 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAvoid Forgetting by Preserving Global Knowledge Gradients in Federated Learning with Non-IID Data
May 26, 2025The inevitable presence of data heterogeneity has made federated learning very challenging. There are numerous methods to deal with this issue, such as local regularization, better model fusion techniques, and data sharing. Though effective, they lack a deep understanding of how data heterogeneity can affect the global decision boundary. In this paper, we bridge this gap by performing an experimental analysis of the learned decision boundary using a toy example. Our observations are surprising: (1) we find that the existing methods suffer from forgetting and clients forget the global decision boundary and only learn the perfect local one, and (2) this happens regardless of the initial weights, and clients forget the global decision boundary even starting from pre-trained optimal weights. In this paper, we present FedProj, a federated learning framework that robustly learns the global decision boundary and avoids its forgetting during local training. To achieve better ensemble knowledge fusion, we design a novel server-side ensemble knowledge transfer loss to further calibrate the learned global decision boundary. To alleviate the issue of learned global decision boundary forgetting, we further propose leveraging an episodic memory of average ensemble logits on a public unlabeled dataset to regulate the gradient updates at each step of local training. Experimental results demonstrate that FedProj outperforms state-of-the-art methods by a large margin.
Federated Learning Client Pruning for Noisy Labels
Nov 11, 2024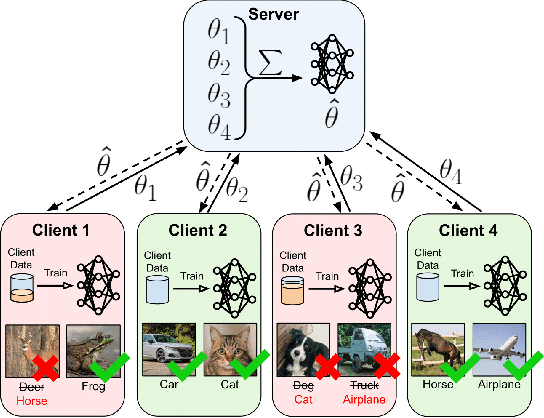
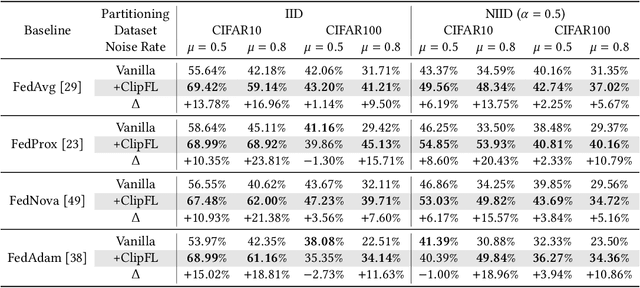
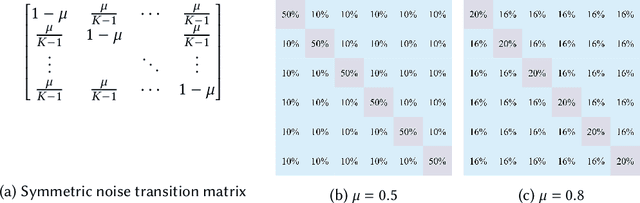

Federated Learning (FL) enables collaborative model training across decentralized edge devices while preserving data privacy. However, existing FL methods often assume clean annotated datasets, impractical for resource-constrained edge devices. In reality, noisy labels are prevalent, posing significant challenges to FL performance. Prior approaches attempt label correction and robust training techniques but exhibit limited efficacy, particularly under high noise levels. This paper introduces ClipFL (Federated Learning Client Pruning), a novel framework addressing noisy labels from a fresh perspective. ClipFL identifies and excludes noisy clients based on their performance on a clean validation dataset, tracked using a Noise Candidacy Score (NCS). The framework comprises three phases: pre-client pruning to identify potential noisy clients and calculate their NCS, client pruning to exclude a percentage of clients with the highest NCS, and post-client pruning for fine-tuning the global model with standard FL on clean clients. Empirical evaluation demonstrates ClipFL's efficacy across diverse datasets and noise levels, achieving accurate noisy client identification, superior performance, faster convergence, and reduced communication costs compared to state-of-the-art FL methods. Our code is available at https://github.com/MMorafah/ClipFL.
Towards Diverse Device Heterogeneous Federated Learning via Task Arithmetic Knowledge Integration
Sep 27, 2024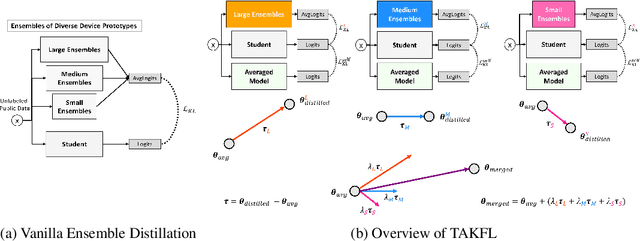



