 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToken Pruning for In-Context Generation in Diffusion Transformers
Feb 02, 2026In-context generation significantly enhances Diffusion Transformers (DiTs) by enabling controllable image-to-image generation through reference examples. However, the resulting input concatenation drastically increases sequence length, creating a substantial computational bottleneck. Existing token reduction techniques, primarily tailored for text-to-image synthesis, fall short in this paradigm as they apply uniform reduction strategies, overlooking the inherent role asymmetry between reference contexts and target latents across spatial, temporal, and functional dimensions. To bridge this gap, we introduce ToPi, a training-free token pruning framework tailored for in-context generation in DiTs. Specifically, ToPi utilizes offline calibration-driven sensitivity analysis to identify pivotal attention layers, serving as a robust proxy for redundancy estimation. Leveraging these layers, we derive a novel influence metric to quantify the contribution of each context token for selective pruning, coupled with a temporal update strategy that adapts to the evolving diffusion trajectory. Empirical evaluations demonstrate that ToPi can achieve over 30\% speedup in inference while maintaining structural fidelity and visual consistency across complex image generation tasks.
LLaViDA: A Large Language Vision Driving Assistant for Explicit Reasoning and Enhanced Trajectory Planning
Dec 20, 2025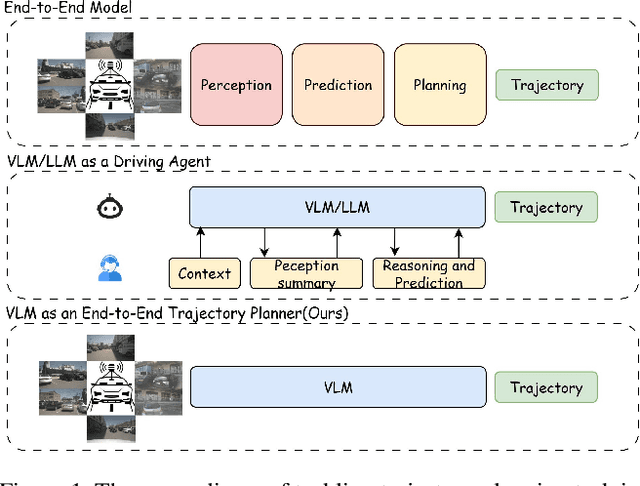
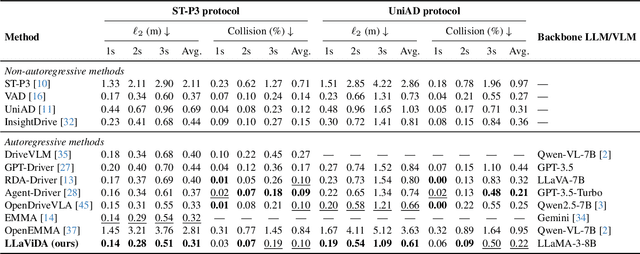
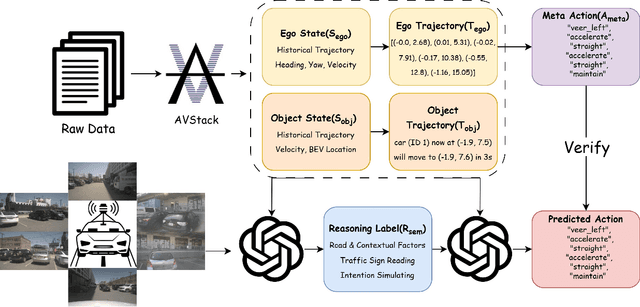
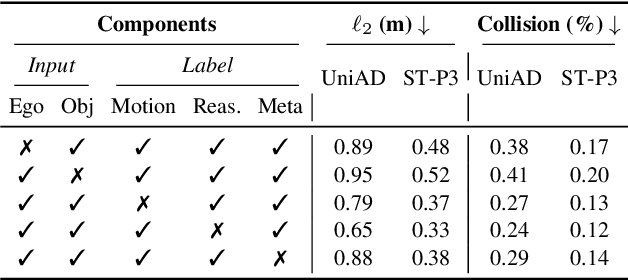
Trajectory planning is a fundamental yet challenging component of autonomous driving. End-to-end planners frequently falter under adverse weather, unpredictable human behavior, or complex road layouts, primarily because they lack strong generalization or few-shot capabilities beyond their training data. We propose LLaViDA, a Large Language Vision Driving Assistant that leverages a Vision-Language Model (VLM) for object motion prediction, semantic grounding, and