 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpotEdit: Evaluating Visually-Guided Image Editing Methods
Aug 25, 2025Visually-guided image editing, where edits are conditioned on both visual cues and textual prompts, has emerged as a powerful paradigm for fine-grained, controllable content generation. Although recent generative models have shown remarkable capabilities, existing evaluations remain simple and insufficiently representative of real-world editing challenges. We present SpotEdit, a comprehensive benchmark designed to systematically assess visually-guided image editing methods across diverse diffusion, autoregressive, and hybrid generative models, uncovering substantial performance disparities. To address a critical yet underexplored challenge, our benchmark includes a dedicated component on hallucination, highlighting how leading models, such as GPT-4o, often hallucinate the existence of a visual cue and erroneously perform the editing task. Our code and benchmark are publicly released at https://github.com/SaraGhazanfari/SpotEdit.
Plug-and-Play Diffusion Distillation
Jun 04, 2024



Diffusion models have shown tremendous results in image generation. However, due to the iterative nature of the diffusion process and its reliance on classifier-free guidance, inference times are slow. In this paper, we propose a new distillation approach for guided diffusion models in which an external lightweight guide model is trained while the original text-to-image model remains frozen. We show that our method reduces the inference computation of classifier-free guided latent-space diffusion models by almost half, and only requires 1\% trainable parameters of the base model. Furthermore, once trained, our guide model can be applied to various fine-tuned, domain-specific versions of the base diffusion model without the need for additional training: this "plug-and-play" functionality drastically improves inference computation while maintaining the visual fidelity of generated images. Empirically, we show that our approach is able to produce visually appealing results and achieve a comparable FID score to the teacher with as few as 8 to 16 steps.
Interpolated Joint Space Adversarial Training for Robust and Generalizable Defenses
Dec 12, 2021
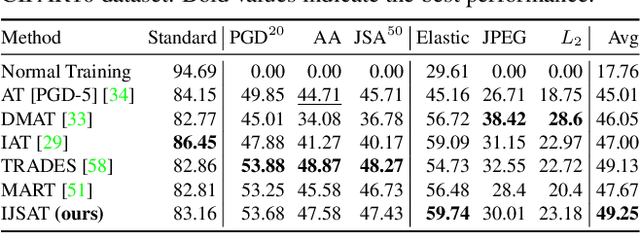
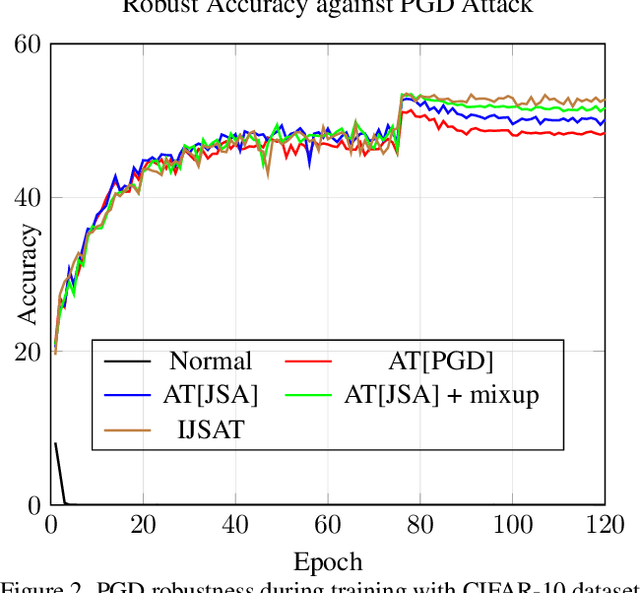
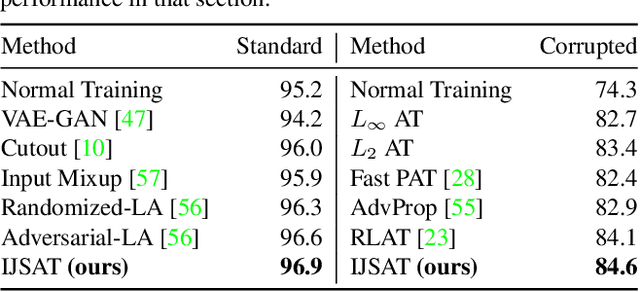
Adversarial training (AT) is considered to be one of the most reliable defenses against adversarial attacks. However, models trained with AT sacrifice standard accuracy and do not generalize well to novel attacks. Recent works show generalization improvement with adversarial samples under novel threat models such as on-manifold threat model or neural perceptual threat model. However, the former requires exact manifold information while the latter requires algorithm relaxation. Motivated by these considerations, we exploit