 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZEUS: Accelerating Diffusion Models with Only Second-Order Predictor
Apr 02, 2026Denoising generative models deliver high-fidelity generation but remain bottlenecked by inference latency due to the many iterative denoiser calls required during sampling. Training-free acceleration methods reduce latency by either sparsifying the model architecture or shortening the sampling trajectory. Current training-free acceleration methods are more complex than necessary: higher-order predictors amplify error under aggressive speedups, and architectural modifications hinder deployment. Beyond 2x acceleration, step skipping creates structural scarcity -- at most one fresh evaluation per local window -- leaving the computed output and its backward difference as the only causally grounded information. Based on this, we propose ZEUS, an acceleration method that predicts reduced denoiser evaluations using a second-order predictor, and stabilizes aggressive consecutive skipping with an interleaved scheme that avoids back-to-back extrapolations. ZEUS adds essentially zero overhead, no feature caches, and no architectural modifications, and it is compatible with different backbones, prediction objectives, and solver choices. Across image and video generation, ZEUS consistently improves the speed-fidelity performance over recent training-free baselines, achieving up to 3.2x end-to-end speedup while maintaining perceptual quality. Our code is available at: https://github.com/Ting-Justin-Jiang/ZEUS.
T2S-Bench & Structure-of-Thought: Benchmarking and Prompting Comprehensive Text-to-Structure Reasoning
Mar 04, 2026Think about how human handles complex reading tasks: marking key points, inferring their relationships, and structuring information to guide understanding and responses. Likewise, can a large language model benefit from text structure to enhance text-processing performance? To explore it, in this work, we first introduce Structure of Thought (SoT), a prompting technique that explicitly guides models to construct intermediate text structures, consistently boosting performance across eight tasks and three model families. Building upon this insight, we present T2S-Bench, the first benchmark designed to evaluate and improve text-to-structure capabilities of models. T2S-Bench includes 1.8K samples across 6 scientific domains and 32 structural types, rigorously constructed to ensure accuracy, fairness, and quality. Evaluation on 45 mainstream models reveals substantial improvement potential: the average accuracy on the multi-hop reasoning task is only 52.1%, and even the most advanced model achieves 58.1% node accuracy in end-to-end extraction. Furthermore, on Qwen2.5-7B-Instruct, SoT alone yields an average +5.7% improvement across eight diverse text-processing tasks, and fine-tuning on T2S-Bench further increases this gain to +8.6%. These results highlight the value of explicit text structuring and the complementary contributions of SoT and T2S-Bench. Dataset and eval code have been released at https://t2s-bench.github.io/T2S-Bench-Page/.
PrivAct: Internalizing Contextual Privacy Preservation via Multi-Agent Preference Training
Feb 14, 2026Large language model (LLM) agents are increasingly deployed in personalized tasks involving sensitive, context-dependent information, where privacy violations may arise in agents' action due to the implicitness of contextual privacy. Existing approaches rely on external, inference-time interventions which are brittle, scenario-specific, and may expand the privacy attack surface. We propose PrivAct, a contextual privacy-aware multi-agent learning framework that internalizes contextual privacy preservation directly into models' generation behavior for privacy-compliant agentic actions. By embedding privacy preferences into each agent, PrivAct enhances system-wide contextual integrity while achieving a more favorable privacy-helpfulness tradeoff. Experiments across multiple LLM backbones and benchmarks demonstrate consistent improvements in contextual privacy preservation, reducing leakage rates by up to 12.32% while maintaining comparable helpfulness, as well as zero-shot generalization and robustness across diverse multi-agent topologies. Code is available at https://github.com/chengyh23/PrivAct.
FractalCloud: A Fractal-Inspired Architecture for Efficient Large-Scale Point Cloud Processing
Nov 10, 2025Three-dimensional (3D) point clouds are increasingly used in applications such as autonomous driving, robotics, and virtual reality (VR). Point-based neural networks (PNNs) have demonstrated strong performance in point cloud analysis, originally targeting small-scale inputs. However, as PNNs evolve to process large-scale point clouds with hundreds of thousands of points, all-to-all computation and global memory access in point cloud processing introduce substantial overhead, causing $O(n^2)$ computational complexity and memory traffic where n is the number of points}. Existing accelerators, primarily optimized for small-scale workloads, overlook this challenge and scale poorly due to inefficient partitioning and non-parallel architectures. To address these issues, we propose FractalCloud, a fractal-inspired hardware architecture for efficient large-scale 3D point cloud processing. FractalCloud introduces two key optimizations: (1) a co-designed Fractal method for shape-aware and hardware-friendly partitioning, and (2) block-parallel point operations that decompose and parallelize all point operations. A dedicated hardware design with on-chip fractal and flexible parallelism further enables fully parallel processing within limited memory resources. Implemented in 28 nm technology as a chip layout with a core area of 1.5 $mm^2$, FractalCloud achieves 21.7x speedup and 27x energy reduction over state-of-the-art accelerators while maintaining network accuracy, demonstrating its scalability and efficiency for PNN inference.