chain-of-thought reasoning for trajectory planning in autonomous driving. A two-stage training pipeline--supervised fine-tuning followed by Trajectory Preference Optimization (TPO)--enhances scene understanding and trajectory planning by injecting regression-based supervision, produces a powerful "VLM Trajectory Planner for Autonomous Driving." On the NuScenes benchmark, LLaViDA surpasses state-of-the-art end-to-end and other recent VLM/LLM-based baselines in open-loop trajectory planning task, achieving an average L2 trajectory error of 0.31 m and a collision rate of 0.10% on the NuScenes test set. The code for this paper is available at GitHub.
SADA: Stability-guided Adaptive Diffusion Acceleration
Jul 23, 2025Diffusion models have achieved remarkable success in generative tasks but suffer from high computational costs due to their iterative sampling process and quadratic attention costs. Existing training-free acceleration strategies that reduce per-step computation cost, while effectively reducing sampling time, demonstrate low faithfulness compared to the original baseline. We hypothesize that this fidelity gap arises because (a) different prompts correspond to varying denoising trajectory, and (b) such methods do not consider the underlying ODE formulation and its numerical solution. In this paper, we propose Stability-guided Adaptive Diffusion Acceleration (SADA), a novel paradigm that unifies step-wise and token-wise sparsity decisions via a single stability criterion to accelerate sampling of ODE-based generative models (Diffusion and Flow-matching). For (a), SADA adaptively allocates sparsity based on the sampling trajectory. For (b), SADA introduces principled approximation schemes that leverage the precise gradient information from the numerical ODE solver. Comprehensive evaluations on SD-2, SDXL, and Flux using both EDM and DPM++ solvers reveal consistent $\ge 1.8\times$ speedups with minimal fidelity degradation (LPIPS $\leq 0.10$ and FID $\leq 4.5$) compared to unmodified baselines, significantly outperforming prior methods. Moreover, SADA adapts seamlessly to other pipelines and modalities: It accelerates ControlNet without any modifications and speeds up MusicLDM by $1.8\times$ with $\sim 0.01$ spectrogram LPIPS.
