 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEEA: Mere Exposure Effect-Driven Confrontational Optimization for LLM Jailbreaking
Dec 21, 2025The rapid advancement of large language models (LLMs) has intensified concerns about the robustness of their safety alignment. While existing jailbreak studies explore both single-turn and multi-turn strategies, most implicitly assume a static safety boundary and fail to account for how contextual interactions dynamically influence model behavior, leading to limited stability and generalization. Motivated by this gap, we propose MEEA (Mere Exposure Effect Attack), a psychology-inspired, fully automated black-box framework for evaluating multi-turn safety robustness, grounded in the mere exposure effect. MEEA leverages repeated low-toxicity semantic exposure to induce a gradual shift in a model's effective safety threshold, enabling progressive erosion of alignment constraints over sustained interactions. Concretely, MEEA constructs semantically progressive prompt chains and optimizes them using a simulated annealing strategy guided by semantic similarity, toxicity, and jailbreak effectiveness. Extensive experiments on both closed-source and open-source models, including GPT-4, Claude-3.5, and DeepSeek-R1, demonstrate that MEEA consistently achieves higher attack success rates than seven representative baselines, with an average Attack Success Rate (ASR) improvement exceeding 20%. Ablation studies further validate the necessity of both annealing-based optimization and contextual exposure mechanisms. Beyond improved attack effectiveness, our findings indicate that LLM safety behavior is inherently dynamic and history-dependent, challenging the common assumption of static alignment boundaries and highlighting the need for interaction-aware safety evaluation and defense mechanisms. Our code is available at: https://github.com/Carney-lsz/MEEA
CAPTURE: A Benchmark and Evaluation for LVLMs in CAPTCHA Resolving
Dec 12, 2025Benefiting from strong and efficient multi-modal alignment strategies, Large Visual Language Models (LVLMs) are able to simulate human visual and reasoning capabilities, such as solving CAPTCHAs. However, existing benchmarks based on visual CAPTCHAs still face limitations. Previous studies, when designing benchmarks and datasets, customized them according to their research objectives. Consequently, these benchmarks