 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpotEdit: Evaluating Visually-Guided Image Editing Methods
Aug 25, 2025Visually-guided image editing, where edits are conditioned on both visual cues and textual prompts, has emerged as a powerful paradigm for fine-grained, controllable content generation. Although recent generative models have shown remarkable capabilities, existing evaluations remain simple and insufficiently representative of real-world editing challenges. We present SpotEdit, a comprehensive benchmark designed to systematically assess visually-guided image editing methods across diverse diffusion, autoregressive, and hybrid generative models, uncovering substantial performance disparities. To address a critical yet underexplored challenge, our benchmark includes a dedicated component on hallucination, highlighting how leading models, such as GPT-4o, often hallucinate the existence of a visual cue and erroneously perform the editing task. Our code and benchmark are publicly released at https://github.com/SaraGhazanfari/SpotEdit.
Towards Unified Benchmark and Models for Multi-Modal Perceptual Metrics
Dec 13, 2024



Human perception of similarity across uni- and multimodal inputs is highly complex, making it challenging to develop automated metrics that accurately mimic it. General purpose vision-language models, such as CLIP and large multi-modal models (LMMs), can be applied as zero-shot perceptual metrics, and several recent works have developed models specialized in narrow perceptual tasks. However, the extent to which existing perceptual metrics align with human perception remains unclear. To investigate this question, we introduce UniSim-Bench, a benchmark encompassing 7 multi-modal perceptual similarity tasks, with a total of 25 datasets. Our evaluation reveals that while general-purpose models perform reasonably well on average, they often lag behind specialized models on individual tasks. Conversely, metrics fine-tuned for specific tasks fail to generalize well to unseen, though related, tasks. As a first step towards a unified multi-task perceptual similarity metric, we fine-tune both encoder-based and generative vision-language models on a subset of the UniSim-Bench tasks. This approach yields the highest average performance, and in some cases, even surpasses taskspecific models. Nevertheless, these models still struggle with generalization to unseen tasks, highlighting the ongoing challenge of learning a robust, unified perceptual similarity metric capable of capturing the human notion of similarity. The code and models are available at https://github.com/SaraGhazanfari/UniSim.
EMMA: Efficient Visual Alignment in Multi-Modal LLMs
Oct 02, 2024



Multi-modal Large Language Models (MLLMs) have recently exhibited impressive general-purpose capabilities by leveraging vision foundation models to encode the core concepts of images into representations. These are then combined with instructions and processed by the language model to generate high-quality responses. Despite significant progress in enhancing the language component, challenges persist in optimally fusing visual encodings within the language model for task-specific adaptability. Recent research has focused on improving this fusion through modality adaptation modules but at the cost of significantly increased model complexity and training data needs. In this paper, we propose EMMA (Efficient Multi-Modal Adaptation), a lightweight cross-modality module designed to efficiently fuse visual and textual encodings, generating instruction-aware visual representations for the language model. Our key contributions include: (1) an efficient early fusion mechanism that integrates vision and language representations with minimal added parameters (less than 0.2% increase in model size), (2) an in-depth interpretability analysis that sheds light on the internal mechanisms of the proposed method; (3) comprehensive experiments that demonstrate notable improvements on both specialized and general benchmarks for MLLMs. Empirical results show that EMMA boosts performance across multiple tasks by up to 9.3% while significantly improving robustness against hallucinations. Our code is available at https://github.com/SaraGhazanfari/EMMA
LipSim: A Provably Robust Perceptual Similarity Metric
Oct 27, 2023



Recent years have seen growing interest in developing and applying perceptual similarity metrics. Research has shown the superiority of perceptual metrics over pixel-wise metrics in aligning with human perception and serving as a proxy for the human visual system. On the other hand, as perceptual metrics rely on neural networks, there is a growing concern regarding their resilience, given the established vulnerability of neural networks to adversarial attacks. It is indeed logical to infer that perceptual metrics may inherit both the strengths and shortcomings of neural networks. In this work, we demonstrate the vulnerability of state-of-the-art perceptual similarity metrics based on an ensemble of ViT-based feature extractors to adversarial attacks. We then propose a framework to train a robust perceptual similarity metric called LipSim (Lipschitz Similarity Metric) with provable guarantees. By leveraging 1-Lipschitz neural networks as the backbone, LipSim provides guarded areas around each data point and certificates for all perturbations within an $\ell_2$ ball. Finally, a comprehensive set of experiments shows the performance of LipSim in terms of natural and certified scores and on the image retrieval application. The code is available at https://github.com/SaraGhazanfari/LipSim.
R-LPIPS: An Adversarially Robust Perceptual Similarity Metric
Jul 31, 2023