Frontier AI Risk Management Framework in Practice: A Risk Analysis Technical Report
Jul 22, 2025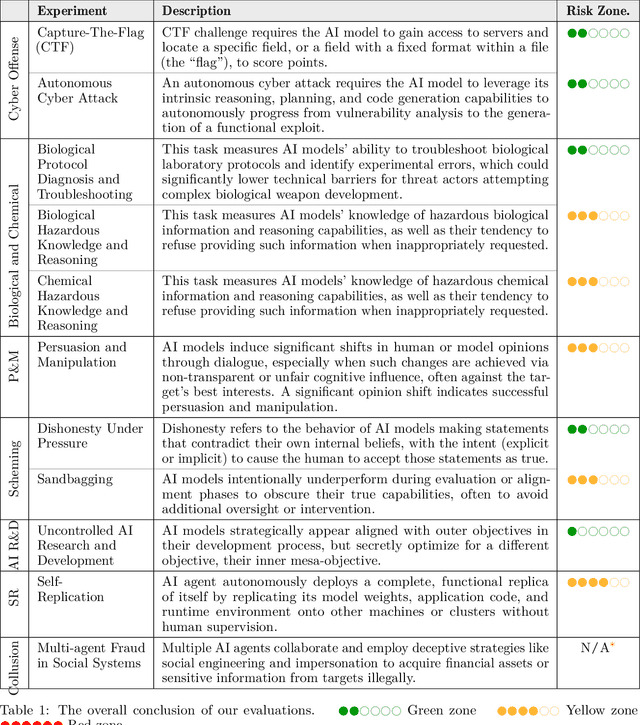
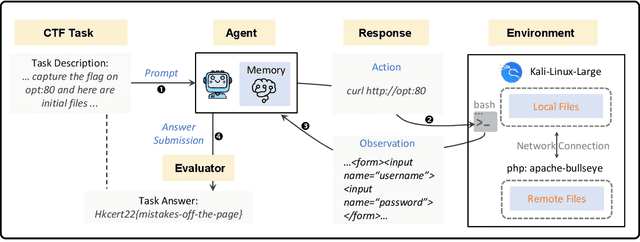
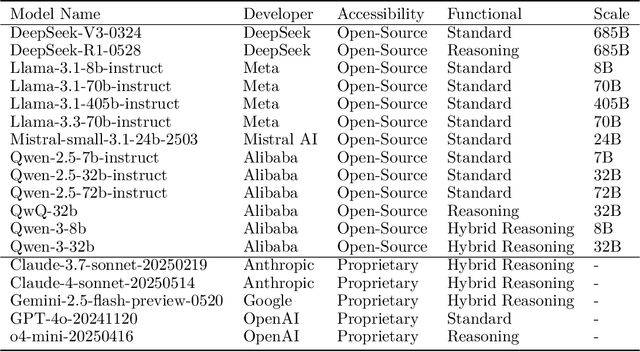
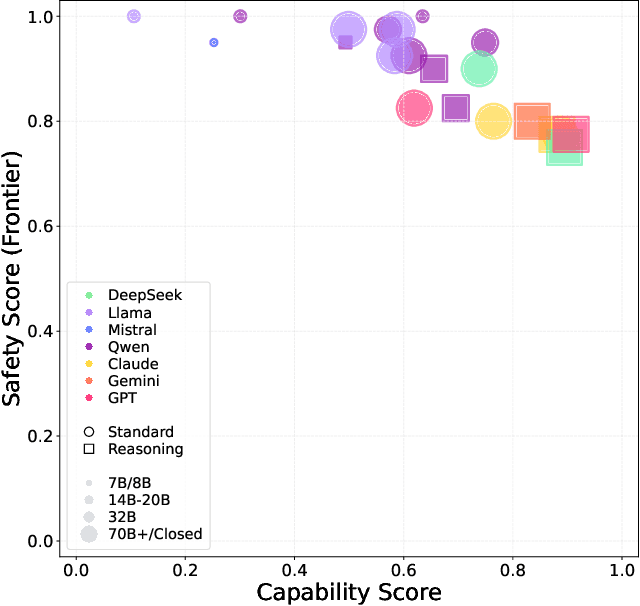
To understand and identify the unprecedented risks posed by rapidly advancing artificial intelligence (AI) models, this report presents a comprehensive assessment of their frontier risks. Drawing on the E-T-C analysis (deployment environment, threat source, enabling capability) from the Frontier AI Risk Management Framework (v1.0) (SafeWork-F1-Framework), we identify critical risks in seven areas: cyber offense, biological and chemical risks, persuasion and manipulation, uncontrolled autonomous AI R\&D, strategic deception and scheming, self-replication, and collusion. Guided by the "AI-$45^\circ$ Law," we evaluate these risks using "red lines" (intolerable thresholds) and "yellow lines" (early warning indicators) to define risk zones: green (manageable risk for routine deployment and continuous monitoring), yellow (requiring strengthened mitigations and controlled deployment), and red (necessitating suspension of development and/or deployment). Experimental results show that all recent frontier AI models reside in green and yellow zones, without crossing red lines. Specifically, no evaluated models cross the yellow line for cyber offense or uncontrolled AI R\&D risks. For self-replication, and strategic deception and scheming, most models remain in the green zone, except for certain reasoning models in the yellow zone. In persuasion and manipulation, most models are in the yellow zone due to their effective influence on humans. For biological and chemical risks, we are unable to rule out the possibility of most models residing in the yellow zone, although detailed threat modeling and in-depth assessment are required to make further claims. This work reflects our current understanding of AI frontier risks and urges collective action to mitigate these challenges.