cannot comprehensively cover all CAPTCHA types. Notably, there is a dearth of dedicated benchmarks for LVLMs. To address this problem, we introduce a novel CAPTCHA benchmark for the first time, named CAPTURE CAPTCHA for Testing Under Real-world Experiments, specifically for LVLMs. Our benchmark encompasses 4 main CAPTCHA types and 25 sub-types from 31 vendors. The diversity enables a multi-dimensional and thorough evaluation of LVLM performance. CAPTURE features extensive class variety, large-scale data, and unique LVLM-tailored labels, filling the gaps in previous research in terms of data comprehensiveness and labeling pertinence. When evaluated by this benchmark, current LVLMs demonstrate poor performance in solving CAPTCHAs.
Oedipus and the Sphinx: Benchmarking and Improving Visual Language Models for Complex Graphic Reasoning
Aug 01, 2025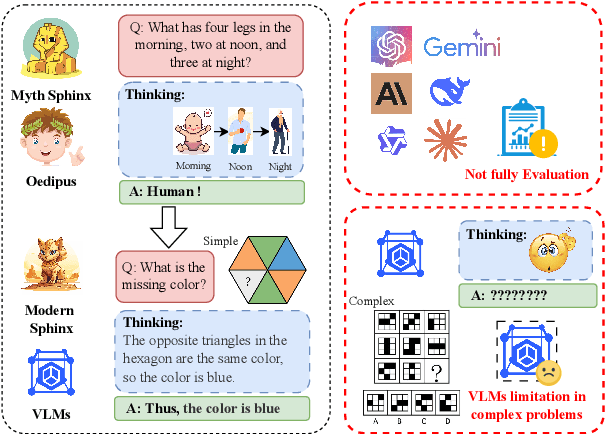
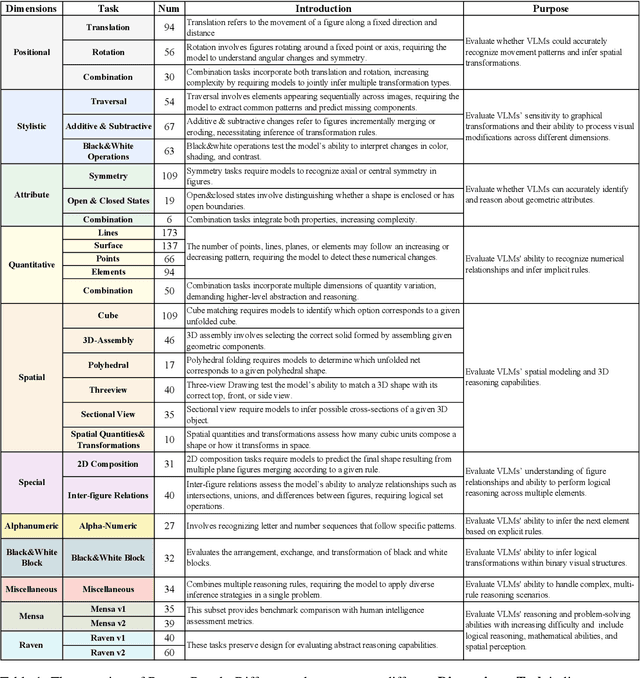
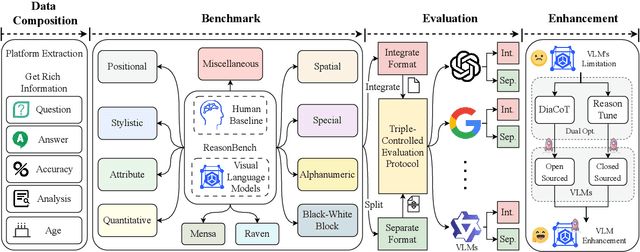
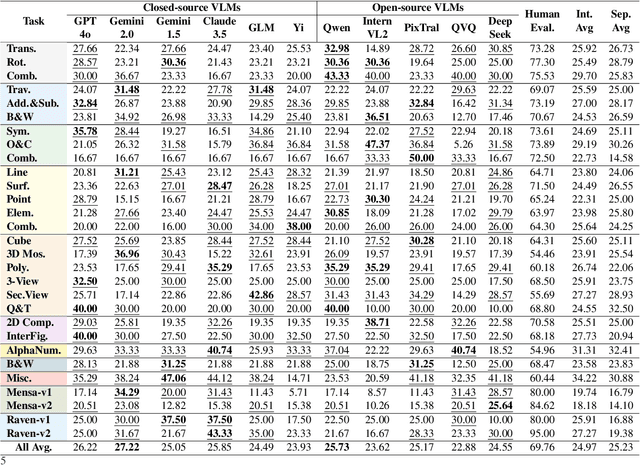
Evaluating the performance of visual language models (VLMs) in graphic reasoning tasks has become an important research topic. However, VLMs still show obvious deficiencies in simulating human-level graphic reasoning capabilities, especially in complex graphic reasoning and abstract problem solving, which are less studied and existing studies only focus on simple graphics. To evaluate the performance of VLMs in complex graphic reasoning, we propose ReasonBench, the first evaluation benchmark focused on structured graphic reasoning tasks, which includes 1,613 questions from real-world intelligence tests. ReasonBench covers reasoning dimensions related to location, attribute, quantity, and multi-element tasks, providing a comprehensive evaluation of the performance of VLMs in spatial, relational, and abstract reasoning capabilities. We benchmark 11 mainstream VLMs (including closed-source and open-source models) and reveal significant limitations of current models. Based on these findings, we propose a dual optimization strategy: Diagrammatic Reasoning Chain (DiaCoT) enhances the interpretability of reasoning by decomposing layers, and ReasonTune enhances the task adaptability of model reasoning through training, all of which improves VLM performance by 33.5\%. All experimental data and code are in the repository: https://huggingface.co/datasets/cistine/ReasonBench.
