 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinTrace: Holistic Trajectory-Level Evaluation of LLM Tool Calling for Long-Horizon Financial Tasks
Apr 11, 2026Recent studies demonstrate that tool-calling capability enables large language models (LLMs) to interact with external environments for long-horizon financial tasks. While existing benchmarks have begun evaluating financial tool calling, they focus on limited scenarios and rely on call-level metrics that fail to capture trajectory-level reasoning quality. To address this gap, we introduce FinTrace, a benchmark comprising 800 expert-annotated trajectories spanning 34 real-world financial task categories across multiple difficulty levels. FinTrace employs a rubric-based evaluation protocol with nine metrics organized along four axes -- action correctness, execution efficiency, process quality, and output quality -- enabling fine-grained assessment of LLM tool-calling behavior. Our evaluation of 13 LLMs reveals that while frontier models achieve strong tool selection, all models struggle with information utilization and final answer quality, exposing a critical gap between invoking the right tools and reasoning effectively over their outputs. To move beyond diagnosis, we construct FinTrace-Training, the first trajectory-level preference dataset for financial tool-calling, containing 8,196 curated trajectories with tool-augmented contexts and preference pairs. We fine-tune Qwen-3.5-9B using supervised fine-tuning followed by direct preference optimization (DPO) and show that training on FinTrace-Training consistently improves intermediate reasoning metrics, with DPO more effectively suppressing failure modes. However, end-to-end answer quality remains a bottleneck, indicating that trajectory-level improvements do not yet fully propagate to final output quality.
Adaptive Data Augmentation with Multi-armed Bandit: Sample-Efficient Embedding Calibration for Implicit Pattern Recognition
Feb 22, 2026Recognizing implicit visual and textual patterns is essential in many real-world applications of modern AI. However, tackling long-tail pattern recognition tasks remains challenging for current pre-trained foundation models such as LLMs and VLMs. While finetuning pre-trained models can improve accuracy in recognizing implicit patterns, it is usually infeasible due to a lack of training data and high computational overhead. In this paper, we propose ADAMAB, an efficient embedding calibration framework for few-shot pattern recognition. To maximally reduce the computational costs, ADAMAB trains embedder-agnostic light-weight calibrators on top of fixed embedding models without accessing their parameters. To mitigate the need for large-scale training data, we introduce an adaptive data augmentation strategy based on the Multi-Armed Bandit (MAB) mechanism. With a modified upper confidence bound algorithm, ADAMAB diminishes the gradient shifting and offers theoretically guaranteed convergence in few-shot training. Our multi-modal experiments justify the superior performance of ADAMAB, with up to 40% accuracy improvement when training with less than 5 initial data samples of each class.
Proactive Privacy Amnesia for Large Language Models: Safeguarding PII with Negligible Impact on Model Utility
Feb 24, 2025With the rise of large language models (LLMs), increasing research has recognized their risk of leaking personally identifiable information (PII) under malicious attacks. Although efforts have been made to protect PII in LLMs, existing methods struggle to balance privacy protection with maintaining model utility. In this paper, inspired by studies of amnesia in cognitive science, we propose a novel approach, Proactive Privacy Amnesia (PPA), to safeguard PII in LLMs while preserving their utility. This mechanism works by actively identifying and forgetting key memories most closely associated with PII in sequences, followed by a memory implanting using suitable substitute memories to maintain the LLM's functionality. We conduct evaluations across multiple models to protect common PII, such as phone numbers and physical addresses, against prevalent PII-targeted attacks, demonstrating the superiority of our method compared with other existing defensive techniques. The results show that our PPA method completely eliminates the risk of phone number exposure by 100% and significantly reduces the risk of physical address exposure by 9.8% - 87.6%, all while maintaining comparable model utility performance.