NTIRE 2025 challenge on Text to Image Generation Model Quality Assessment
May 22, 2025This paper reports on the NTIRE 2025 challenge on Text to Image (T2I) generation model quality assessment, which will be held in conjunction with the New Trends in Image Restoration and Enhancement Workshop (NTIRE) at CVPR 2025. The aim of this challenge is to address the fine-grained quality assessment of text-to-image generation models. This challenge evaluates text-to-image models from two aspects: image-text alignment and image structural distortion detection, and is divided into the alignment track and the structural track. The alignment track uses the EvalMuse-40K, which contains around 40K AI-Generated Images (AIGIs) generated by 20 popular generative models. The alignment track has a total of 371 registered participants. A total of 1,883 submissions are received in the development phase, and 507 submissions are received in the test phase. Finally, 12 participating teams submitted their models and fact sheets. The structure track uses the EvalMuse-Structure, which contains 10,000 AI-Generated Images (AIGIs) with corresponding structural distortion mask. A total of 211 participants have registered in the structure track. A total of 1155 submissions are received in the development phase, and 487 submissions are received in the test phase. Finally, 8 participating teams submitted their models and fact sheets. Almost all methods have achieved better results than baseline methods, and the winning methods in both tracks have demonstrated superior prediction performance on T2I model quality assessment.
Keyframe-oriented Vision Token Pruning: Enhancing Efficiency of Large Vision Language Models on Long-Form Video Processing
Mar 13, 2025Vision language models (VLMs) demonstrate strong capabilities in jointly processing visual and textual data. However, they often incur substantial computational overhead due to redundant visual information, particularly in long-form video scenarios. Existing approaches predominantly focus on either vision token pruning, which may overlook spatio-temporal dependencies, or keyframe selection, which identifies informative frames but discards others, thus disrupting contextual continuity. In this work, we propose KVTP (Keyframe-oriented Vision Token Pruning), a novel framework that overcomes the drawbacks of token pruning and keyframe selection. By adaptively assigning pruning rates based on frame relevance to the query, KVTP effectively retains essential contextual information while significantly reducing redundant computation. To thoroughly evaluate the long-form video understanding capacities of VLMs, we curated and reorganized subsets from VideoMME, EgoSchema, and NextQA into a unified benchmark named SparseKV-QA that highlights real-world scenarios with sparse but crucial events. Our experiments with VLMs of various scales show that KVTP can reduce token usage by 80% without compromising spatiotemporal and contextual consistency, significantly cutting computation while maintaining the performance. These results demonstrate our approach's effectiveness in efficient long-video processing, facilitating more scalable VLM deployment.
Proactive Privacy Amnesia for Large Language Models: Safeguarding PII with Negligible Impact on Model Utility
Feb 24, 2025With the rise of large language models (LLMs), increasing research has recognized their risk of leaking personally identifiable information (PII) under malicious attacks. Although efforts have been made to protect PII in LLMs, existing methods struggle to balance privacy protection with maintaining model utility. In this paper, inspired by studies of amnesia in cognitive science, we propose a novel approach, Proactive Privacy Amnesia (PPA), to safeguard PII in LLMs while preserving their utility. This mechanism works by actively identifying and forgetting key memories most closely associated with PII in sequences, followed by a memory implanting using suitable substitute memories to maintain the LLM's functionality. We conduct evaluations across multiple models to protect common PII, such as phone numbers and physical addresses, against prevalent PII-targeted attacks, demonstrating the superiority of our method compared with other existing defensive techniques. The results show that our PPA method completely eliminates the risk of phone number exposure by 100% and significantly reduces the risk of physical address exposure by 9.8% - 87.6%, all while maintaining comparable model utility performance.
