning data. To address these issues, we first propose the T-GRPO algorithm, which encourages models to utilize temporal information in videos for reasoning. Additionally, instead of relying solely on video data, we incorporate high-quality image-reasoning data into the training process. We have constructed two datasets: Video-R1-COT-165k for SFT cold start and Video-R1-260k for RL training, both comprising image and video data. Experimental results demonstrate that Video-R1 achieves significant improvements on video reasoning benchmarks such as VideoMMMU and VSI-Bench, as well as on general video benchmarks including MVBench and TempCompass, etc. Notably, Video-R1-7B attains a 35.8% accuracy on video spatial reasoning benchmark VSI-bench, surpassing the commercial proprietary model GPT-4o. All codes, models, data are released.