FedProphet: Memory-Efficient Federated Adversarial Training via Theoretic-Robustness and Low-Inconsistency Cascade Learning
Sep 12, 2024



Federated Learning (FL) provides a strong privacy guarantee by enabling local training across edge devices without training data sharing, and Federated Adversarial Training (FAT) further enhances the robustness against adversarial examples, promoting a step toward trustworthy artificial intelligence. However, FAT requires a large model to preserve high accuracy while achieving strong robustness, and it is impractically slow when directly training with memory-constrained edge devices due to the memory-swapping latency. Moreover, existing memory-efficient FL methods suffer from poor accuracy and weak robustness in FAT because of inconsistent local and global models, i.e., objective inconsistency. In this paper, we propose FedProphet, a novel FAT framework that can achieve memory efficiency, adversarial robustness, and objective consistency simultaneously. FedProphet partitions the large model into small cascaded modules such that the memory-constrained devices can conduct adversarial training module-by-module. A strong convexity regularization is derived to theoretically guarantee the robustness of the whole model, and we show that the strong robustness implies low objective inconsistency in FedProphet. We also develop a training coordinator on the server of FL, with Adaptive Perturbation Adjustment for utility-robustness balance and Differentiated Module Assignment for objective inconsistency mitigation. FedProphet empirically shows a significant improvement in both accuracy and robustness compared to previous memory-efficient methods, achieving almost the same performance of end-to-end FAT with 80% memory reduction and up to 10.8x speedup in training time.
Fed-CBS: A Heterogeneity-Aware Client Sampling Mechanism for Federated Learning via Class-Imbalance Reduction
Sep 30, 2022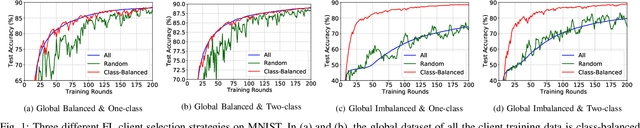
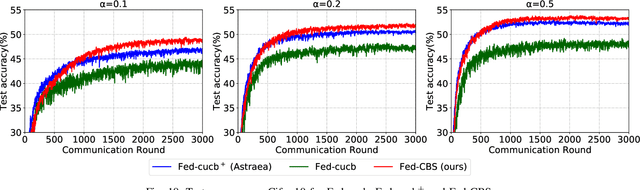
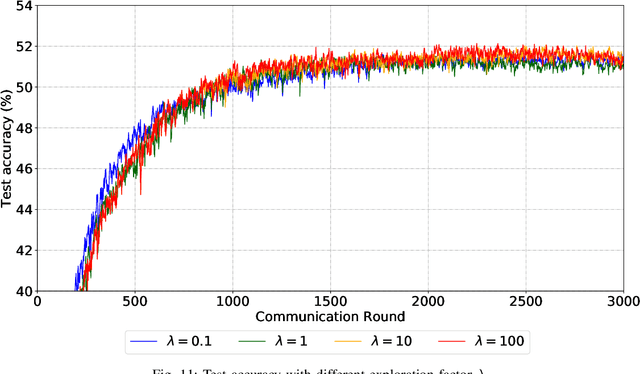
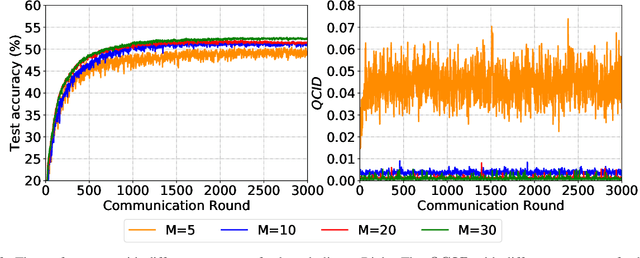
Due to limited communication capacities of edge devices, most existing federated learning (FL) methods randomly select only a subset of devices to participate in training for each communication round. Compared with engaging all the available clients, the random-selection mechanism can lead to significant performance degradation on non-IID (independent and identically distributed) data. In this paper, we show our key observation that the essential reason resulting in such performance degradation is the class-imbalance of the grouped data from randomly selected clients. Based on our key observation, we design an efficient heterogeneity-aware client sampling mechanism, i.e., Federated Class-balanced Sampling (Fed-CBS), which can effectively reduce class-imbalance of the group dataset from the intentionally selected clients. In particular, we propose a measure of class-imbalance and then employ homomorphic encryption to derive this measure in a privacy-preserving way. Based on this measure, we also design a computation-efficient client sampling strategy, such that the actively selected clients will generate a more class-balanced grouped dataset with theoretical guarantees. Extensive experimental results demonstrate Fed-CBS outperforms the status quo approaches. Furthermore, it achieves comparable or even better performance than the ideal setting where all the available clients participate in the FL training.
