 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFractional Heat Kernel for Semi-Supervised Graph Learning with Small Training Sample Size
Oct 06, 2025In this work, we introduce novel algorithms for label propagation and self-training using fractional heat kernel dynamics with a source term. We motivate the methodology through the classical correspondence of information theory with the physics of parabolic evolution equations. We integrate the fractional heat kernel into Graph Neural Network architectures such as Graph Convolutional Networks and Graph Attention, enhancing their expressiveness through adaptive, multi-hop diffusion. By applying Chebyshev polynomial approximations, large graphs become computationally feasible. Motivating variational formulations demonstrate that by extending the classical diffusion model to fractional powers of the Laplacian, nonlocal interactions deliver more globally diffusing labels. The particular balance between supervision of known labels and diffusion across the graph is particularly advantageous in the case where only a small number of labeled training examples are present. We demonstrate the effectiveness of this approach on standard datasets.
Machine Learning Algorithms for Improving Exact Classical Solvers in Mixed Integer Continuous Optimization
Aug 09, 2025Integer and mixed-integer nonlinear programming (INLP, MINLP) are central to logistics, energy, and scheduling, but remain computationally challenging. This survey examines how machine learning and reinforcement learning can enhance exact optimization methods - particularly branch-and-bound (BB), without compromising global optimality. We cover discrete, continuous, and mixed-integer formulations, and highlight applications such as crew scheduling, vehicle routing, and hydropower planning. We introduce a unified BB framework that embeds learning-based strategies into branching, cut selection, node ordering, and parameter control. Classical algorithms are augmented using supervised, imitation, and reinforcement learning models to accelerate convergence while maintaining correctness. We conclude with a taxonomy of learning methods by solver class and learning paradigm, and outline open challenges in generalization, hybridization, and scaling intelligent solvers.
CONCORD: Concept-Informed Diffusion for Dataset Distillation
May 23, 2025Dataset distillation (DD) has witnessed significant progress in creating small datasets that encapsulate rich information from large original ones. Particularly, methods based on generative priors show promising performance, while maintaining computational efficiency and cross-architecture generalization. However, the generation process lacks explicit controllability for each sample. Previous distillation methods primarily match the real distribution from the perspective of the entire dataset, whereas overlooking concept