SADA: Stability-guided Adaptive Diffusion Acceleration
Jul 23, 2025Diffusion models have achieved remarkable success in generative tasks but suffer from high computational costs due to their iterative sampling process and quadratic attention costs. Existing training-free acceleration strategies that reduce per-step computation cost, while effectively reducing sampling time, demonstrate low faithfulness compared to the original baseline. We hypothesize that this fidelity gap arises because (a) different prompts correspond to varying denoising trajectory, and (b) such methods do not consider the underlying ODE formulation and its numerical solution. In this paper, we propose Stability-guided Adaptive Diffusion Acceleration (SADA), a novel paradigm that unifies step-wise and token-wise sparsity decisions via a single stability criterion to accelerate sampling of ODE-based generative models (Diffusion and Flow-matching). For (a), SADA adaptively allocates sparsity based on the sampling trajectory. For (b), SADA introduces principled approximation schemes that leverage the precise gradient information from the numerical ODE solver. Comprehensive evaluations on SD-2, SDXL, and Flux using both EDM and DPM++ solvers reveal consistent $\ge 1.8\times$ speedups with minimal fidelity degradation (LPIPS $\leq 0.10$ and FID $\leq 4.5$) compared to unmodified baselines, significantly outperforming prior methods. Moreover, SADA adapts seamlessly to other pipelines and modalities: It accelerates ControlNet without any modifications and speeds up MusicLDM by $1.8\times$ with $\sim 0.01$ spectrogram LPIPS.
CoreMatching: A Co-adaptive Sparse Inference Framework with Token and Neuron Pruning for Comprehensive Acceleration of Vision-Language Models
May 25, 2025Vision-Language Models (VLMs) excel across diverse tasks but suffer from high inference costs in time and memory. Token sparsity mitigates inefficiencies in token usage, while neuron sparsity reduces high-dimensional computations, both offering promising solutions to enhance efficiency. Recently, these two sparsity paradigms have evolved largely in parallel, fostering the prevailing assumption that they function independently. However, a fundamental yet underexplored question remains: Do they truly operate in isolation, or is there a deeper underlying interplay that has yet to be uncovered? In this paper, we conduct the first comprehensive investigation into this question. By introducing and analyzing the matching mechanism between Core Neurons and Core Tokens, we found that key neurons and tokens for inference mutually influence and reinforce each other. Building on this insight, we propose CoreMatching, a co-adaptive sparse inference framework, which leverages the synergy between token and neuron sparsity to enhance inference efficiency. Through theoretical analysis and efficiency evaluations, we demonstrate that the proposed method surpasses state-of-the-art baselines on ten image understanding tasks and three hardware devices. Notably, on the NVIDIA Titan Xp, it achieved 5x FLOPs reduction and a 10x overall speedup. Code is released at https://github.com/wangqinsi1/2025-ICML-CoreMatching/tree/main.
FL-PLAS: Federated Learning with Partial Layer Aggregation for Backdoor Defense Against High-Ratio Malicious Clients
May 17, 2025Federated learning (FL) is gaining increasing attention as an emerging collaborative machine learning approach, particularly in the context of large-scale computing and data systems. However, the fundamental algorithm of FL, Federated Averaging (FedAvg), is susceptible to backdoor attacks. Although researchers have proposed numerous defense algorithms, two significant challenges remain. The attack is becoming more stealthy and harder to detect, and current defense methods are unable to handle 50\% or more malicious users or assume an auxiliary server dataset. To address these challenges, we propose a novel defense algorithm, FL-PLAS, \textbf{F}ederated \textbf{L}earning based on \textbf{P}artial\textbf{ L}ayer \textbf{A}ggregation \textbf{S}trategy. In particular, we divide the local model into a feature extractor and a classifier. In each iteration, the clients only upload the parameters of a feature extractor after local training. The server then aggregates these local parameters and returns the results to the clients. Each client retains its own classifier layer, ensuring that the backdoor labels do not impact other clients. We assess the effectiveness of FL-PLAS against state-of-the-art (SOTA) backdoor attacks on three image datasets and compare our approach to six defense strategies. The results of the experiment demonstrate that our methods can effectively protect local models from backdoor attacks. Without requiring any auxiliary dataset for the server, our method achieves a high main-task accuracy with a lower backdoor accuracy even under the condition of 90\% malicious users with the attacks of trigger, semantic and edge-case.