the underlying manifold information with Normalizing Flow, ensuring that exact manifold assumption holds. Moreover, we propose a novel threat model called Joint Space Threat Model (JSTM), which can serve as a special case of the neural perceptual threat model that does not require additional relaxation to craft the corresponding adversarial attacks. Under JSTM, we develop novel adversarial attacks and defenses. The mixup strategy improves the standard accuracy of neural networks but sacrifices robustness when combined with AT. To tackle this issue, we propose the Robust Mixup strategy in which we maximize the adversity of the interpolated images and gain robustness and prevent overfitting. Our experiments show that Interpolated Joint Space Adversarial Training (IJSAT) achieves good performance in standard accuracy, robustness, and generalization in CIFAR-10/100, OM-ImageNet, and CIFAR-10-C datasets. IJSAT is also flexible and can be used as a data augmentation method to improve standard accuracy and combine with many existing AT approaches to improve robustness.
Dual Manifold Adversarial Robustness: Defense against Lp and non-Lp Adversarial Attacks
Sep 05, 2020



Adversarial training is a popular defense strategy against attack threat models with bounded Lp norms. However, it often degrades the model performance on normal images and the defense does not generalize well to novel attacks. Given the success of deep generative models such as GANs and VAEs in characterizing the underlying manifold of images, we investigate whether or not the aforementioned problems can be remedied by exploiting the underlying manifold information. To this end, we construct an "On-Manifold ImageNet" (OM-ImageNet) dataset by projecting the ImageNet samples onto the manifold learned by StyleGSN. For this dataset, the underlying manifold information is exact. Using OM-ImageNet, we first show that adversarial training in the latent space of images improves both standard accuracy and robustness to on-manifold attacks. However, since no out-of-manifold perturbations are realized, the defense can be broken by Lp adversarial attacks. We further propose Dual Manifold Adversarial Training (DMAT) where adversarial perturbations in both latent and image spaces are used in robustifying the model. Our DMAT improves performance on normal images, and achieves comparable robustness to the standard adversarial training against Lp attacks. In addition, we observe that models defended by DMAT achieve improved robustness against novel attacks which manipulate images by global color shifts or various types of image filtering. Interestingly, similar improvements are also achieved when the defended models are tested on out-of-manifold natural images. These results demonstrate the potential benefits of using manifold information in enhancing robustness of deep learning models against various types of novel adversarial attacks.