FADE: Enabling Large-Scale Federated Adversarial Training on Resource-Constrained Edge Devices
Sep 08, 2022
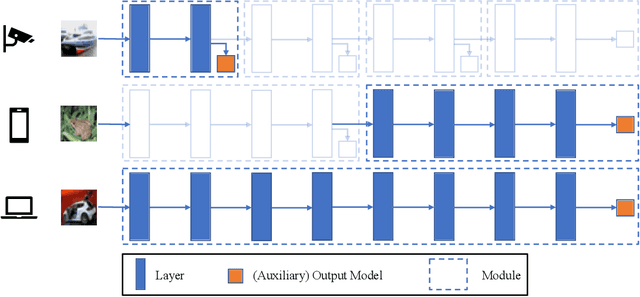
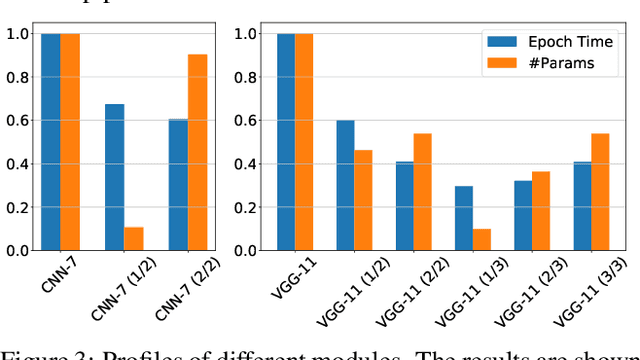
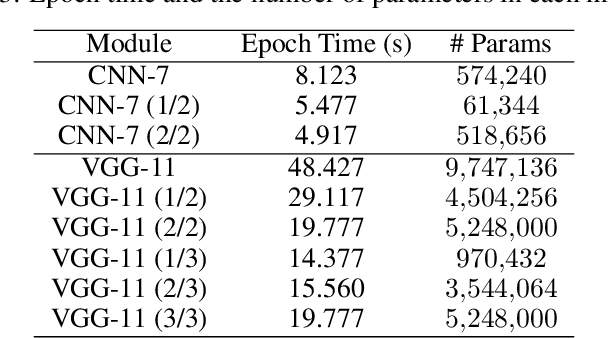
Adversarial Training (AT) has been proven to be an effective method of introducing strong adversarial robustness into deep neural networks. However, the high computational cost of AT prohibits the deployment of large-scale AT on resource-constrained edge devices, e.g., with limited computing power and small memory footprint, in Federated Learning (FL) applications. Very few previous studies have tried to tackle these constraints in FL at the same time. In this paper, we propose a new framework named Federated Adversarial Decoupled Learning (FADE) to enable AT on resource-constrained edge devices in FL. FADE reduces the computation and memory usage by applying Decoupled Greedy Learning (DGL) to federated adversarial training such that each client only needs to perform AT on a small module of the entire model in each communication round. In addition, we improve vanilla DGL by adding an auxiliary weight decay to alleviate objective inconsistency and achieve better performance. FADE offers a theoretical guarantee for the adversarial robustness and convergence. The experimental results also show that FADE can significantly reduce the computing resources consumed by AT while maintaining almost the same accuracy and robustness as fully joint training.
