 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
Plug-and-Play Diffusion Distillation
Jun 04, 2024



Diffusion models have shown tremendous results in image generation. However, due to the iterative nature of the diffusion process and its reliance on classifier-free guidance, inference times are slow. In this paper, we propose a new distillation approach for guided diffusion models in which an external lightweight guide model is trained while the original text-to-image model remains frozen. We show that our method reduces the inference computation of classifier-free guided latent-space diffusion models by almost half, and only requires 1\% trainable parameters of the base model. Furthermore, once trained, our guide model can be applied to various fine-tuned, domain-specific versions of the base diffusion model without the need for additional training: this "plug-and-play" functionality drastically improves inference computation while maintaining the visual fidelity of generated images. Empirically, we show that our approach is able to produce visually appealing results and achieve a comparable FID score to the teacher with as few as 8 to 16 steps.
Guided Co-Modulated GAN for 360° Field of View Extrapolation
Apr 15, 2022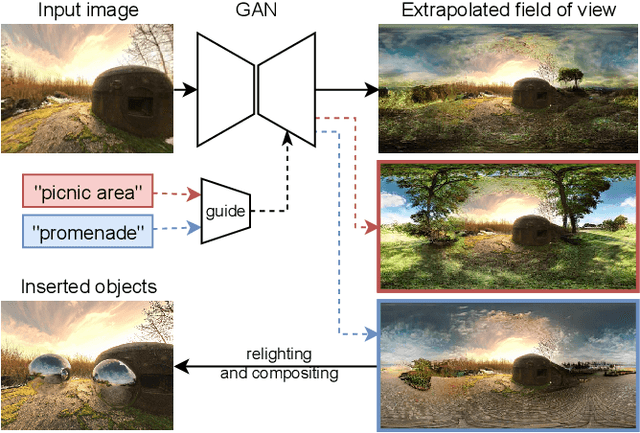
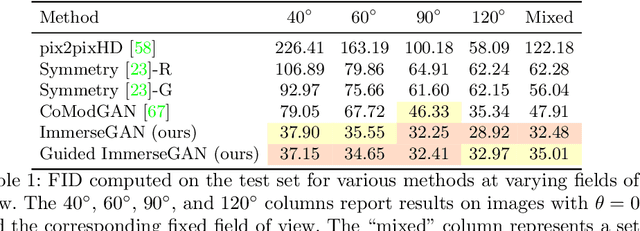


We propose a method to extrapolate a 360{\deg} field of view from a single image that allows for user-controlled synthesis of the out-painted content. To do so, we propose improvements to an existing GAN-based in-painting architecture for out-painting panoramic image representation. Our method obtains state-of-the-art results and outperforms previous methods on standard image quality metrics. To allow controlled synthesis of out-painting, we introduce a novel guided co-modulation framework, which drives the image generation process with a common pretrained discriminative model. Doing so maintains the high visual quality of generated panoramas while enabling user-controlled semantic content in the extrapolated field of view. We demonstrate the state-of-the-art results of our method on field of view extrapolation both qualitatively and quantitatively, providing thorough analysis of our novel editing capabilities. Finally, we demonstrate that our approach benefits the photorealistic virtual insertion of highly glossy objects in photographs.