completeness at the instance level. The missing or incorrectly represented object details cannot be efficiently compensated due to the constrained sample amount typical in DD settings. To this end, we propose incorporating the concept understanding of large language models (LLMs) to perform Concept-Informed Diffusion (CONCORD) for dataset distillation. Specifically, distinguishable and fine-grained concepts are retrieved based on category labels to inform the denoising process and refine essential object details. By integrating these concepts, the proposed method significantly enhances both the controllability and interpretability of the distilled image generation, without relying on pre-trained classifiers. We demonstrate the efficacy of CONCORD by achieving state-of-the-art performance on ImageNet-1K and its subsets. The code implementation is released in https://github.com/vimar-gu/CONCORD.
Federated Sinkhorn
Feb 10, 2025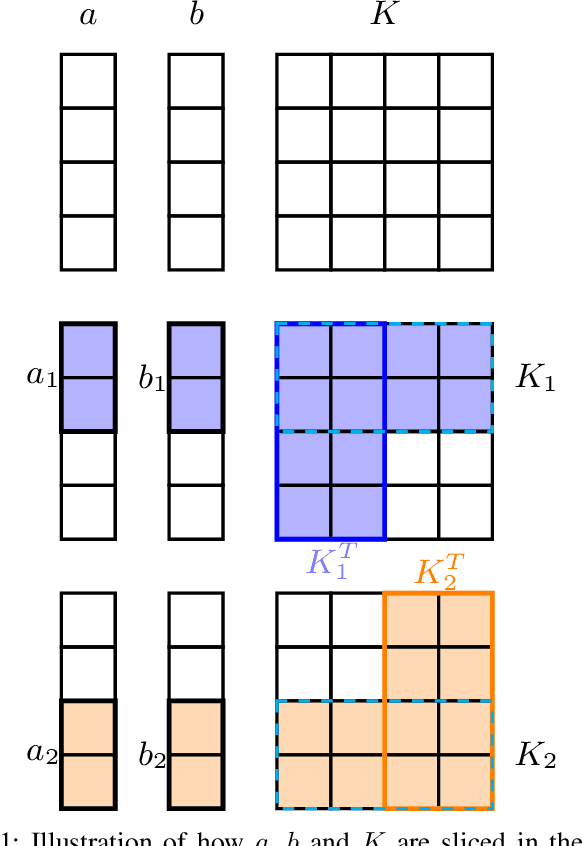
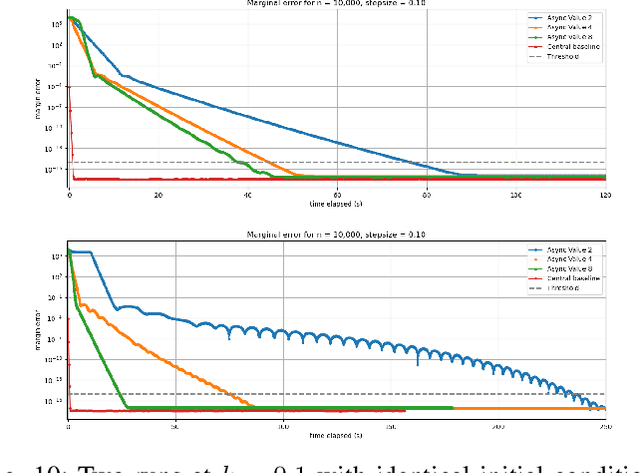
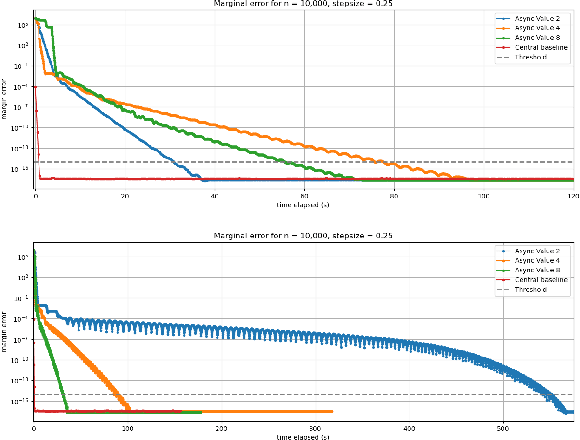
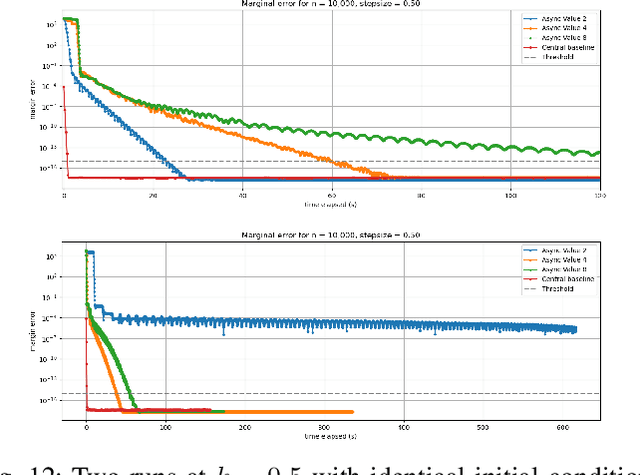
In this work we investigate the potential of solving the discrete Optimal Transport (OT) problem with entropy regularization in a federated learning setting. Recall that the celebrated Sinkhorn algorithm transforms the classical OT linear program into strongly convex constrained optimization, facilitating first order methods for otherwise intractably large problems. A common contemporary setting that remains an open problem as far as the application of Sinkhorn is the presence of data spread across clients with distributed inter-communication, either due to clients whose privacy is a concern, or simply by necessity of processing and memory hardware limitations. In this work we investigate various natural procedures, which we refer to as Federated Sinkhorn, that handle distributed environments where data is partitioned across multiple clients. We formulate the problem as minimizing the transport cost with an entropy regularization term, subject to marginal constraints, where block components of the source and target distribution vectors are locally known to clients corresponding to each block. We consider both synchronous and asynchronous variants as well as all-to-all and server-client communication topology protocols. Each procedure allows clients to compute local operations on their data partition while periodically exchanging information with others. We provide theoretical guarantees on convergence for the different variants under different possible conditions. We empirically demonstrate the algorithms performance on synthetic datasets and a real-world financial risk assessment application. The investigation highlights the subtle tradeoffs associated with computation and communication time in different settings and how they depend on problem size and sparsity.