Towards Collaborative Intelligence: Routability Estimation based on Decentralized Private Data
Mar 30, 2022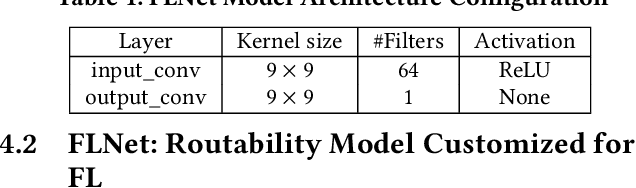
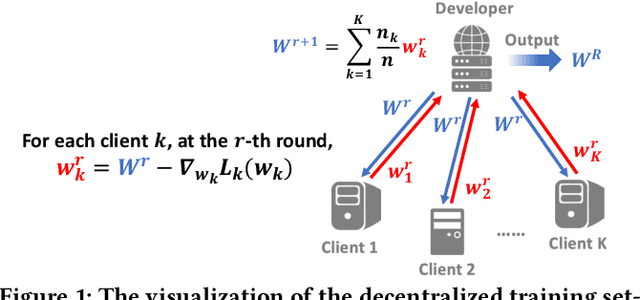
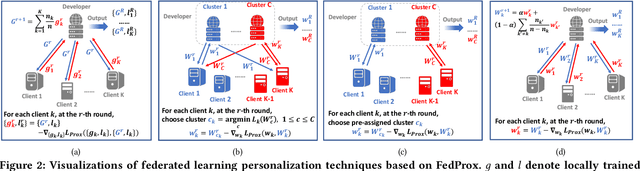
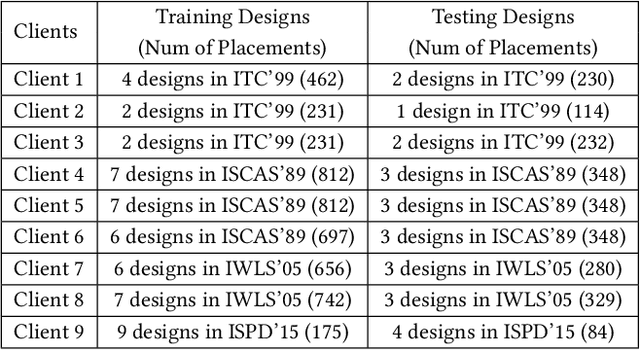
Applying machine learning (ML) in design flow is a popular trend in EDA with various applications from design quality predictions to optimizations. Despite its promise, which has been demonstrated in both academic researches and industrial tools, its effectiveness largely hinges on the availability of a large amount of high-quality training data. In reality, EDA developers have very limited access to the latest design data, which is owned by design companies and mostly confidential. Although one can commission ML model training to a design company, the data of a single company might be still inadequate or biased, especially for small companies. Such data availability problem is becoming the limiting constraint on future growth of ML for chip design. In this work, we propose an Federated-Learning based approach for well-studied ML applications in EDA. Our approach allows an ML model to be collaboratively trained with data from multiple clients but without explicit access to the data for respecting their data privacy. To further strengthen the results, we co-design a customized ML model FLNet and its personalization under the decentralized training scenario. Experiments on a comprehensive dataset show that collaborative training improves accuracy by 11% compared with individual local models, and our customized model FLNet significantly outperforms the best of previous routability estimators in this collaborative training flow.