Predicting infections in the Covid-19 pandemic -- lessons learned
Dec 02, 2021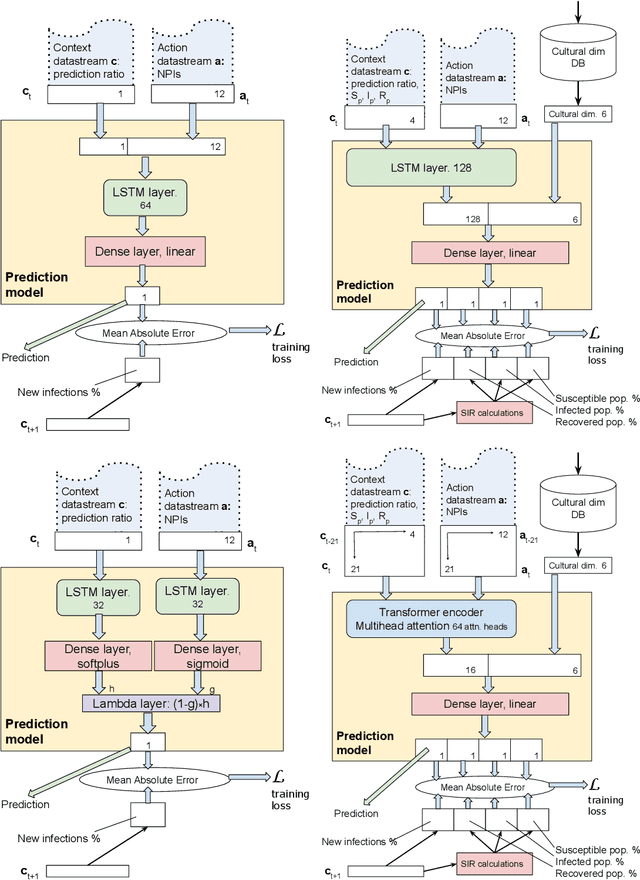
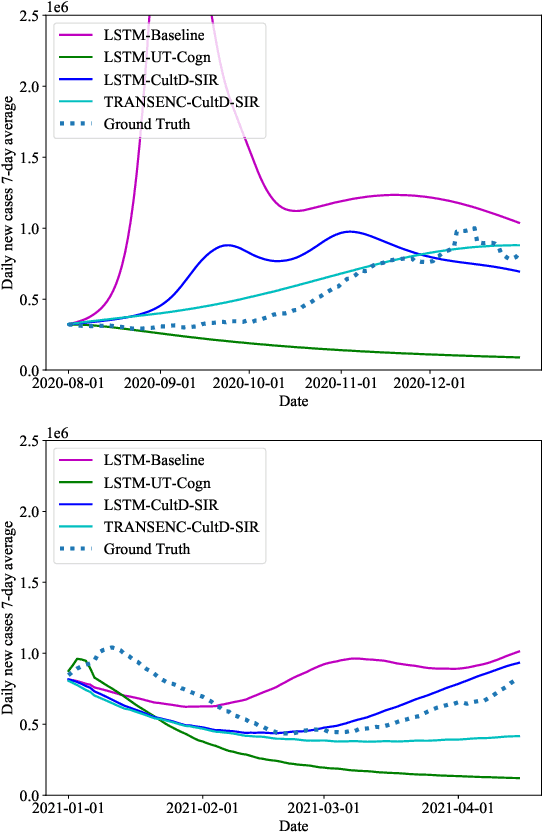

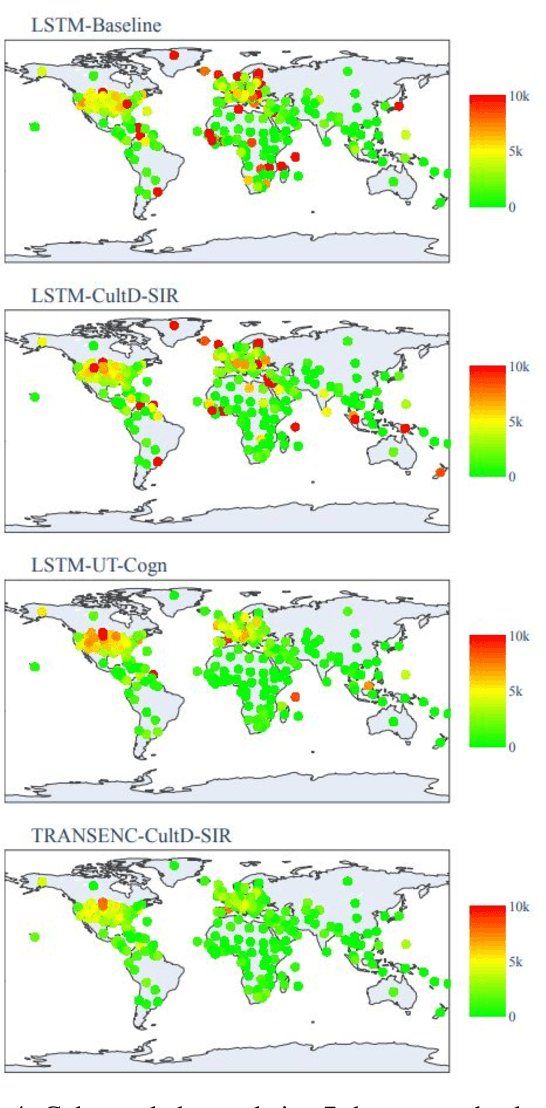
Throughout the Covid-19 pandemic, a significant amount of effort had been put into developing techniques that predict the number of infections under various assumptions about the public policy and non-pharmaceutical interventions. While both the available data and the sophistication of the AI models and available computing power exceed what was available in previous years, the overall success of prediction approaches was very limited. In this paper, we start from prediction algorithms proposed for XPrize Pandemic Response Challenge and consider several directions that might allow their improvement. Then, we investigate their performance over medium-term predictions extending over several months. We find that augmenting the algorithms with additional information about the culture of the modeled region, incorporating traditional compartmental models and up-to-date deep learning architectures can improve the performance for short term predictions, the accuracy of medium-term predictions is still very low and a significant amount of future research is needed to make such models a reliable component of a public policy toolbox.