Keyframe-oriented Vision Token Pruning: Enhancing Efficiency of Large Vision Language Models on Long-Form Video Processing
Mar 13, 2025Vision language models (VLMs) demonstrate strong capabilities in jointly processing visual and textual data. However, they often incur substantial computational overhead due to redundant visual information, particularly in long-form video scenarios. Existing approaches predominantly focus on either vision token pruning, which may overlook spatio-temporal dependencies, or keyframe selection, which identifies informative frames but discards others, thus disrupting contextual continuity. In this work, we propose KVTP (Keyframe-oriented Vision Token Pruning), a novel framework that overcomes the drawbacks of token pruning and keyframe selection. By adaptively assigning pruning rates based on frame relevance to the query, KVTP effectively retains essential contextual information while significantly reducing redundant computation. To thoroughly evaluate the long-form video understanding capacities of VLMs, we curated and reorganized subsets from VideoMME, EgoSchema, and NextQA into a unified benchmark named SparseKV-QA that highlights real-world scenarios with sparse but crucial events. Our experiments with VLMs of various scales show that KVTP can reduce token usage by 80% without compromising spatiotemporal and contextual consistency, significantly cutting computation while maintaining the performance. These results demonstrate our approach's effectiveness in efficient long-video processing, facilitating more scalable VLM deployment.
Proactive Privacy Amnesia for Large Language Models: Safeguarding PII with Negligible Impact on Model Utility
Feb 24, 2025With the rise of large language models (LLMs), increasing research has recognized their risk of leaking personally identifiable information (PII) under malicious attacks. Although efforts have been made to protect PII in LLMs, existing methods struggle to balance privacy protection with maintaining model utility. In this paper, inspired by studies of amnesia in cognitive science, we propose a novel approach, Proactive Privacy Amnesia (PPA), to safeguard PII in LLMs while preserving their utility. This mechanism works by actively identifying and forgetting key memories most closely associated with PII in sequences, followed by a memory implanting using suitable substitute memories to maintain the LLM's functionality. We conduct evaluations across multiple models to protect common PII, such as phone numbers and physical addresses, against prevalent PII-targeted attacks, demonstrating the superiority of our method compared with other existing defensive techniques. The results show that our PPA method completely eliminates the risk of phone number exposure by 100% and significantly reduces the risk of physical address exposure by 9.8% - 87.6%, all while maintaining comparable model utility performance.
H-CoT: Hijacking the Chain-of-Thought Safety Reasoning Mechanism to Jailbreak Large Reasoning Models, Including OpenAI o1/o3, DeepSeek-R1, and Gemini 2.0 Flash Thinking
Feb 18, 2025



Large Reasoning Models (LRMs) have recently extended their powerful reasoning capabilities to safety checks-using chain-of-thought reasoning to decide whether a request should be answered. While this new approach offers a promising route for balancing model utility and safety, its robustness remains underexplored. To address this gap, we introduce Malicious-Educator, a benchmark that disguises extremely dangerous or malicious requests beneath seemingly legitimate educational prompts. Our experiments reveal severe security flaws in popular commercial-grade LRMs, including OpenAI o1/o3, DeepSeek-R1, and Gemini 2.0 Flash Thinking. For instance, although OpenAI's o1 model initially maintains a high refusal rate of about 98%, subsequent model updates significantly compromise its safety; and attackers can easily extract criminal strategies from DeepSeek-R1 and Gemini 2.0 Flash Thinking without any additional tricks. To further highlight these vulnerabilities, we propose Hijacking Chain-of-Thought (H-CoT), a universal and transferable attack method that leverages the model's own displayed intermediate reasoning to jailbreak its safety reasoning mechanism. Under H-CoT, refusal rates sharply decline-dropping from 98% to below 2%-and, in some instances, even transform initially cautious tones into ones that are willing to provide harmful content. We hope these findings underscore the urgent need for more robust safety mechanisms to preserve the benefits of advanced reasoning capabilities without compromising ethical standards.
SpeechPrune: Context-aware Token Pruning for Speech Information Retrieval
Dec 16, 2024We introduce Speech Information Retrieval (SIR), a new long-context task for Speech Large Language Models (Speech LLMs), and present SPIRAL, a 1,012-sample benchmark testing models' ability to extract critical details from approximately 90-second spoken inputs. While current Speech LLMs excel at short-form tasks, they struggle with the computational and representational demands of longer audio sequences. To address this limitation, we propose SpeechPrune, a training-free token pruning strategy that uses speech-text similarity and approximated attention scores to efficiently discard irrelevant tokens. In SPIRAL, SpeechPrune achieves accuracy improvements of 29% and up to 47% over the original model and the random pruning model at a pruning rate of 20%, respectively. SpeechPrune can maintain network performance even at a pruning level of 80%. This approach highlights the potential of token-level pruning for efficient and scalable long-form speech understanding.