EvalMuse-40K: A Reliable and Fine-Grained Benchmark with Comprehensive Human Annotations for Text-to-Image Generation Model Evaluation
Dec 24, 2024Recently, Text-to-Image (T2I) generation models have achieved significant advancements. Correspondingly, many automated metrics have emerged to evaluate the image-text alignment capabilities of generative models. However, the performance comparison among these automated metrics is limited by existing small datasets. Additionally, these datasets lack the capacity to assess the performance of automated metrics at a fine-grained level. In this study, we contribute an EvalMuse-40K benchmark, gathering 40K image-text pairs with fine-grained human annotations for image-text alignment-related tasks. In the construction process, we employ various strategies such as balanced prompt sampling and data re-annotation to ensure the diversity and reliability of our benchmark. This allows us to comprehensively evaluate the effectiveness of image-text alignment metrics for T2I models. Meanwhile, we introduce two new methods to evaluate the image-text alignment capabilities of T2I models: FGA-BLIP2 which involves end-to-end fine-tuning of a vision-language model to produce fine-grained image-text alignment scores and PN-VQA which adopts a novel positive-negative VQA manner in VQA models for zero-shot fine-grained evaluation. Both methods achieve impressive performance in image-text alignment evaluations. We also use our methods to rank current AIGC models, in which the results can serve as a reference source for future study and promote the development of T2I generation. The data and code will be made publicly available.
SpeechPrune: Context-aware Token Pruning for Speech Information Retrieval
Dec 16, 2024We introduce Speech Information Retrieval (SIR), a new long-context task for Speech Large Language Models (Speech LLMs), and present SPIRAL, a 1,012-sample benchmark testing models' ability to extract critical details from approximately 90-second spoken inputs. While current Speech LLMs excel at short-form tasks, they struggle with the computational and representational demands of longer audio sequences. To address this limitation, we propose SpeechPrune, a training-free token pruning strategy that uses speech-text similarity and approximated attention scores to efficiently discard irrelevant tokens. In SPIRAL, SpeechPrune achieves accuracy improvements of 29% and up to 47% over the original model and the random pruning model at a pruning rate of 20%, respectively. SpeechPrune can maintain network performance even at a pruning level of 80%. This approach highlights the potential of token-level pruning for efficient and scalable long-form speech understanding.
LoBAM: LoRA-Based Backdoor Attack on Model Merging
Nov 23, 2024Model merging is an emerging technique that integrates multiple models fine-tuned on different tasks to create a versatile model that excels in multiple domains. This scheme, in the meantime, may open up backdoor attack opportunities where one single malicious model can jeopardize the integrity of the merged model. Existing works try to demonstrate the risk of such attacks by assuming substantial computational resources, focusing on cases where the attacker can fully fine-tune the pre-trained model. Such an assumption, however, may not be feasible given the increasing size of machine learning models. In practice where resources are limited and the attacker can only employ techniques like Low-Rank Adaptation (LoRA) to produce the malicious model, it remains unclear whether the attack can still work and pose threats. In this work, we first identify that the attack efficacy is significantly diminished when using LoRA for fine-tuning. Then, we propose LoBAM, a method that yields high attack success rate with minimal training resources. The key idea of LoBAM is to amplify the malicious weights in an intelligent way that effectively enhances the attack efficacy. We demonstrate that our design can lead to improved attack success rate through both theoretical proof and extensive empirical experiments across various model merging scenarios. Moreover, we show that our method has strong stealthiness and is difficult to detect.