Privacy-Preserving Learning of Human Activity Predictors in Smart Environments
Jan 17, 2021
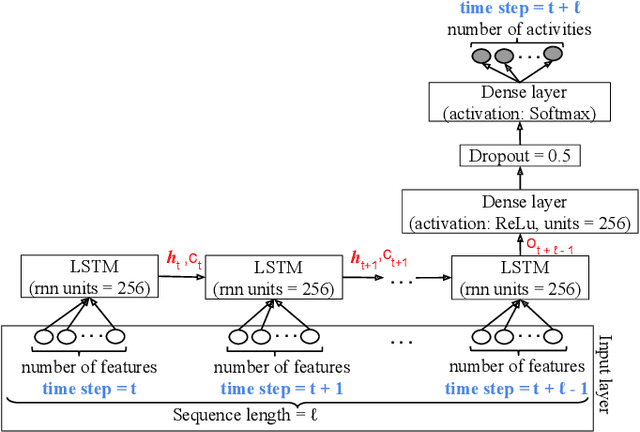

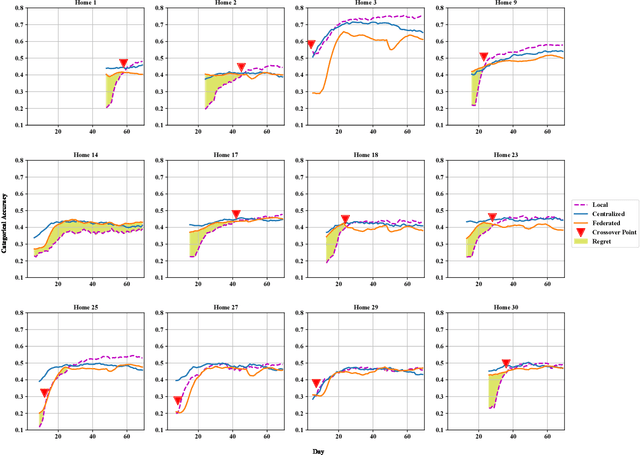
The daily activities performed by a disabled or elderly person can be monitored by a smart environment, and the acquired data can be used to learn a predictive model of user behavior. To speed up the learning, several researchers designed collaborative learning systems that use data from multiple users. However, disclosing the daily activities of an elderly or disabled user raises privacy concerns. In this paper, we use state-of-the-art deep neural network-based techniques to learn predictive human activity models in the local, centralized, and federated learning settings. A novel aspect of our work is that we carefully track the temporal evolution of the data available to the learner and the data shared by the user. In contrast to previous work where users shared all their data with the centralized learner, we consider users that aim to preserve their privacy. Thus, they choose between approaches in order to achieve their goals of predictive accuracy while minimizing the shared data. To help users make decisions before disclosing any data, we use machine learning to predict the degree to which a user would benefit from collaborative learning. We validate our approaches on real-world data.
