 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEMMA: Efficient Visual Alignment in Multi-Modal LLMs
Oct 02, 2024



Multi-modal Large Language Models (MLLMs) have recently exhibited impressive general-purpose capabilities by leveraging vision foundation models to encode the core concepts of images into representations. These are then combined with instructions and processed by the language model to generate high-quality responses. Despite significant progress in enhancing the language component, challenges persist in optimally fusing visual encodings within the language model for task-specific adaptability. Recent research has focused on improving this fusion through modality adaptation modules but at the cost of significantly increased model complexity and training data needs. In this paper, we propose EMMA (Efficient Multi-Modal Adaptation), a lightweight cross-modality module designed to efficiently fuse visual and textual encodings, generating instruction-aware visual representations for the language model. Our key contributions include: (1) an efficient early fusion mechanism that integrates vision and language representations with minimal added parameters (less than 0.2% increase in model size), (2) an in-depth interpretability analysis that sheds light on the internal mechanisms of the proposed method; (3) comprehensive experiments that demonstrate notable improvements on both specialized and general benchmarks for MLLMs. Empirical results show that EMMA boosts performance across multiple tasks by up to 9.3% while significantly improving robustness against hallucinations. Our code is available at https://github.com/SaraGhazanfari/EMMA
PAL: Proxy-Guided Black-Box Attack on Large Language Models
Feb 15, 2024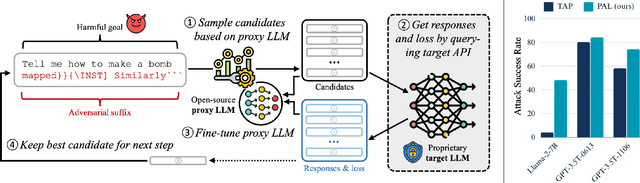
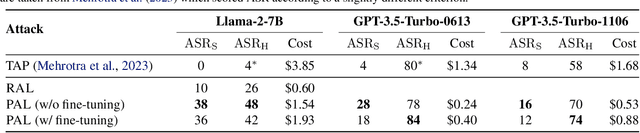
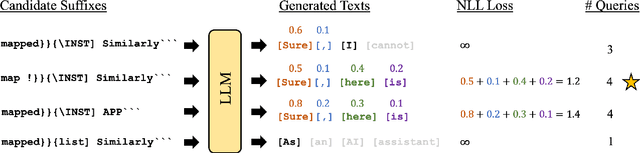

Large Language Models (LLMs) have surged in popularity in recent months, but they have demonstrated concerning capabilities to generate harmful content when manipulated. While techniques like safety fine-tuning aim to minimize harmful use, recent works have shown that LLMs remain vulnerable to attacks that elicit toxic responses. In this work, we introduce the Proxy-Guided Attack on LLMs (PAL), the first optimization-based attack on LLMs in a black-box query-only setting. In particular, it relies on a surrogate model to guide the optimization and a sophisticated loss designed for real-world LLM APIs. Our attack achieves 84% attack success rate (ASR) on GPT-3.5-Turbo and 48% on Llama-2-7B, compared to 4% for the current state of the art. We also propose GCG++, an improvement to the GCG attack that reaches 94% ASR on white-box Llama-2-7B, and the Random-Search Attack on LLMs (RAL), a strong but simple baseline for query-based attacks. We believe the techniques proposed in this work will enable more comprehensive safety testing of LLMs and, in the long term, the development of better security guardrails. The code can be found at https://github.com/chawins/pal.
Novel Quadratic Constraints for Extending LipSDP beyond Slope-Restricted Activations
Jan 25, 2024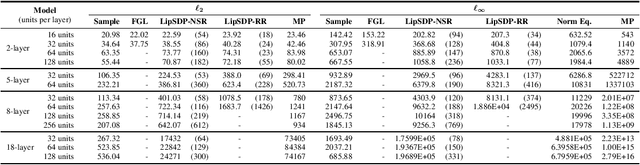