DuDoNet++: Encoding mask projection to reduce CT metal artifacts
Jan 18, 2020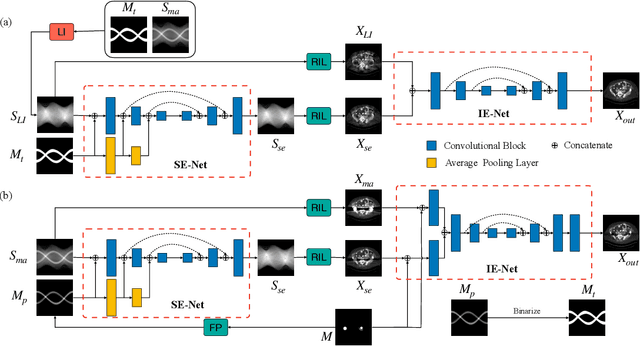

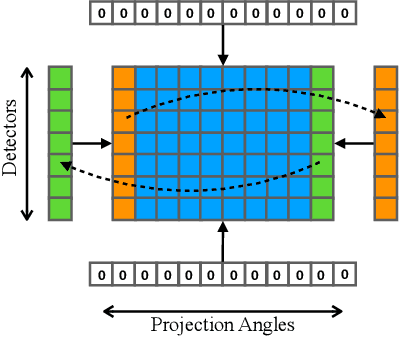

CT metal artifact reduction (MAR) is a notoriously challenging task because the artifacts are structured and non-local in the image domain. However, they are inherently local in the sinogram domain. DuDoNet is the state-of-the-art MAR algorithm which exploits the latter characteristic by learning to reduce artifacts in the sinogram and image domain jointly. By design, DuDoNet treats the metal-affected regions in sinogram as missing and replaces them with the surrogate data generated by a neural network. Since fine-grained details within the metal-affected regions are completely ignored, the artifact-reduced CT images by DuDoNet tend to be over-smoothed and distorted. In this work, we investigate the issue by theoretical derivation. We propose to address the problem by (1) retaining the metal-affected regions in sinogram and (2) replacing the binarized metal trace with the metal mask projection such that the geometry information of metal implants is encoded. Extensive experiments on simulated datasets and expert evaluations on clinical images demonstrate that our network called DuDoNet++ yields anatomically more precise artifact-reduced images than DuDoNet, especially when the metallic objects are large.
Invert and Defend: Model-based Approximate Inversion of Generative Adversarial Networks for Secure Inference
Nov 23, 2019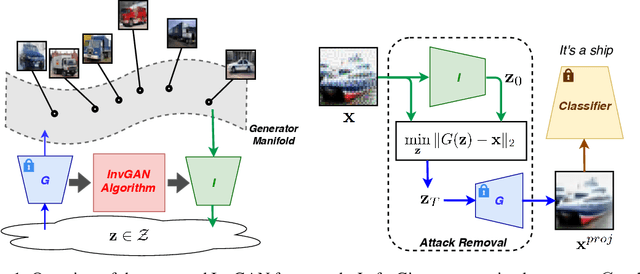
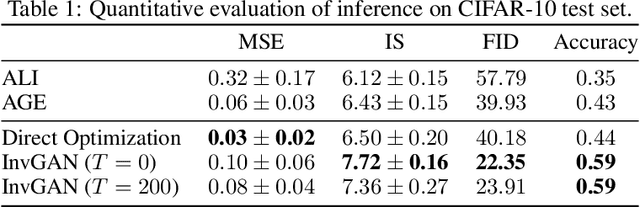
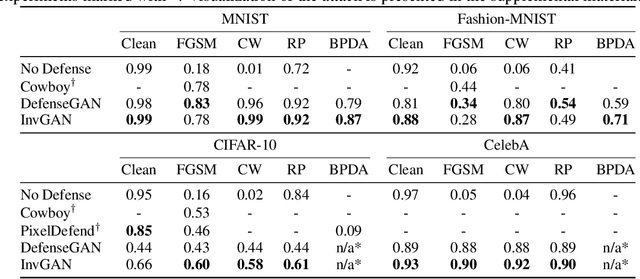
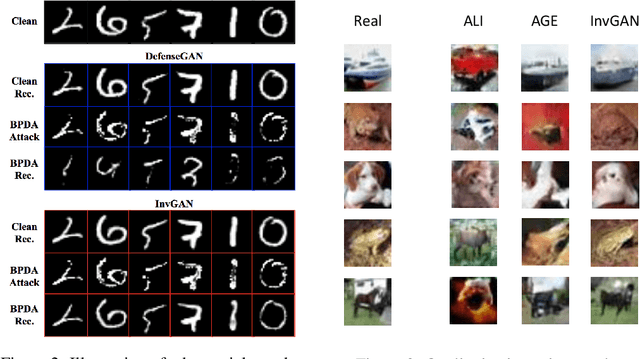
Inferring the latent variable generating a given test sample is a challenging problem in Generative Adversarial Networks (GANs). In this paper, we propose InvGAN - a novel framework for solving the inference problem in GANs, which involves training an encoder network capable of inverting a pre-trained generator network without access to any training data. Under mild assumptions, we theoretically show that using InvGAN, we can approximately invert the generations of any latent code of a trained GAN model. Furthermore, we empirically demonstrate the superiority of our inference scheme by quantitative and qualitative comparisons with other methods that perform a similar task. We also show the effectiveness of our framework in the problem of adversarial defenses where InvGAN can successfully be used as a projection-based defense mechanism. Additionally, we show how InvGAN can be used to implement reparameterization white-box attacks on projection-based defense mechanisms. Experimental validation on several benchmark datasets demonstrate the efficacy of our method in achieving improved performance on several white-box and black-box attacks. Our code is available at https://github.com/yogeshbalaji/InvGAN.
