 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo-stage Multi-beam Training for Multiuser Millimeter-Wave Communications
Jan 07, 2026In this letter, we study an efficient multi-beam training method for multiuser millimeter-wave communication systems. Unlike the conventional single-beam training method that relies on exhaustive search, multi-beam training design faces a key challenge in balancing the trade-off between beam training overhead and success beam-identification rate, exacerbated by severe inter-beam interference. To tackle this challenge, we propose a new two-stage multi-beam training method with two distinct multi-beam patterns to enable fast and accurate user angle identification. Specifically, in the first stage, the antenna array is divided into sparse subarrays to generate multiple beams (with high array gains), for identifying candidate user angles. In the second stage, the array is redivided into dense subarrays to generate flexibly steered wide beams, for which a cross-validation method is employed to effectively resolve the remaining angular ambiguity in the first stage. Last, numerical results demonstrate that the proposed method significantly improves the success beam-identification rate compared to existing multi-beam training methods, while retaining or even reducing the required beam training overhead.
Photoplethysmography based atrial fibrillation detection: an updated review from July 2019
Oct 22, 2023
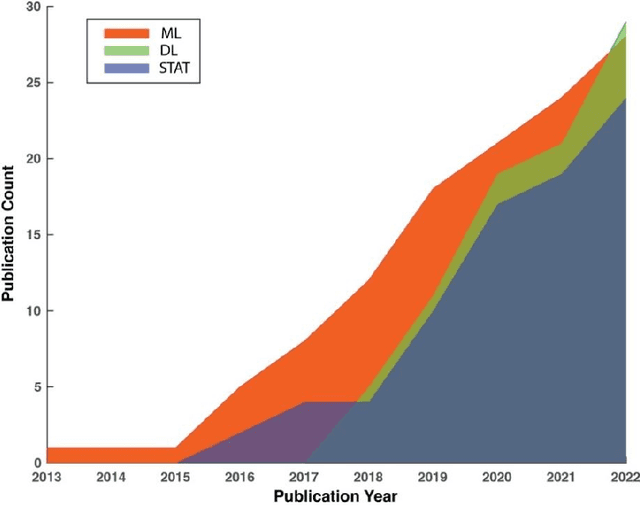
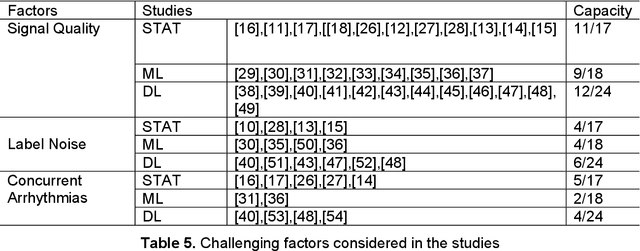
Atrial fibrillation (AF) is a prevalent cardiac arrhythmia associated with significant health ramifications, including an elevated susceptibility to ischemic stroke, heart disease, and heightened mortality. Photoplethysmography (PPG) has emerged as a promising technology for continuous AF monitoring for its cost-effectiveness and widespread integration into wearable devices. Our team previously conducted an exhaustive review on PPG-based AF detection before June 2019. However, since then, more advanced technologies have emerged in this field. This paper offers a comprehensive review of the latest advancements in PPG-based AF detection, utilizing digital health and artificial intelligence (AI) solutions, within the timeframe spanning from July 2019 to December 2022. Through extensive exploration of scientific databases, we have identified 59 pertinent studies. Our comprehensive review encompasses an in-depth assessment of the statistical methodologies, traditional machine learning techniques, and deep learning approaches employed in these studies. In addition, we address the challenges encountered in the domain of PPG-based AF detection. Furthermore, we maintain a dedicated website to curate the latest research in this area, with regular updates on a regular basis.
A Practical Recipe for Federated Learning Under Statistical Heterogeneity Experimental Design
Jul 28, 2023