Federated Learning has emerged as a promising paradigm for collaborative machine learning, while preserving user data privacy. Despite its potential, standard FL lacks support for diverse heterogeneous device prototypes, which vary significantly in model and dataset sizes -- from small IoT devices to large workstations. This limitation is only partially addressed by existing knowledge distillation techniques, which often fail to transfer knowledge effectively across a broad spectrum of device prototypes with varied capabilities. This failure primarily stems from two issues: the dilution of informative logits from more capable devices by those from less capable ones, and the use of a single integrated logits as the distillation target across all devices, which neglects their individual learning capacities and and the unique contributions of each. To address these challenges, we introduce TAKFL, a novel KD-based framework that treats the knowledge transfer from each device prototype's ensemble as a separate task, independently distilling each to preserve its unique contributions and avoid dilution. TAKFL also incorporates a KD-based self-regularization technique to mitigate the issues related to the noisy and unsupervised ensemble distillation process. To integrate the separately distilled knowledge, we introduce an adaptive task arithmetic knowledge integration process, allowing each student model to customize the knowledge integration for optimal performance. Additionally, we present theoretical results demonstrating the effectiveness of task arithmetic in transferring knowledge across heterogeneous devices with varying capacities. Comprehensive evaluations of our method across both CV and NLP tasks demonstrate that TAKFL achieves SOTA results in a variety of datasets and settings, significantly outperforming existing KD-based methods. Code is released at https://github.com/MMorafah/TAKFL
Stable Diffusion-based Data Augmentation for Federated Learning with Non-IID Data
May 13, 2024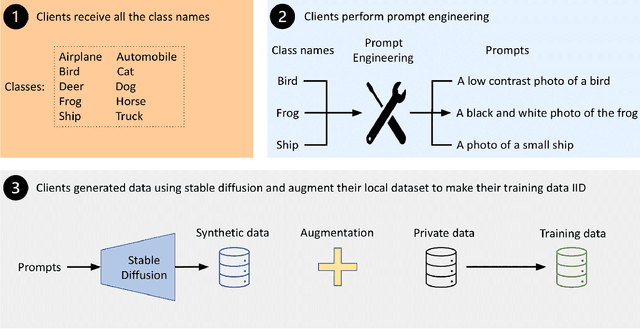

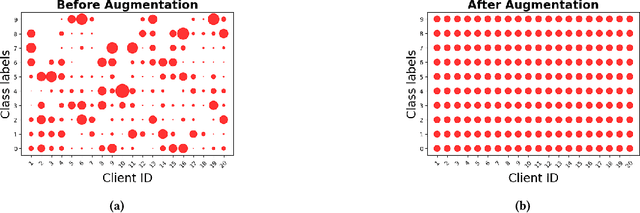

The proliferation of edge devices has brought Federated Learning (FL) to the forefront as a promising paradigm for decentralized and collaborative model training while preserving the privacy of clients' data. However, FL struggles with a significant performance reduction and poor convergence when confronted with Non-Independent and Identically Distributed (Non-IID) data distributions among participating clients. While previous efforts, such as client drift mitigation and advanced server-side model fusion techniques, have shown some success in addressing this challenge, they often overlook the root cause of the performance reduction - the absence of identical data accurately mirroring the global data distribution among clients. In this paper, we introduce Gen-FedSD, a novel approach that harnesses the powerful capability of state-of-the-art text-to-image foundation models to bridge the significant Non-IID performance gaps in FL. In Gen-FedSD, each client constructs textual prompts for each class label and leverages an off-the-shelf state-of-the-art pre-trained Stable Diffusion model to synthesize high-quality data samples. The generated synthetic data is tailored to each client's unique local data gaps and distribution disparities, effectively making the final augmented local data IID. Through extensive experimentation, we demonstrate that Gen-FedSD achieves state-of-the-art performance and significant communication cost savings across various datasets and Non-IID settings.
A Practical Recipe for Federated Learning Under Statistical Heterogeneity Experimental Design
Jul 28, 2023