Towards multi-sequence MR image recovery from undersampled k-space data
Aug 16, 2019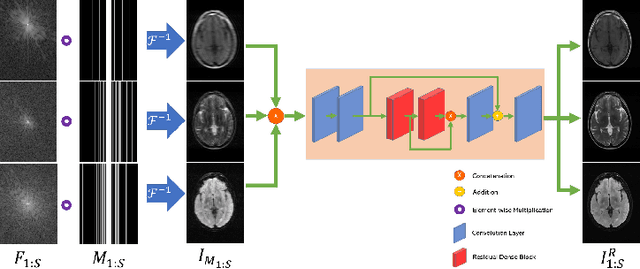
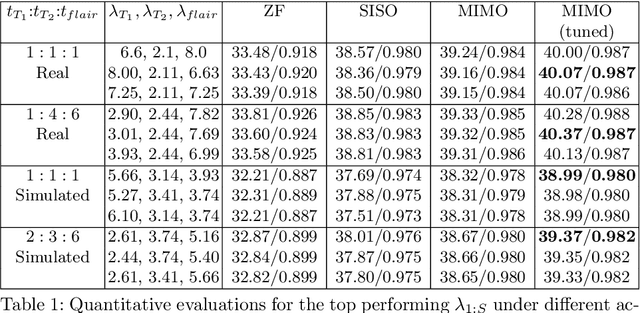
Undersampled MR image recovery has been widely studied for accelerated MR acquisition. However, it has been mostly studied under a single sequence scenario, despite the fact that multi-sequence MR scan is common in practice. In this paper, we aim to optimize multi-sequence MR image recovery from undersampled k-space data under an overall time constraint while considering the difference in acquisition time for various sequences. We first formulate it as a constrained optimization problem and then show that finding the optimal sampling strategy for all sequences and the best recovery model at the same time is combinatorial and hence computationally prohibitive. To solve this problem, we propose a blind recovery model that simultaneously recovers multiple sequences, and an efficient approach to find proper combination of sampling strategy and recovery model. Our experiments demonstrate that the proposed method outperforms sequence-wise recovery, and sheds light on how to decide the undersampling strategy for sequences within an overall time budget.