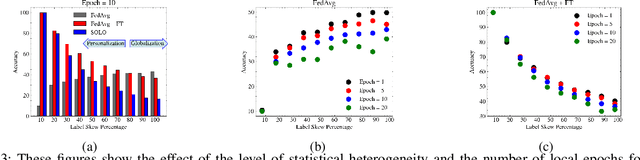

Federated Learning (FL) has been an area of active research in recent years. There have been numerous studies in FL to make it more successful in the presence of data heterogeneity. However, despite the existence of many publications, the state of progress in the field is unknown. Many of the works use inconsistent experimental settings and there are no comprehensive studies on the effect of FL-specific experimental variables on the results and practical insights for a more comparable and consistent FL experimental setup. Furthermore, the existence of several benchmarks and confounding variables has further complicated the issue of inconsistency and ambiguity. In this work, we present the first comprehensive study on the effect of FL-specific experimental variables in relation to each other and performance results, bringing several insights and recommendations for designing a meaningful and well-incentivized FL experimental setup. We further aid the community by releasing FedZoo-Bench, an open-source library based on PyTorch with pre-implementation of 22 state-of-the-art methods, and a broad set of standardized and customizable features available at https://github.com/MMorafah/FedZoo-Bench. We also provide a comprehensive comparison of several state-of-the-art (SOTA) methods to better understand the current state of the field and existing limitations.
Weighted Point Cloud Normal Estimation
May 06, 2023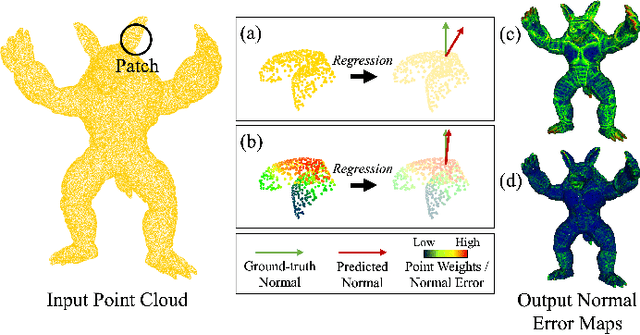
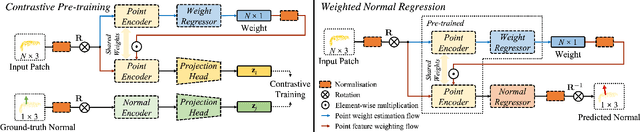
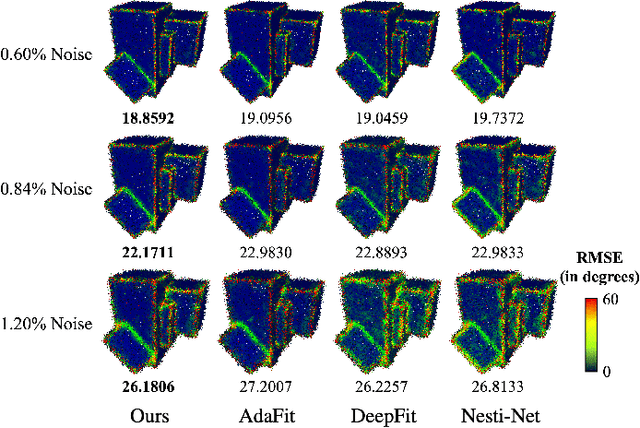
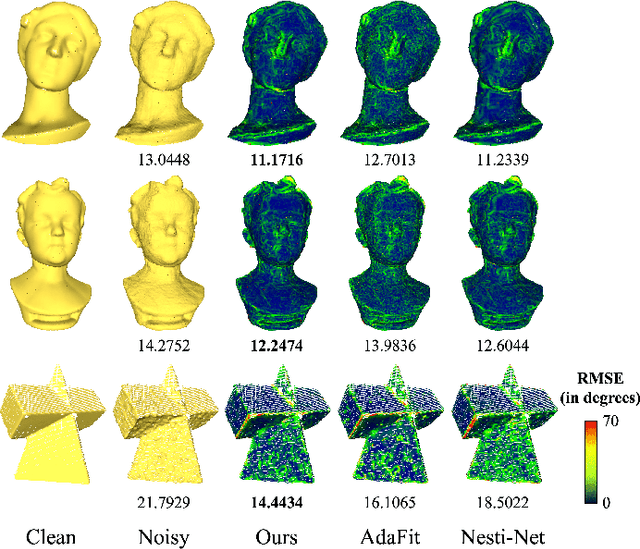
Existing normal estimation methods for point clouds are often less robust to severe noise and complex geometric structures. Also, they usually ignore the contributions of different neighbouring points during normal estimation, which leads to less accurate results. In this paper, we introduce a weighted normal estimation method for 3D point cloud data. We innovate in two key points: 1) we develop a novel weighted normal regression technique that predicts point-wise weights from local point patches and use them for robust, feature-preserving normal regression; 2) we propose to conduct contrastive learning between point patches and the corresponding ground-truth normals of the patches' central points as a pre-training process to facilitate normal regression. Comprehensive experiments demonstrate that our method can robustly handle noisy and complex point clouds, achieving state-of-the-art performance on both synthetic and real-world datasets.
When Do Curricula Work in Federated Learning?
Dec 24, 2022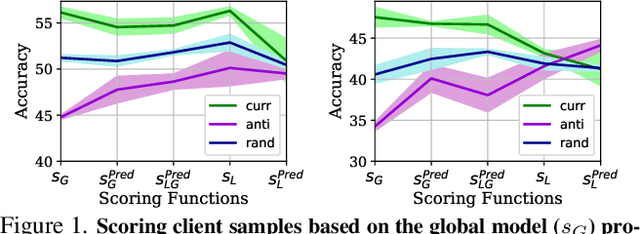