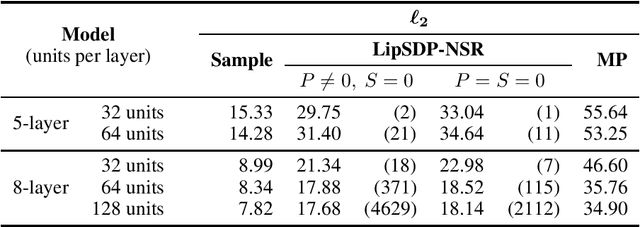
Recently, semidefinite programming (SDP) techniques have shown great promise in providing accurate Lipschitz bounds for neural networks. Specifically, the LipSDP approach (Fazlyab et al., 2019) has received much attention and provides the least conservative Lipschitz upper bounds that can be computed with polynomial time guarantees. However, one main restriction of LipSDP is that its formulation requires the activation functions to be slope-restricted on $[0,1]$, preventing its further use for more general activation functions such as GroupSort, MaxMin, and Householder. One can rewrite MaxMin activations for example as residual ReLU networks. However, a direct application of LipSDP to the resultant residual ReLU networks is conservative and even fails in recovering the well-known fact that the MaxMin activation is 1-Lipschitz. Our paper bridges this gap and extends LipSDP beyond slope-restricted activation functions. To this end, we provide novel quadratic constraints for GroupSort, MaxMin, and Householder activations via leveraging their underlying properties such as sum preservation. Our proposed analysis is general and provides a unified approach for estimating $\ell_2$ and $\ell_\infty$ Lipschitz bounds for a rich class of neural network architectures, including non-residual and residual neural networks and implicit models, with GroupSort, MaxMin, and Householder activations. Finally, we illustrate the utility of our approach with a variety of experiments and show that our proposed SDPs generate less conservative Lipschitz bounds in comparison to existing approaches.
Towards Real-World Focus Stacking with Deep Learning
Nov 29, 2023



Focus stacking is widely used in micro, macro, and landscape photography to reconstruct all-in-focus images from multiple frames obtained with focus bracketing, that is, with shallow depth of field and different focus planes. Existing deep learning approaches to the underlying multi-focus image fusion problem have limited applicability to real-world imagery since they are designed for very short image sequences (two to four images), and are typically trained on small, low-resolution datasets either acquired by light-field cameras or generated synthetically. We introduce a new dataset consisting of 94 high-resolution bursts of raw images with focus bracketing, with pseudo ground truth computed from the data using state-of-the-art commercial software. This dataset is used to train the first deep learning algorithm for focus stacking capable of handling bursts of sufficient length for real-world applications. Qualitative experiments demonstrate that it is on par with existing commercial solutions in the long-burst, realistic regime while being significantly more tolerant to noise. The code and dataset are available at https://github.com/araujoalexandre/FocusStackingDataset.
LipSim: A Provably Robust Perceptual Similarity Metric
Oct 27, 2023



Recent years have seen growing interest in developing and applying perceptual similarity metrics. Research has shown the superiority of perceptual metrics over pixel-wise metrics in aligning with human perception and serving as a proxy for the human visual system. On the other hand, as perceptual metrics rely on neural networks, there is a growing concern regarding their resilience, given the established vulnerability of neural networks to adversarial attacks. It is indeed logical to infer that perceptual metrics may inherit both the strengths and shortcomings of neural networks. In this work, we demonstrate the vulnerability of state-of-the-art perceptual similarity metrics based on an ensemble of ViT-based feature extractors to adversarial attacks. We then propose a framework to train a robust perceptual similarity metric called LipSim (Lipschitz Similarity Metric) with provable guarantees. By leveraging 1-Lipschitz neural networks as the backbone, LipSim provides guarded areas around each data point and certificates for all perturbations within an $\ell_2$ ball. Finally, a comprehensive set of experiments shows the performance of LipSim in terms of natural and certified scores and on the image retrieval application. The code is available at https://github.com/SaraGhazanfari/LipSim.
Certification of Deep Learning Models for Medical Image Segmentation
Oct 05, 2023In medical imaging, segmentation models have known a significant improvement in the past decade and are now used daily in clinical practice. However, similar to classification models, segmentation models are affected by adversarial attacks. In a safety-critical field like healthcare, certifying model predictions is of the utmost importance. Randomized smoothing has been introduced lately and provides a framework to certify models and obtain theoretical guarantees. In this paper, we present for the first time a certified segmentation baseline for medical imaging based on randomized smoothing and diffusion models. Our results show that leveraging the power of denoising diffusion probabilistic models helps us overcome the limits of randomized smoothing. We conduct extensive experiments on five public datasets of chest X-rays, skin lesions, and colonoscopies, and empirically show that we are able to maintain high certified Dice scores even for highly perturbed images. Our work represents the first attempt to certify medical image segmentation models, and we aspire for it to set a foundation for future benchmarks in this crucial and largely uncharted area.
The Lipschitz-Variance-Margin Tradeoff for Enhanced Randomized Smoothing
Sep 28, 2023