Unsupervised Meta-Learning through Latent-Space Interpolation in Generative Models
Jun 18, 2020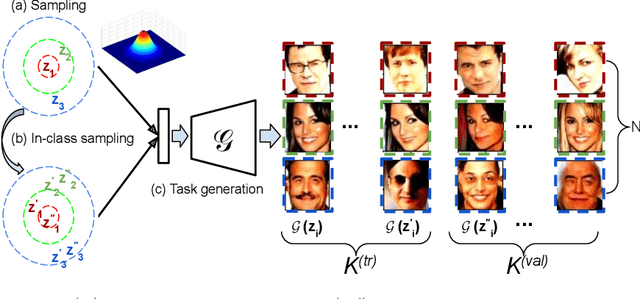

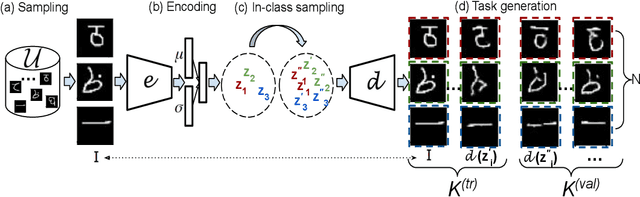
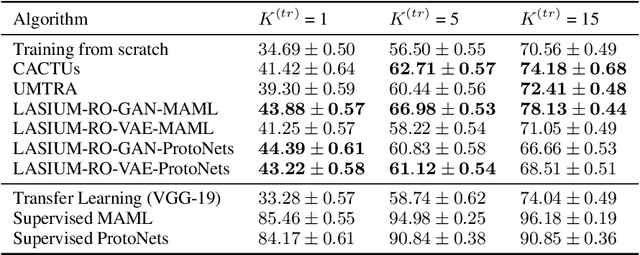
Unsupervised meta-learning approaches rely on synthetic meta-tasks that are created using techniques such as random selection, clustering and/or augmentation. Unfortunately, clustering and augmentation are domain-dependent, and thus they require either manual tweaking or expensive learning. In this work, we describe an approach that generates meta-tasks using generative models. A critical component is a novel approach of sampling from the latent space that generates objects grouped into synthetic classes forming the training and validation data of a meta-task. We find that the proposed approach, LAtent Space Interpolation Unsupervised Meta-learning (LASIUM), outperforms or is competitive with current unsupervised learning baselines on few-shot classification tasks on the most widely used benchmark datasets. In addition, the approach promises to be applicable without manual tweaking over a wider range of domains than previous approaches.
Unsupervised Meta-Learning For Few-Shot Image and Video Classification
Nov 28, 2018



Few-shot or one-shot learning of classifiers for images or videos is an important next frontier in computer vision. The extreme paucity of training data means that the learning must start with a significant inductive bias towards the type of task to be learned. One way to acquire this is by meta-learning on tasks similar to the target task. However, if the meta-learning phase requires labeled data for a large number of tasks closely related to the target task, it not only increases the difficulty and cost, but also conceptually limits the approach to variations of well-understood domains. In this paper, we propose UMTRA, an algorithm that performs meta-learning on an unlabeled dataset in an unsupervised fashion, without putting any constraint on the classifier network architecture. The only requirements towards the dataset are: sufficient size, diversity and number of classes, and relevance of the domain to the one in the target task. Exploiting this information, UMTRA generates synthetic training tasks for the meta-learning phase. We evaluate UMTRA on few-shot and one-shot learning on both image and video domains. To the best of our knowledge, we are the first to evaluate meta-learning approaches on UCF-101. On the Omniglot and Mini-Imagenet few-shot learning benchmarks, UMTRA outperforms every tested approach based on unsupervised learning of representations, while alternating for the best performance with the recent CACTUs algorithm. Compared to supervised model-agnostic meta-learning approaches, UMTRA trades off some classification accuracy for a vast decrease in the number of labeled data needed. For instance, on the five-way one-shot classification on the Omniglot, we retain 85% of the accuracy of MAML, a recently proposed supervised meta-learning algorithm, while reducing the number of required labels from 24005 to 5.