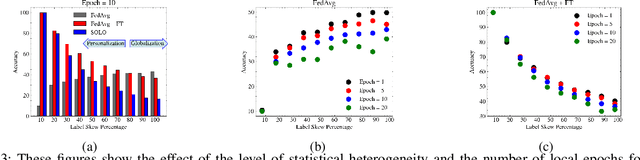

Federated Learning (FL) has been an area of active research in recent years. There have been numerous studies in FL to make it more successful in the presence of data heterogeneity. However, despite the existence of many publications, the state of progress in the field is unknown. Many of the works use inconsistent experimental settings and there are no comprehensive studies on the effect of FL-specific experimental variables on the results and practical insights for a more comparable and consistent FL experimental setup. Furthermore, the existence of several benchmarks and confounding variables has further complicated the issue of inconsistency and ambiguity. In this work, we present the first comprehensive study on the effect of FL-specific experimental variables in relation to each other and performance results, bringing several insights and recommendations for designing a meaningful and well-incentivized FL experimental setup. We further aid the community by releasing FedZoo-Bench, an open-source library based on PyTorch with pre-implementation of 22 state-of-the-art methods, and a broad set of standardized and customizable features available at https://github.com/MMorafah/FedZoo-Bench. We also provide a comprehensive comparison of several state-of-the-art (SOTA) methods to better understand the current state of the field and existing limitations.
Rethinking Data Heterogeneity in Federated Learning: Introducing a New Notion and Standard Benchmarks
Sep 30, 2022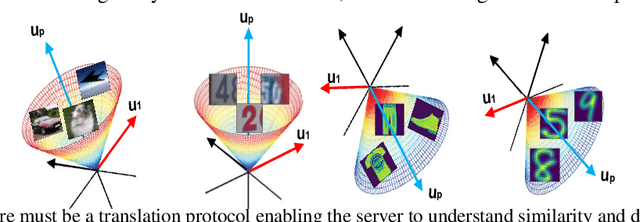


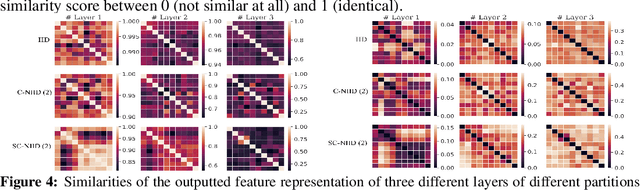
Though successful, federated learning presents new challenges for machine learning, especially when the issue of data heterogeneity, also known as Non-IID data, arises. To cope with the statistical heterogeneity, previous works incorporated a proximal term in local optimization or modified the model aggregation scheme at the server side or advocated clustered federated learning approaches where the central server groups agent population into clusters with jointly trainable data distributions to take the advantage of a certain level of personalization. While effective, they lack a deep elaboration on what kind of data heterogeneity and how the data heterogeneity impacts the accuracy performance of the participating clients. In contrast to many of the prior federated learning approaches, we demonstrate not only the issue of data heterogeneity in current setups is not necessarily a problem but also in fact it can be beneficial for the FL participants. Our observations are intuitive: (1) Dissimilar labels of clients (label skew) are not necessarily considered data heterogeneity, and (2) the principal angle between the agents' data subspaces spanned by their corresponding principal vectors of data is a better estimate of the data heterogeneity. Our code is available at https://github.com/MMorafah/FL-SC-NIID.
Efficient Distribution Similarity Identification in Clustered Federated Learning via Principal Angles Between Client Data Subspaces
Sep 21, 2022