Deep Slice Interpolation via Marginal Super-Resolution, Fusion and Refinement
Aug 15, 2019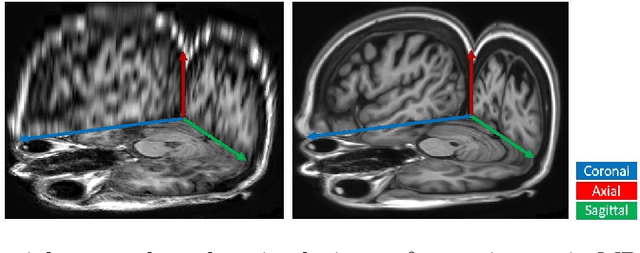
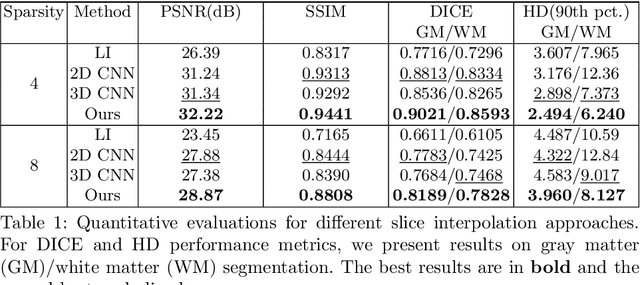
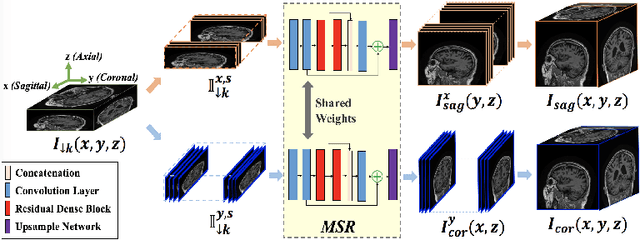

We propose a marginal super-resolution (MSR) approach based on 2D convolutional neural networks (CNNs) for interpolating an anisotropic brain magnetic resonance scan along the highly under-sampled direction, which is assumed to axial without loss of generality. Previous methods for slice interpolation only consider data from pairs of adjacent 2D slices. The possibility of fusing information from the direction orthogonal to the 2D slices remains unexplored. Our approach performs MSR in both sagittal and coronal directions, which provides an initial estimate for slice interpolation. The interpolated slices are then fused and refined in the axial direction for improved consistency. Since MSR consists of only 2D operations, it is more feasible in terms of GPU memory consumption and requires fewer training samples compared to 3D CNNs. Our experiments demonstrate that the proposed method outperforms traditional linear interpolation and baseline 2D/3D CNN-based approaches. We conclude by showcasing the method's practical utility in estimating brain volumes from under-sampled brain MR scans through semantic segmentation.
ADN: Artifact Disentanglement Network for Unsupervised Metal Artifact Reduction
Aug 08, 2019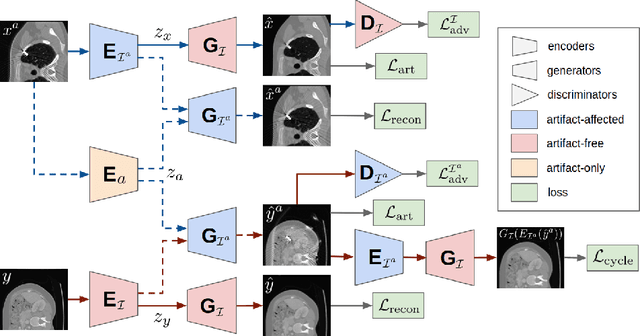
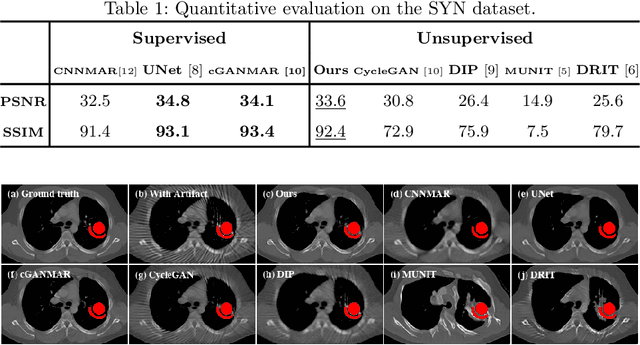

Current deep neural network based approaches to computed tomography (CT) metal artifact reduction (MAR) are supervised methods that rely on synthesized metal artifacts for training. However, as synthesized data may not accurately simulate the underlying physical mechanisms of CT imaging, the supervised methods often generalize poorly to clinical applications. To address this problem, we propose, to the best of our knowledge, the first unsupervised learning approach to MAR. Specifically, we introduce a novel artifact disentanglement network that disentangles the metal artifacts from CT images in the latent space. It supports different forms of generations (artifact reduction, artifact transfer, and self-reconstruction, etc.) with specialized loss functions to obviate the need for supervision with synthesized data. Extensive experiments show that when applied to a synthesized dataset, our method addresses metal artifacts significantly better than the existing unsupervised models designed for natural image-to-image translation problems, and achieves comparable performance to existing supervised models for MAR. When applied to clinical datasets, our method demonstrates better generalization ability over the supervised models. The source code of this paper is publicly available at https://github.com/liaohaofu/adn.