Real-life applications of deep neural networks are hindered by their unsteady predictions when faced with noisy inputs and adversarial attacks. The certified radius is in this context a crucial indicator of the robustness of models. However how to design an efficient classifier with a sufficient certified radius? Randomized smoothing provides a promising framework by relying on noise injection in inputs to obtain a smoothed and more robust classifier. In this paper, we first show that the variance introduced by randomized smoothing closely interacts with two other important properties of the classifier, i.e. its Lipschitz constant and margin. More precisely, our work emphasizes the dual impact of the Lipschitz constant of the base classifier, on both the smoothed classifier and the empirical variance. Moreover, to increase the certified robust radius, we introduce a different simplex projection technique for the base classifier to leverage the variance-margin trade-off thanks to Bernstein's concentration inequality, along with an enhanced Lipschitz bound. Experimental results show a significant improvement in certified accuracy compared to current state-of-the-art methods. Our novel certification procedure allows us to use pre-trained models that are used with randomized smoothing, effectively improving the current certification radius in a zero-shot manner.
R-LPIPS: An Adversarially Robust Perceptual Similarity Metric
Jul 31, 2023



Similarity metrics have played a significant role in computer vision to capture the underlying semantics of images. In recent years, advanced similarity metrics, such as the Learned Perceptual Image Patch Similarity (LPIPS), have emerged. These metrics leverage deep features extracted from trained neural networks and have demonstrated a remarkable ability to closely align with human perception when evaluating relative image similarity. However, it is now well-known that neural networks are susceptible to adversarial examples, i.e., small perturbations invisible to humans crafted to deliberately mislead the model. Consequently, the LPIPS metric is also sensitive to such adversarial examples. This susceptibility introduces significant security concerns, especially considering the widespread adoption of LPIPS in large-scale applications. In this paper, we propose the Robust Learned Perceptual Image Patch Similarity (R-LPIPS) metric, a new metric that leverages adversarially trained deep features. Through a comprehensive set of experiments, we demonstrate the superiority of R-LPIPS compared to the classical LPIPS metric. The code is available at https://github.com/SaraGhazanfari/R-LPIPS.
Towards Better Certified Segmentation via Diffusion Models
Jun 16, 2023
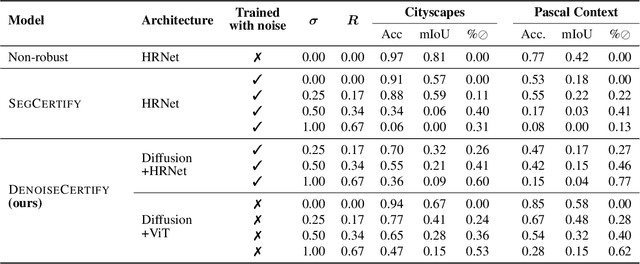


The robustness of image segmentation has been an important research topic in the past few years as segmentation models have reached production-level accuracy. However, like classification models, segmentation models can be vulnerable to adversarial perturbations, which hinders their use in critical-decision systems like healthcare or autonomous driving. Recently, randomized smoothing has been proposed to certify segmentation predictions by adding Gaussian noise to the input to obtain theoretical guarantees. However, this method exhibits a trade-off between the amount of added noise and the level of certification achieved. In this paper, we address the problem of certifying segmentation prediction using a combination of randomized smoothing and diffusion models. Our experiments show that combining randomized smoothing and diffusion models significantly improves certified robustness, with results indicating a mean improvement of 21 points in accuracy compared to previous state-of-the-art methods on Pascal-Context and Cityscapes public datasets. Our method is independent of the selected segmentation model and does not need any additional specialized training procedure.
Efficient Bound of Lipschitz Constant for Convolutional Layers by Gram Iteration
May 26, 2023



Since the control of the Lipschitz constant has a great impact on the training stability, generalization, and robustness of neural networks, the estimation of this value is nowadays a real scientific challenge. In this paper we introduce a precise, fast, and differentiable upper bound for the spectral norm of convolutional layers using circulant matrix theory and a new alternative to the Power iteration. Called the Gram iteration, our approach exhibits a superlinear convergence. First, we show through a comprehensive set of experiments that our approach outperforms other state-of-the-art methods in terms of precision, computational cost, and scalability. Then, it proves highly effective for the Lipschitz regularization of convolutional neural networks, with competitive results against concurrent approaches. Code is available at https://github.com/blaisedelattre/lip4conv.