Clustered federated learning (FL) has been shown to produce promising results by grouping clients into clusters. This is especially effective in scenarios where separate groups of clients have significant differences in the distributions of their local data. Existing clustered FL algorithms are essentially trying to group together clients with similar distributions so that clients in the same cluster can leverage each other's data to better perform federated learning. However, prior clustered FL algorithms attempt to learn these distribution similarities indirectly during training, which can be quite time consuming as many rounds of federated learning may be required until the formation of clusters is stabilized. In this paper, we propose a new approach to federated learning that directly aims to efficiently identify distribution similarities among clients by analyzing the principal angles between the client data subspaces. Each client applies a truncated singular value decomposition (SVD) step on its local data in a single-shot manner to derive a small set of principal vectors, which provides a signature that succinctly captures the main characteristics of the underlying distribution. This small set of principal vectors is provided to the server so that the server can directly identify distribution similarities among the clients to form clusters. This is achieved by comparing the similarities of the principal angles between the client data subspaces spanned by those principal vectors. The approach provides a simple, yet effective clustered FL framework that addresses a broad range of data heterogeneity issues beyond simpler forms of Non-IIDness like label skews. Our clustered FL approach also enables convergence guarantees for non-convex objectives. Our code is available at https://github.com/MMorafah/PACFL.
FLIS: Clustered Federated Learning via Inference Similarity for Non-IID Data Distribution
Aug 20, 2022


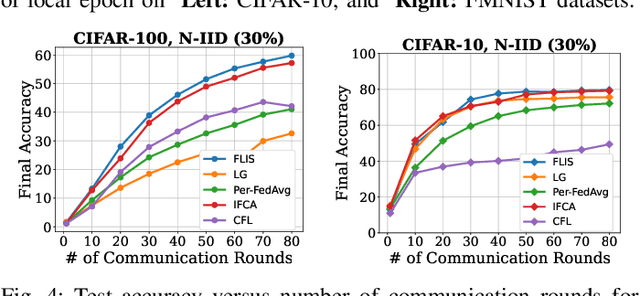
Classical federated learning approaches yield significant performance degradation in the presence of Non-IID data distributions of participants. When the distribution of each local dataset is highly different from the global one, the local objective of each client will be inconsistent with the global optima which incur a drift in the local updates. This phenomenon highly impacts the performance of clients. This is while the primary incentive for clients to participate in federated learning is to obtain better personalized models. To address the above-mentioned issue, we present a new algorithm, FLIS, which groups the clients population in clusters with jointly trainable data distributions by leveraging the inference similarity of clients' models. This framework captures settings where different groups of users have their own objectives (learning tasks) but by aggregating their data with others in the same cluster (same learning task) to perform more efficient and personalized federated learning. We present experimental results to demonstrate the benefits of FLIS over the state-of-the-art benchmarks on CIFAR-100/10, SVHN, and FMNIST datasets. Our code is available at https://github.com/MMorafah/FLIS.
Personalized Federated Learning by Structured and Unstructured Pruning under Data Heterogeneity
May 10, 2021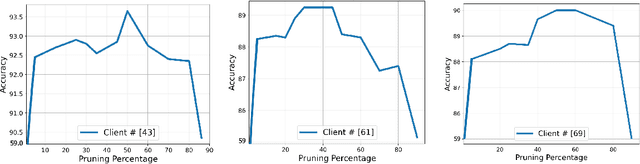


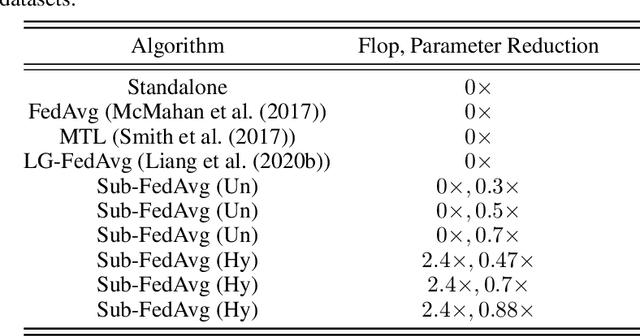
The traditional approach in FL tries to learn a single global model collaboratively with the help of many clients under the orchestration of a central server. However, learning a single global model might not work well for all clients participating in the FL under data heterogeneity. Therefore, the personalization of the global model becomes crucial in handling the challenges that arise with statistical heterogeneity and the non-IID distribution of data. Unlike prior works, in this work we propose a new approach for obtaining a personalized model from a client-level objective. This further motivates all clients to participate in federation even under statistical heterogeneity in order to improve their performance, instead of merely being a source of data and model training for the central server. To realize this personalization, we leverage finding a small subnetwork for each client by applying hybrid pruning (combination of structured and unstructured pruning), and unstructured pruning. Through a range of experiments on different benchmarks, we observed that the clients with similar data (labels) share similar personal parameters. By finding a subnetwork for each client ...