"Cause" is Mechanistic Narrative within Scientific Domains: An Ordinary Language Philosophical Critique of "Causal Machine Learning"
Jan 10, 2025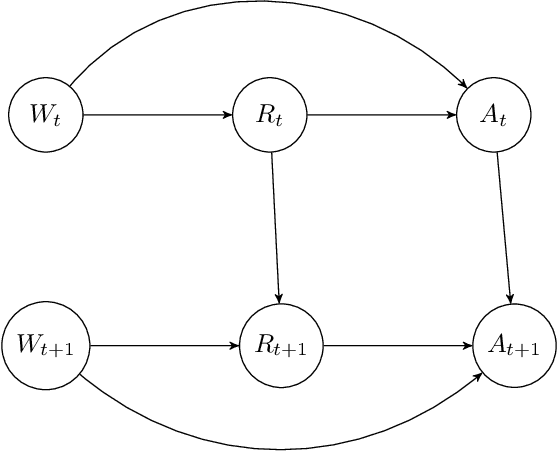

Causal Learning has emerged as a major theme of AI in recent years, promising to use special techniques to reveal the true nature of cause and effect in a number of important domains. We consider the Epistemology of learning and recognizing true cause and effect phenomena. Through thought exercises on the customary use of the word ''cause'', especially in scientific domains, we investigate what, in practice, constitutes a valid causal claim. We recognize the word's uses across scientific domains in disparate form but consistent function within the scientific paradigm. We highlight fundamental distinctions of practice that can be performed in the natural and social sciences, highlight the importance of many systems of interest being open and irreducible and identify the important notion of Hermeneutic knowledge for social science inquiry. We posit that the distinct properties require that definitive causal claims can only come through an agglomeration of consistent evidence across multiple domains and levels of abstraction, such as empirical, physiological, biochemical, etc. We present Cognitive Science as an exemplary multi-disciplinary field providing omnipresent opportunity for such a Research Program, and highlight the main general modes of practice of scientific inquiry that can adequately merge, rather than place as incorrigibly conflictual, multi-domain multi-abstraction scientific practices and language games.
Towards Diverse Device Heterogeneous Federated Learning via Task Arithmetic Knowledge Integration
Sep 27, 2024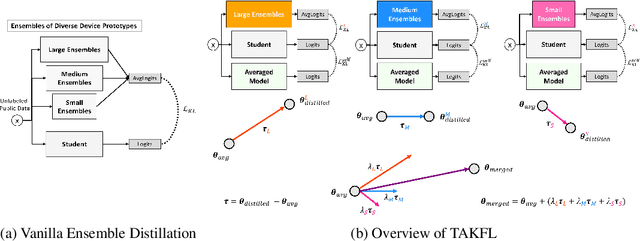



Federated Learning has emerged as a promising paradigm for collaborative machine learning, while preserving user data privacy. Despite its potential, standard FL lacks support for diverse heterogeneous device prototypes, which vary significantly in model and dataset sizes -- from small IoT devices to large workstations. This limitation is only partially addressed by existing knowledge distillation techniques, which often fail to transfer knowledge effectively across a broad spectrum of device prototypes with varied capabilities. This failure primarily stems from two issues: the dilution of informative logits from more capable devices by those from less capable ones, and the use of a single integrated logits as the distillation target across all devices, which neglects their individual learning capacities and and the unique contributions of each. To address these challenges, we introduce TAKFL, a novel KD-based framework that treats the knowledge transfer from each device prototype's ensemble as a separate task, independently distilling each to preserve its unique contributions and