FedGP: Correlation-Based Active Client Selection for Heterogeneous Federated Learning
Mar 24, 2021

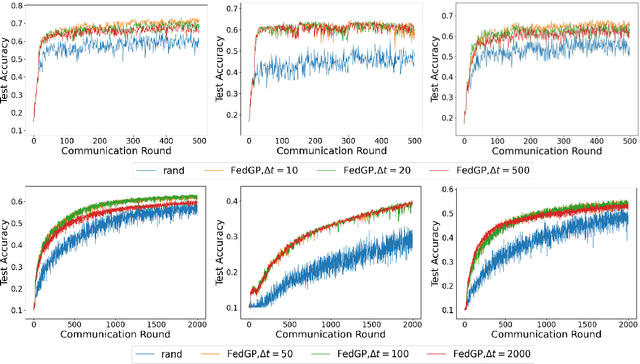
Client-wise heterogeneity is one of the major issues that hinder effective training in federated learning (FL). Since the data distribution on each client may differ dramatically, the client selection strategy can largely influence the convergence rate of the FL process. Several recent studies adopt active client selection strategies. However, they neglect the loss correlations between the clients and achieve marginal improvement compared to the uniform selection strategy. In this work, we propose FedGP -- a federated learning framework built on a correlation-based client selection strategy, to boost the convergence rate of FL. Specifically, we first model the loss correlations between the clients with a Gaussian Process (GP). To make the GP training feasible in the communication-bounded FL process, we develop a GP training method utilizing the historical samples efficiently to reduce the communication cost. Finally, based on the correlations we learned, we derive the client selection with an enlarged reduction of expected global loss in each round. Our experimental results show that compared to the latest active client selection strategy, FedGP can improve the convergence rates by $1.3\sim2.3\times$ and $1.2\sim1.4\times$ on FMNIST and CIFAR-10, respectively.
Learning Low-rank Deep Neural Networks via Singular Vector Orthogonality Regularization and Singular Value Sparsification
Apr 20, 2020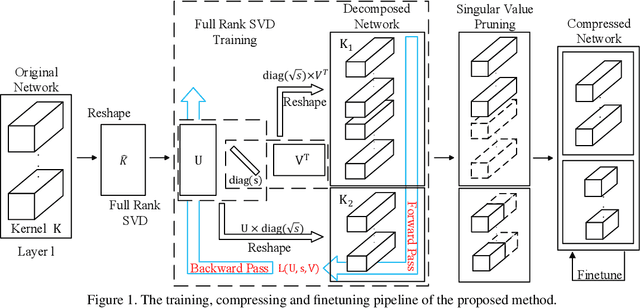
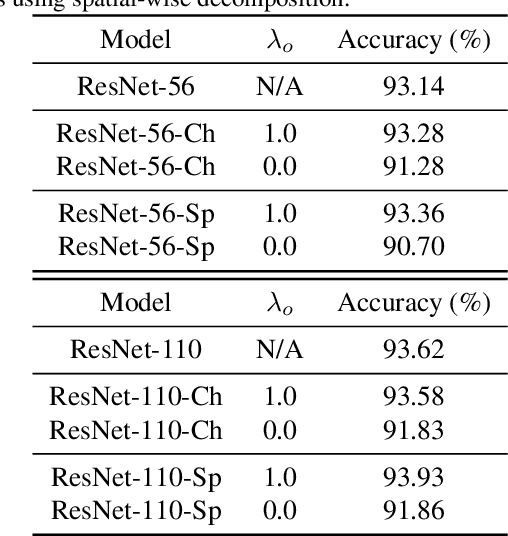
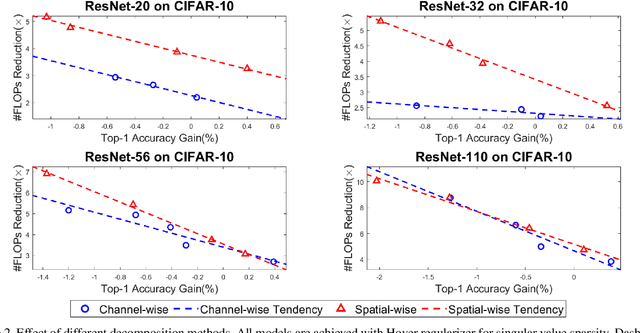
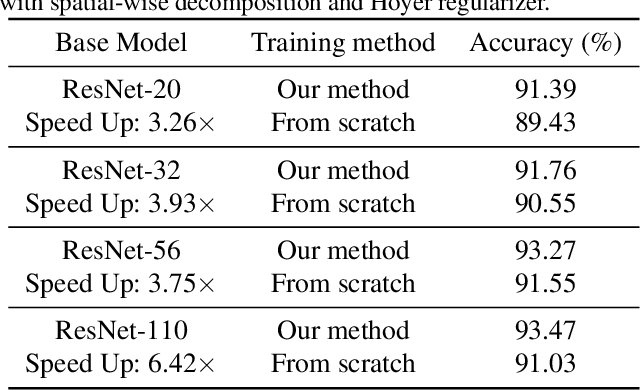
Modern deep neural networks (DNNs) often require high memory consumption and large computational loads. In order to deploy DNN algorithms efficiently on edge or mobile devices, a series of DNN compression algorithms have been explored, including factorization methods. Factorization methods approximate the weight matrix of a DNN layer with the multiplication of two or multiple low-rank matrices. However, it is hard to measure the ranks of DNN layers during the training process. Previous works mainly induce low-rank through implicit approximations or via