SADA: Stability-guided Adaptive Diffusion Acceleration
Jul 23, 2025Diffusion models have achieved remarkable success in generative tasks but suffer from high computational costs due to their iterative sampling process and quadratic attention costs. Existing training-free acceleration strategies that reduce per-step computation cost, while effectively reducing sampling time, demonstrate low faithfulness compared to the original baseline. We hypothesize that this fidelity gap arises because (a) different prompts correspond to varying denoising trajectory, and (b) such methods do not consider the underlying ODE formulation and its numerical solution. In this paper, we propose Stability-guided Adaptive Diffusion Acceleration (SADA), a novel paradigm that unifies step-wise and token-wise sparsity decisions via a single stability criterion to accelerate sampling of ODE-based generative models (Diffusion and Flow-matching). For (a), SADA adaptively allocates sparsity based on the sampling trajectory. For (b), SADA introduces principled approximation schemes that leverage the precise gradient information from the numerical ODE solver. Comprehensive evaluations on SD-2, SDXL, and Flux using both EDM and DPM++ solvers reveal consistent $\ge 1.8\times$ speedups with minimal fidelity degradation (LPIPS $\leq 0.10$ and FID $\leq 4.5$) compared to unmodified baselines, significantly outperforming prior methods. Moreover, SADA adapts seamlessly to other pipelines and modalities: It accelerates ControlNet without any modifications and speeds up MusicLDM by $1.8\times$ with $\sim 0.01$ spectrogram LPIPS.
CoreMatching: A Co-adaptive Sparse Inference Framework with Token and Neuron Pruning for Comprehensive Acceleration of Vision-Language Models
May 25, 2025Vision-Language Models (VLMs) excel across diverse tasks but suffer from high inference costs in time and memory. Token sparsity mitigates inefficiencies in token usage, while neuron sparsity reduces high-dimensional computations, both offering promising solutions to enhance efficiency. Recently, these two sparsity paradigms have evolved largely in parallel, fostering the prevailing assumption that they function independently. However, a fundamental yet underexplored question remains: Do they truly operate in isolation, or is there a deeper underlying interplay that has yet to be uncovered? In this paper, we conduct the first comprehensive investigation into this question. By introducing and analyzing the matching mechanism between Core Neurons and Core Tokens, we found that key neurons and tokens for inference mutually influence and reinforce each other. Building on this insight, we propose CoreMatching, a co-adaptive sparse inference framework, which leverages the synergy between token and neuron sparsity to enhance inference efficiency. Through theoretical analysis and efficiency evaluations, we demonstrate that the proposed method surpasses state-of-the-art baselines on ten image understanding tasks and three hardware devices. Notably, on the NVIDIA Titan Xp, it achieved 5x FLOPs reduction and a 10x overall speedup. Code is released at https://github.com/wangqinsi1/2025-ICML-CoreMatching/tree/main.
HippoMM: Hippocampal-inspired Multimodal Memory for Long Audiovisual Event Understanding
Apr 14, 2025Comprehending extended audiovisual experiences remains a fundamental challenge for computational systems. Current approaches struggle with temporal integration and cross-modal associations that humans accomplish effortlessly through hippocampal-cortical networks. We introduce HippoMM, a biologically-inspired architecture that transforms hippocampal mechanisms into computational advantages for multimodal understanding. HippoMM implements three key innovations: (i) hippocampus-inspired pattern separation and completion specifically designed for continuous audiovisual streams, (ii) short-to-long term memory consolidation that transforms perceptual details into semantic abstractions, and (iii) cross-modal associative retrieval pathways enabling modality-crossing queries. Unlike existing retrieval systems with static indexing schemes, HippoMM dynamically forms integrated episodic representations through adaptive temporal segmentation and dual-process memory encoding. Evaluations on our challenging HippoVlog benchmark demonstrate that HippoMM significantly outperforms state-of-the-art approaches (78.2% vs. 64.2% accuracy) while providing substantially faster response times (20.4s vs. 112.5s). Our results demonstrate that translating neuroscientific memory principles into computational architectures provides a promising foundation for next-generation multimodal understanding systems. The code and benchmark dataset are publicly available at https://github.com/linyueqian/HippoMM.