avoid dilution. TAKFL also incorporates a KD-based self-regularization technique to mitigate the issues related to the noisy and unsupervised ensemble distillation process. To integrate the separately distilled knowledge, we introduce an adaptive task arithmetic knowledge integration process, allowing each student model to customize the knowledge integration for optimal performance. Additionally, we present theoretical results demonstrating the effectiveness of task arithmetic in transferring knowledge across heterogeneous devices with varying capacities. Comprehensive evaluations of our method across both CV and NLP tasks demonstrate that TAKFL achieves SOTA results in a variety of datasets and settings, significantly outperforming existing KD-based methods. Code is released at https://github.com/MMorafah/TAKFL
Dataset Distillation from First Principles: Integrating Core Information Extraction and Purposeful Learning
Sep 02, 2024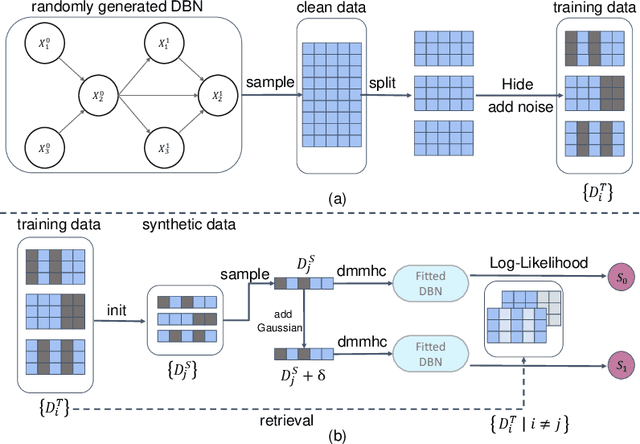
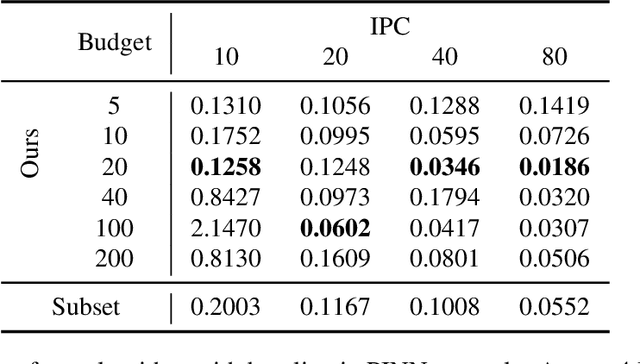
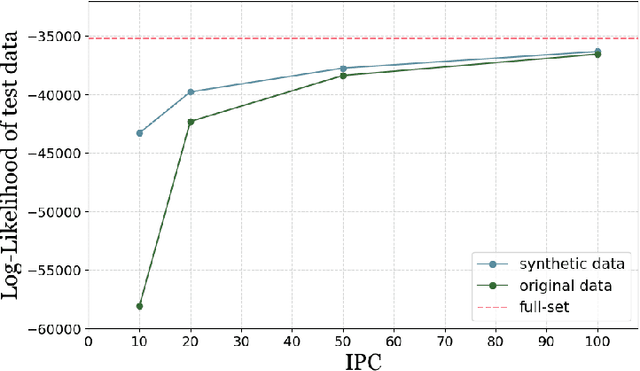
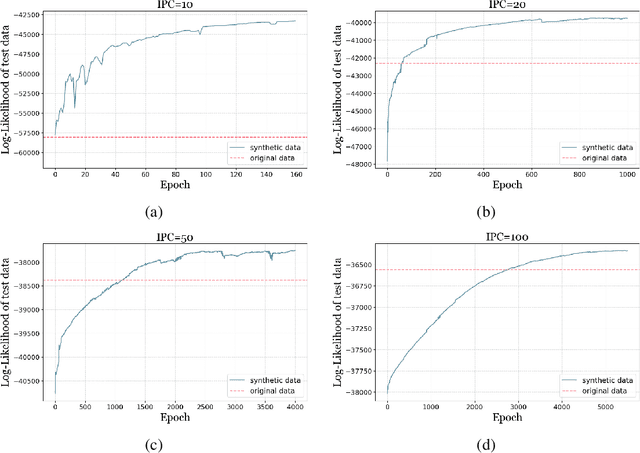
Dataset distillation (DD) is an increasingly important technique that focuses on constructing a synthetic dataset capable of capturing the core information in training data to achieve comparable performance in models trained on the latter. While DD has a wide range of applications, the theory supporting it is less well evolved. New methods of DD are compared on a common set of benchmarks, rather than oriented towards any particular learning task. In this work, we present a formal model of DD, arguing that a precise characterization of the underlying optimization problem must specify the inference task associated with the application of interest. Without this task-specific focus, the DD problem is under-specified, and the selection of a DD algorithm for a particular task is merely heuristic. Our formalization reveals novel applications of DD across different modeling environments. We analyze existing DD methods through this broader lens, highlighting their strengths and limitations in terms of accuracy and faithfulness to optimal DD operation. Finally, we present numerical results for two case studies important in contemporary settings. Firstly, we address a critical challenge in medical data analysis: merging the knowledge from different datasets composed of intersecting, but not identical, sets of features, in order to construct a larger dataset in what is usually a small sample setting. Secondly, we consider out-of-distribution error across boundary conditions for physics-informed neural networks (PINNs), showing the potential for DD to provide more physically faithful data. By establishing this general formulation of DD, we aim to establish a new research paradigm by which DD can be understood and from which new DD techniques can arise.