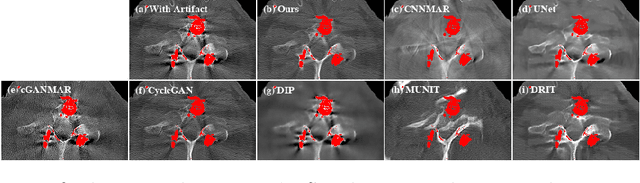
Generative Mask Pyramid Network for CT/CBCT Metal Artifact Reduction with Joint Projection-Sinogram Correction
Jul 06, 2019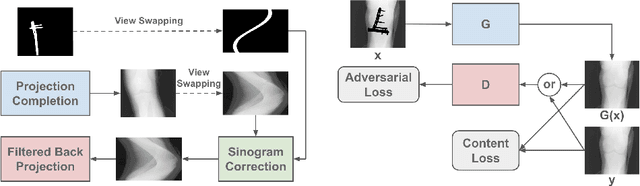
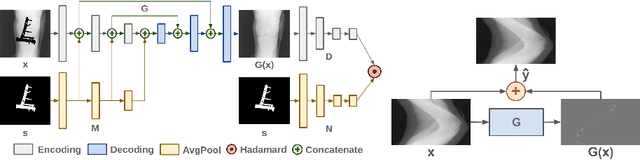
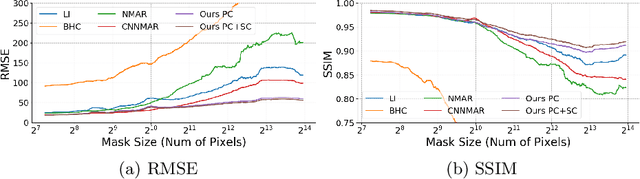
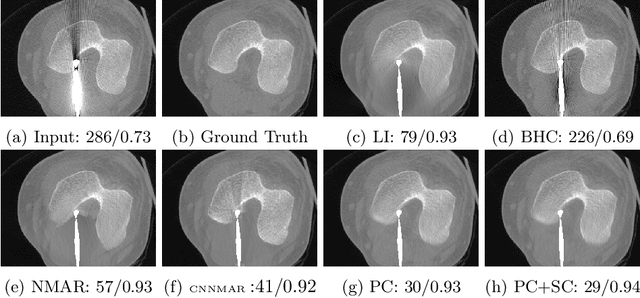
A conventional approach to computed tomography (CT) or cone beam CT (CBCT) metal artifact reduction is to replace the X-ray projection data within the metal trace with synthesized data. However, existing projection or sinogram completion methods cannot always produce anatomically consistent information to fill the metal trace, and thus, when the metallic implant is large, significant secondary artifacts are often introduced. In this work, we propose to replace metal artifact affected regions with anatomically consistent content through joint projection-sinogram correction as well as adversarial learning. To handle the metallic implants of diverse shapes and large sizes, we also propose a novel mask pyramid network that enforces the mask information across the network's encoding layers and a mask fusion loss that reduces early saturation of adversarial training. Our experimental results show that the proposed projection-sinogram correction designs are effective and our method recovers information from the metal traces better than the state-of-the-art methods.