costly singular value decomposition (SVD) process on every training step. The former approach usually induces a high accuracy loss while the latter has a low efficiency. In this work, we propose SVD training, the first method to explicitly achieve low-rank DNNs during training without applying SVD on every step. SVD training first decomposes each layer into the form of its full-rank SVD, then performs training directly on the decomposed weights. We add orthogonality regularization to the singular vectors, which ensure the valid form of SVD and avoid gradient vanishing/exploding. Low-rank is encouraged by applying sparsity-inducing regularizers on the singular values of each layer. Singular value pruning is applied at the end to explicitly reach a low-rank model. We empirically show that SVD training can significantly reduce the rank of DNN layers and achieve higher reduction on computation load under the same accuracy, comparing to not only previous factorization methods but also state-of-the-art filter pruning methods.
Hierarchical Reinforcement Learning with Advantage-Based Auxiliary Rewards
Oct 10, 2019
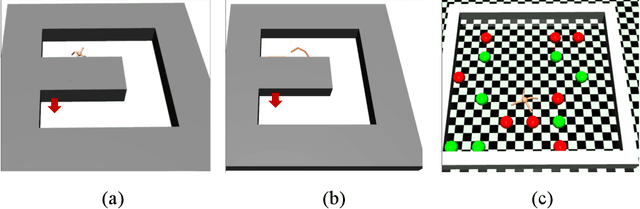
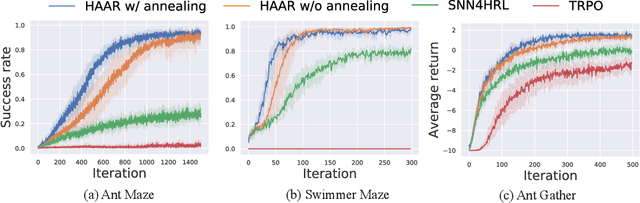

Hierarchical Reinforcement Learning (HRL) is a promising approach to solving long-horizon problems with sparse and delayed rewards. Many existing HRL algorithms either use pre-trained low-level skills that are unadaptable, or require domain-specific information to define low-level rewards. In this paper, we aim to adapt low-level skills to downstream tasks while maintaining the generality of reward design. We propose an HRL framework which sets auxiliary rewards for low-level skill training based on the advantage function of the high-level policy. This auxiliary reward enables efficient, simultaneous learning of the high-level policy and low-level skills without using task-specific knowledge. In addition, we also theoretically prove that optimizing low-level skills with this auxiliary reward will increase the task return for the joint policy. Experimental results show that our algorithm dramatically outperforms other state-of-the-art HRL methods in Mujoco domains. We also find both low-level and high-level policies trained by our algorithm transferable.