Probabilistic Iterative Hard Thresholding for Sparse Learning
Sep 02, 2024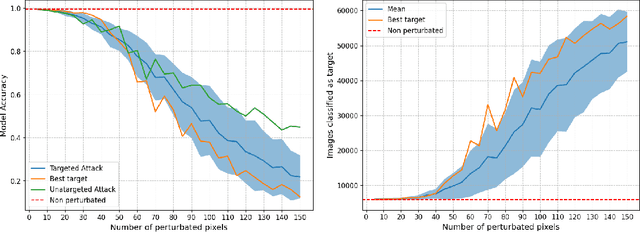

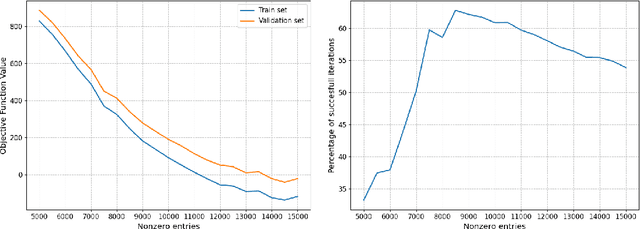
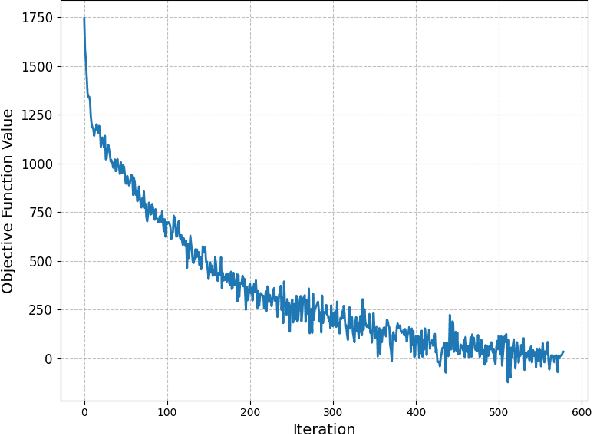
For statistical modeling wherein the data regime is unfavorable in terms of dimensionality relative to the sample size, finding hidden sparsity in the ground truth can be critical in formulating an accurate statistical model. The so-called "l0 norm" which counts the number of non-zero components in a vector, is a strong reliable mechanism of enforcing sparsity when incorporated into an optimization problem. However, in big data settings wherein noisy estimates of the gradient must be evaluated out of computational necessity, the literature is scant on methods that reliably converge. In this paper we present an approach towards solving expectation objective optimization problems with cardinality constraints. We prove convergence of the underlying stochastic process, and demonstrate the performance on two Machine Learning problems.
Learning Dynamic Bayesian Networks from Data: Foundations, First Principles and Numerical Comparisons
Jun 25, 2024In this paper, we present a guide to the foundations of learning Dynamic Bayesian Networks (DBNs) from data in the form of multiple samples of trajectories for some length of time. We present the formalism for a generic as well as a set of common types of DBNs for particular variable distributions. We present the analytical form of the models, with a comprehensive discussion on the interdependence between structure and weights in a DBN model and their implications for learning. Next, we give a broad overview of learning methods and describe and categorize them based on the most important statistical features, and how they treat the interplay between learning structure and weights. We give the analytical form of the likelihood and Bayesian score functions, emphasizing the distinction from the static case. We discuss functions used in optimization to enforce structural requirements. We briefly discuss more complex extensions and representations. Finally we present a set of comparisons in different settings for various distinct but representative algorithms across the variants.
Empirical Bayes for Dynamic Bayesian Networks Using Generalized Variational Inference
Jun 25, 2024
In this work, we demonstrate the Empirical Bayes approach to learning a Dynamic Bayesian Network. By starting with several point estimates of structure and weights, we can use a data-driven prior to subsequently obtain a model to quantify uncertainty. This approach uses a recent development of Generalized Variational Inference, and indicates the potential of sampling the uncertainty of a mixture of DAG structures as well as a parameter posterior.