Similarity metrics have played a significant role in computer vision to capture the underlying semantics of images. In recent years, advanced similarity metrics, such as the Learned Perceptual Image Patch Similarity (LPIPS), have emerged. These metrics leverage deep features extracted from trained neural networks and have demonstrated a remarkable ability to closely align with human perception when evaluating relative image similarity. However, it is now well-known that neural networks are susceptible to adversarial examples, i.e., small perturbations invisible to humans crafted to deliberately mislead the model. Consequently, the LPIPS metric is also sensitive to such adversarial examples. This susceptibility introduces significant security concerns, especially considering the widespread adoption of LPIPS in large-scale applications. In this paper, we propose the Robust Learned Perceptual Image Patch Similarity (R-LPIPS) metric, a new metric that leverages adversarially trained deep features. Through a comprehensive set of experiments, we demonstrate the superiority of R-LPIPS compared to the classical LPIPS metric. The code is available at https://github.com/SaraGhazanfari/R-LPIPS.
Isoform Function Prediction Using Deep Neural Network
Aug 05, 2022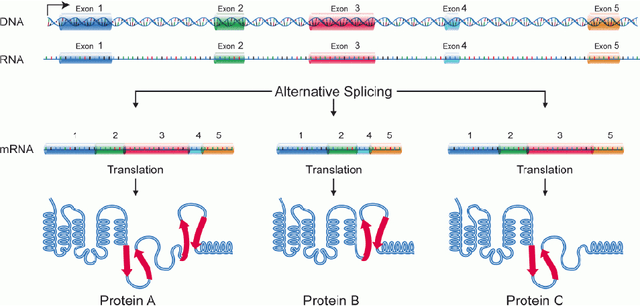
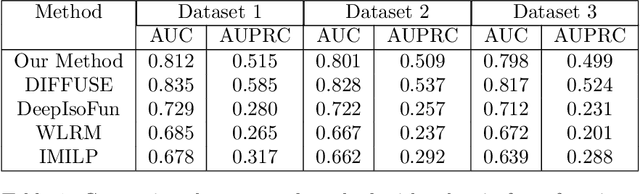
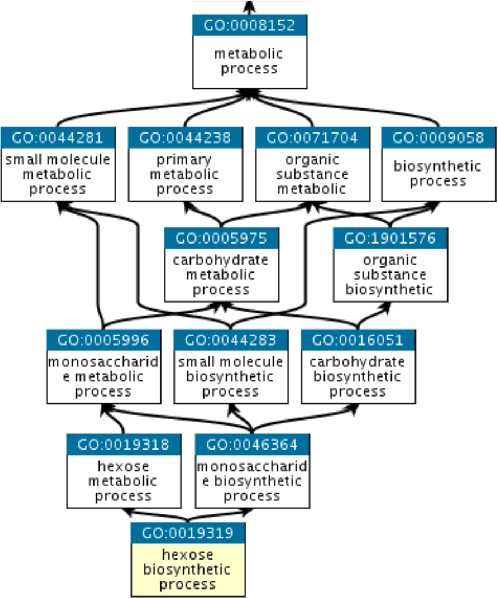
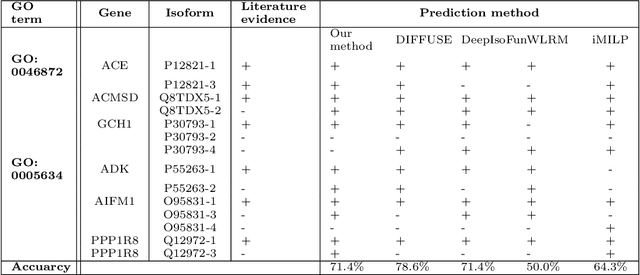
Isoforms are mRNAs produced from the same gene site in the phenomenon called Alternative Splicing. Studies have shown that more than 95% of human multi-exon genes have undergone alternative splicing. Although there are few changes in mRNA sequence, They may have a systematic effect on cell function and regulation. It is widely reported that isoforms of a gene have distinct or even contrasting functions. Most studies have shown that alternative splicing plays a significant role in human health and disease. Despite the wide range of gene function studies, there is little information about isoforms' functionalities. Recently, some computational methods based on Multiple Instance Learning have been proposed to predict isoform function using gene function and gene expression profile. However, their performance is not desirable due to the lack of labeled training data. In addition, probabilistic models such as Conditional Random Field (CRF) have been used to model the relation between isoforms. This project uses all the data and valuable information such as isoform sequences, expression profiles, and gene ontology graphs and proposes a comprehensive model based on Deep Neural Networks. The UniProt Gene Ontology (GO) database is used as a standard reference for gene functions. The NCBI RefSeq database is used for extracting gene and isoform sequences, and the NCBI SRA database is used for expression profile data. Metrics such as Receiver Operating Characteristic Area Under the Curve (ROC AUC) and Precision-Recall Under the Curve (PR AUC) are used to measure the prediction accuracy.