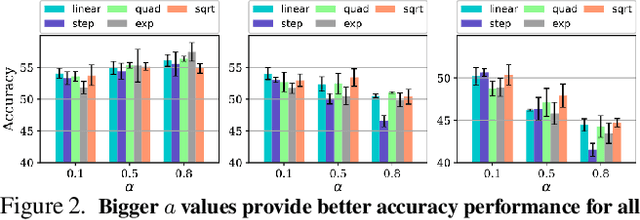
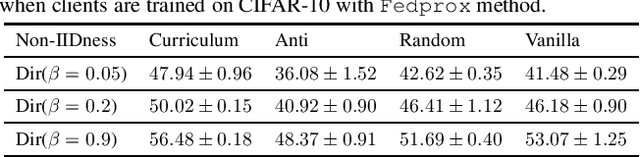
An oft-cited open problem of federated learning is the existence of data heterogeneity at the clients. One pathway to understanding the drastic accuracy drop in federated learning is by scrutinizing the behavior of the clients' deep models on data with different levels of "difficulty", which has been left unaddressed. In this paper, we investigate a different and rarely studied dimension of FL: ordered learning. Specifically, we aim to investigate how ordered learning principles can contribute to alleviating the heterogeneity effects in FL. We present theoretical analysis and conduct extensive empirical studies on the efficacy of orderings spanning three kinds of learning: curriculum, anti-curriculum, and random curriculum. We find that curriculum learning largely alleviates non-IIDness. Interestingly, the more disparate the data distributions across clients the more they benefit from ordered learning. We provide analysis explaining this phenomenon, specifically indicating how curriculum training appears to make the objective landscape progressively less convex, suggesting fast converging iterations at the beginning of the training procedure. We derive quantitative results of convergence for both convex and nonconvex objectives by modeling the curriculum training on federated devices as local SGD with locally biased stochastic gradients. Also, inspired by ordered learning, we propose a novel client selection technique that benefits from the real-world disparity in the clients. Our proposed approach to client selection has a synergic effect when applied together with ordered learning in FL.
Neural Routing in Meta Learning
Oct 14, 2022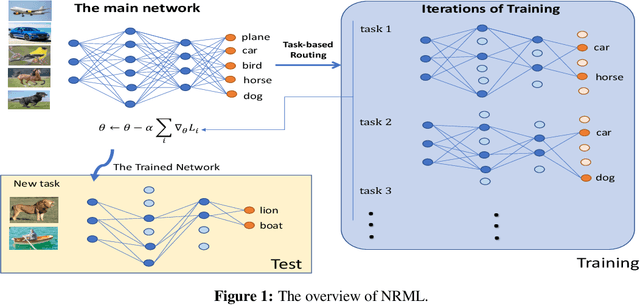

Meta-learning often referred to as learning-to-learn is a promising notion raised to mimic human learning by exploiting the knowledge of prior tasks but being able to adapt quickly to novel tasks. A plethora of models has emerged in this context and improved the learning efficiency, robustness, etc. The question that arises here is can we emulate other aspects of human learning and incorporate them into the existing meta learning algorithms? Inspired by the widely recognized finding in neuroscience that distinct parts of the brain are highly specialized for different types of tasks, we aim to improve the model performance of the current meta learning algorithms by selectively using only parts of the model conditioned on the input tasks. In this work, we describe an approach that investigates task-dependent dynamic neuron selection in deep convolutional neural networks (CNNs) by leveraging the scaling factor in the batch normalization (BN) layer associated with each convolutional layer. The problem is intriguing because the idea of helping different parts of the model to learn from different types of tasks may help us train better filters in CNNs, and improve the model generalization performance. We find that the proposed approach, neural routing in meta learning (NRML), outperforms one of the well-known existing meta learning baselines on few-shot classification tasks on the most widely used benchmark datasets.
Efficient Distribution Similarity Identification in Clustered Federated Learning via Principal Angles Between Client Data Subspaces
Sep 21, 2022



