 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFed-CBS: A Heterogeneity-Aware Client Sampling Mechanism for Federated Learning via Class-Imbalance Reduction
Paper and Code
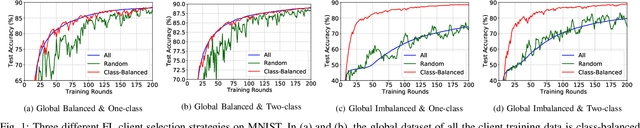
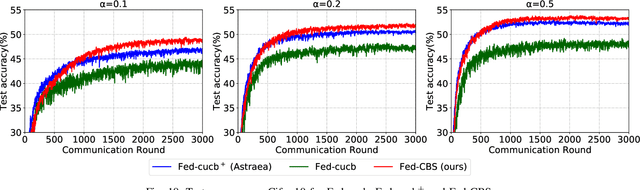
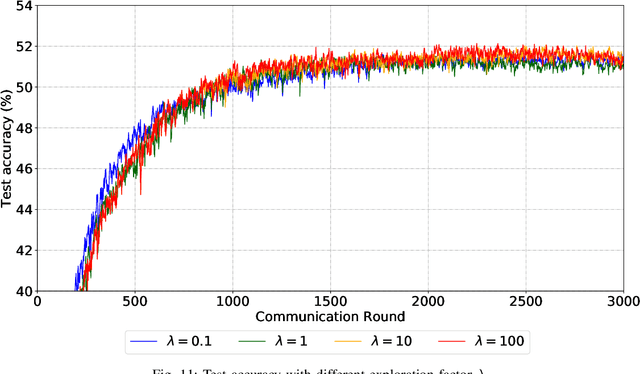
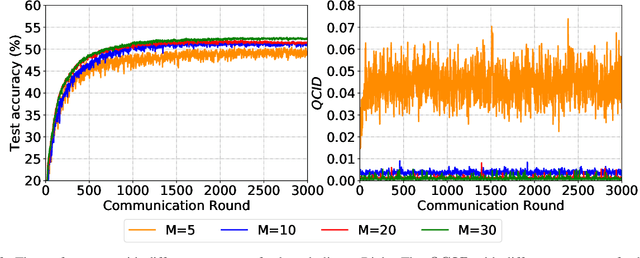
Due to limited communication capacities of edge devices, most existing federated learning (FL) methods randomly select only a subset of devices to participate in training for each communication round. Compared with engaging all the available clients, the random-selection mechanism can lead to significant performance degradation on non-IID (independent and identically distributed) data. In this paper, we show our key observation that the essential reason resulting in such performance degradation is the class-imbalance of the grouped data from randomly selected clients. Based on our key observation, we design an efficient heterogeneity-aware client sampling mechanism, i.e., Federated Class-balanced Sampling (Fed-CBS), which can effectively reduce class-imbalance of the group dataset from the intentionally selected clients. In particular, we propose a measure of class-imbalance and then employ homomorphic encryption to derive this measure in a privacy-preserving way. Based on this measure, we also design a computation-efficient client sampling strategy, such that the actively selected clients will generate a more class-balanced grouped dataset with theoretical guarantees. Extensive experimental results demonstrate Fed-CBS outperforms the status quo approaches. Furthermore, it achieves comparable or even better performance than the ideal setting where all the available clients participate in the FL training.