GeoX: Geometric Problem Solving Through Unified Formalized Vision-Language Pre-training
Dec 16, 2024



Despite their proficiency in general tasks, Multi-modal Large Language Models (MLLMs) struggle with automatic Geometry Problem Solving (GPS), which demands understanding diagrams, interpreting symbols, and performing complex reasoning. This limitation arises from their pre-training on natural images and texts, along with the lack of automated verification in the problem-solving process. Besides, current geometric specialists are limited by their task-specific designs, making them less effective for broader geometric problems. To this end, we present GeoX, a multi-modal large model focusing on geometric understanding and reasoning tasks. Given the significant differences between geometric diagram-symbol and natural image-text, we introduce unimodal pre-training to develop a diagram encoder and symbol decoder, enhancing the understanding of geometric images and corpora. Furthermore, we introduce geometry-language alignment, an effective pre-training paradigm that bridges the modality gap between unimodal geometric experts. We propose a Generator-And-Sampler Transformer (GS-Former) to generate discriminative queries and eliminate uninformative representations from unevenly distributed geometric signals. Finally, GeoX benefits from visual instruction tuning, empowering it to take geometric images and questions as input and generate verifiable solutions. Experiments show that GeoX outperforms both generalists and geometric specialists on publicly recognized benchmarks, such as GeoQA, UniGeo, Geometry3K, and PGPS9k.
CoreInfer: Accelerating Large Language Model Inference with Semantics-Inspired Adaptive Sparse Activation
Oct 23, 2024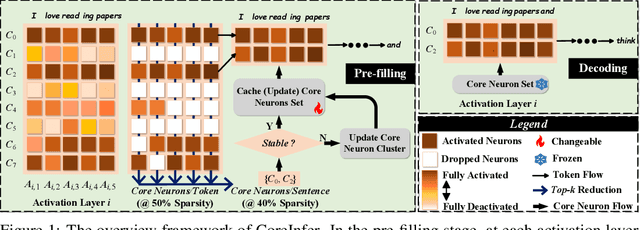

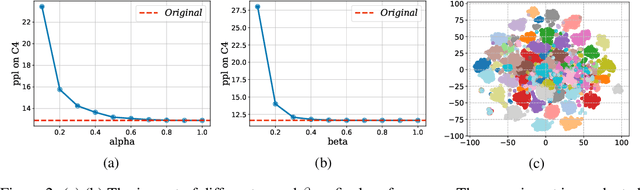

Large language models (LLMs) with billions of parameters have sparked a new wave of exciting AI applications. However, their high computational costs and memory demands during inference pose significant challenges. Adaptive sparse activation inference, which activates only a small number of neurons for each token, offers a novel way to accelerate model inference without degrading performance, showing great potential for resource-constrained hardware devices. Nevertheless, existing methods predict activated neurons based on individual tokens with additional MLP, which involve frequent changes in activation maps and resource calls, limiting the acceleration benefits of sparse activation. In this paper, we introduce CoreInfer, an MLP-free adaptive sparse activation inference method based on sentence-level prediction. Specifically, we propose the concept of sentence-wise core neurons, which refers to the subset of neurons most critical for a given sentence, and empirically demonstrate its effectiveness. To determine the core neurons, we explore the correlation between core neurons and the sentence's semantics. Remarkably, we discovered that core neurons exhibit both stability and similarity in relation to the sentence's semantics -- an insight overlooked by previous studies. Building on this finding, we further design two semantic-based methods for predicting core neurons to fit different input scenarios. In CoreInfer, the core neurons are determined during the pre-filling stage and fixed during the encoding stage, enabling zero-cost sparse inference. We evaluated the model generalization and task generalization of CoreInfer across various models and tasks. Notably, on an NVIDIA TITAN XP GPU, CoreInfer achieved a 10.33 times and 2.72 times speedup compared to the Huggingface implementation and PowerInfer, respectively.
Training-Free Adaptive Diffusion with Bounded Difference Approximation Strategy
Oct 13, 2024



Diffusion models have recently achieved great success in the synthesis of high-quality images and videos. However, the existing denoising techniques in diffusion models are commonly based on step-by-step noise predictions, which suffers from high computation cost, resulting in a prohibitive latency for interactive applications. In this paper, we propose AdaptiveDiffusion to relieve this bottleneck by adaptively reducing the noise prediction steps during the denoising process. Our method considers the potential of skipping as many noise prediction steps as possible while keeping the final denoised results identical to the original full-step ones. Specifically, the skipping strategy is guided by the third-order latent difference that indicates the stability between timesteps during the denoising process, which benefits the reusing of previous noise prediction results. Extensive experiments on image and video diffusion models demonstrate that our method can significantly speed up the denoising process while generating identical results to the original process, achieving up to an average 2~5x speedup without quality degradation.