Clustered federated learning (FL) has been shown to produce promising results by grouping clients into clusters. This is especially effective in scenarios where separate groups of clients have significant differences in the distributions of their local data. Existing clustered FL algorithms are essentially trying to group together clients with similar distributions so that clients in the same cluster can leverage each other's data to better perform federated learning. However, prior clustered FL algorithms attempt to learn these distribution similarities indirectly during training, which can be quite time consuming as many rounds of federated learning may be required until the formation of clusters is stabilized. In this paper, we propose a new approach to federated learning that directly aims to efficiently identify distribution similarities among clients by analyzing the principal angles between the client data subspaces. Each client applies a truncated singular value decomposition (SVD) step on its local data in a single-shot manner to derive a small set of principal vectors, which provides a signature that succinctly captures the main characteristics of the underlying distribution. This small set of principal vectors is provided to the server so that the server can directly identify distribution similarities among the clients to form clusters. This is achieved by comparing the similarities of the principal angles between the client data subspaces spanned by those principal vectors. The approach provides a simple, yet effective clustered FL framework that addresses a broad range of data heterogeneity issues beyond simpler forms of Non-IIDness like label skews. Our clustered FL approach also enables convergence guarantees for non-convex objectives. Our code is available at https://github.com/MMorafah/PACFL.
FLIS: Clustered Federated Learning via Inference Similarity for Non-IID Data Distribution
Aug 20, 2022


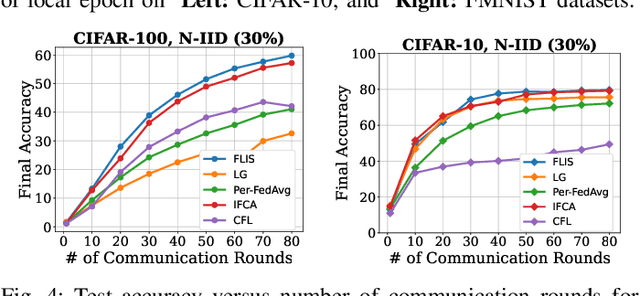
Classical federated learning approaches yield significant performance degradation in the presence of Non-IID data distributions of participants. When the distribution of each local dataset is highly different from the global one, the local objective of each client will be inconsistent with the global optima which incur a drift in the local updates. This phenomenon highly impacts the performance of clients. This is while the primary incentive for clients to participate in federated learning is to obtain better personalized models. To address the above-mentioned issue, we present a new algorithm, FLIS, which groups the clients population in clusters with jointly trainable data distributions by leveraging the inference similarity of clients' models. This framework captures settings where different groups of users have their own objectives (learning tasks) but by aggregating their data with others in the same cluster (same learning task) to perform more efficient and personalized federated learning. We present experimental results to demonstrate the benefits of FLIS over the state-of-the-art benchmarks on CIFAR-100/10, SVHN, and FMNIST datasets. Our code is available at https://github.com/MMorafah/FLIS.
Deep Point Cloud Normal Estimation via Triplet Learning
Oct 20, 2021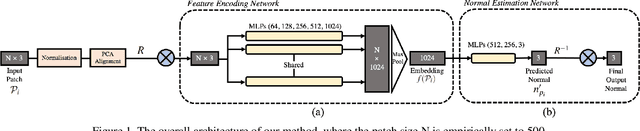

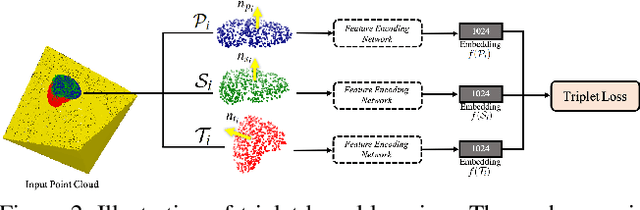

Normal estimation on 3D point clouds is a fundamental problem in 3D vision and graphics. Current methods often show limited accuracy in predicting normals at sharp features (e.g., edges and corners) and less robustness to noise. In this paper, we propose a novel normal estimation method for point clouds. It consists of two phases: (a) feature encoding which learns representations of local patches, and (b) normal estimation that takes the learned representation as input and regresses the normal vector. We are motivated that local patches on isotropic and anisotropic surfaces have similar or distinct normals, and that separable features or representations can be learned to facilitate normal estimation. To realise this, we first construct triplets of local patches on 3D point cloud data, and design a triplet network with a triplet loss for feature encoding. We then design a simple network with several MLPs and a loss function to regress the normal vector. Despite having a smaller network size compared to most other methods, experimental results show that our method preserves sharp features and achieves better normal estimation results on CAD-like shapes.
Learning Accurate and Interpretable Decision Rule Sets from Neural Networks
Mar 12, 2021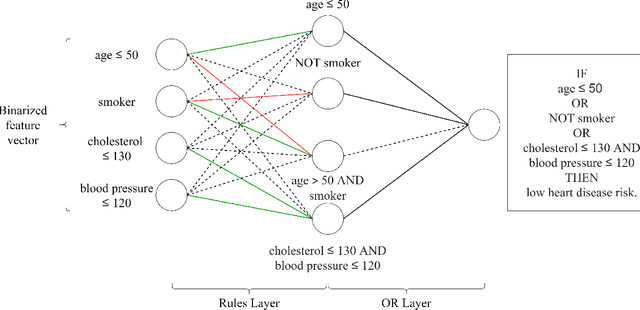
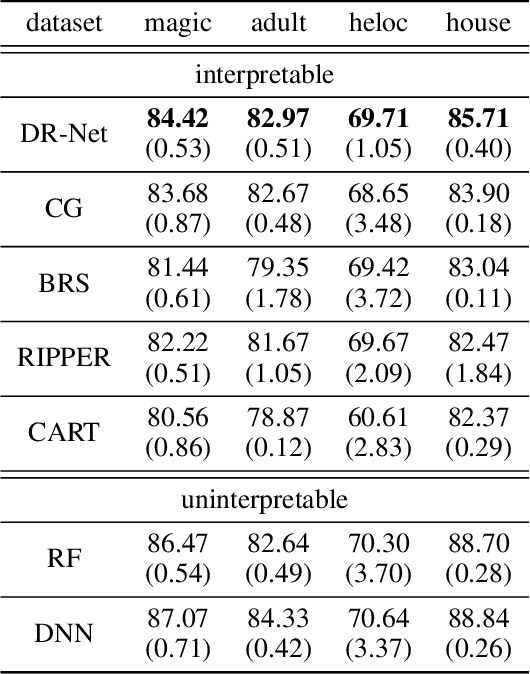
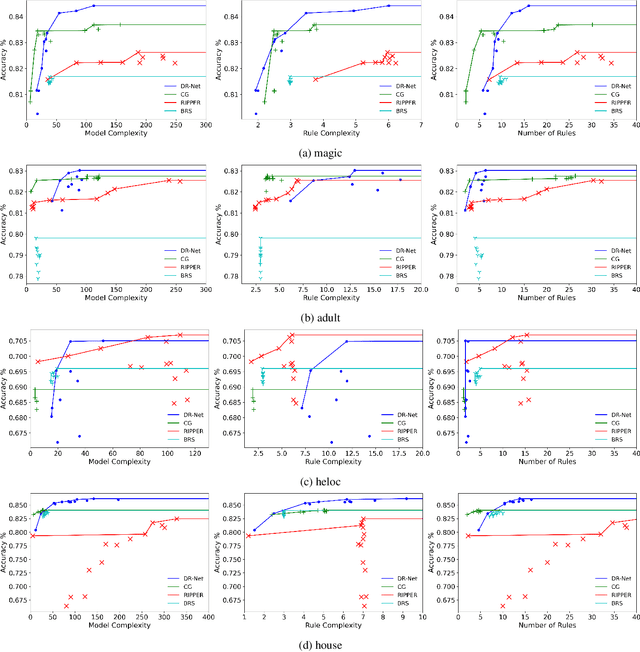

This paper proposes a new paradigm for learning a set of independent logical rules in disjunctive normal form as an interpretable model for classification. We consider the problem of learning an interpretable decision rule set as training a neural network in a specific, yet very simple two-layer architecture. Each neuron in the first layer directly maps to an interpretable if-then rule after training, and the output neuron in the second layer directly maps to a disjunction of the first-layer rules to form the decision rule set. Our representation of neurons in this first rules layer enables us to encode both the positive and the negative association of features in a decision rule. State-of-the-art neural net training approaches can be leveraged for learning highly accurate classification models. Moreover, we propose a sparsity-based regularization approach to balance between classification accuracy and the simplicity of the derived rules. Our experimental results show that our method can generate more accurate decision rule sets than other state-of-the-art rule-learning algorithms with better accuracy-simplicity trade-offs. Further, when compared with uninterpretable black-box machine learning approaches such as random forests and full-precision deep neural networks, our approach can easily find interpretable decision rule sets that have comparable predictive performance.