 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeb Agents Should Adopt the Plan-Then-Execute Paradigm
May 14, 2026ReAct has become the default architecture across LLM agents, and many existing web agents follow this paradigm. We argue that it is the wrong default for web agents. Instead, web agents should default to plan-then-execute: commit to a task-specific program before observing runtime web content, then execute it. The reason is that web content mixes inputs from many parties. An e-commerce product page may combine a seller's listing, customer reviews and sponsored advertisements. Under ReAct, all of this content flows into the model when deciding on the next action, creating a direct path for prompt injections to steer the agent's control flow. Plan-then-execute changes this boundary: untrusted data may influence values or branches inside a predefined execution graph, but it cannot redefine the user task or cause the model to synthesize new actions at runtime. We analyze WebArena, a popular web agent benchmark, and find that all tasks are compatible with plan-then-execute, while 80% can be completed with a purely programmatic plan, without any runtime LLM subroutine. We identify the main barrier to adopting plan-then-execute on the web: For it to work well, tools must map cleanly to semantic actions, with effects known before execution, so agents have enough information to plan. The web does not naturally expose that interface. Browser tools such as click, type, and scroll have page-dependent meanings. Planning at this layer is near-sighted: the agent can only see actions on the current page, and later actions appear only after it acts. Closing this gap requires typed interfaces that turn website interactions from clicks and keystrokes to task-level operations. This is an infrastructure problem, not a modeling problem. Web tasks do not need reactivity by default; they need typed, complete, auditable website APIs.
GradShield: Alignment Preserving Finetuning
May 13, 2026Large Language Models (LLMs) pose a significant risk of safety misalignment after finetuning, as models can be compromised by both explicitly and implicitly harmful data. Even some seemingly benign data can inadvertently steer a model towards misaligned behaviors. To address this, we introduce GradShield, a principled filtering method that safeguards LLMs during finetuning by identifying and removing harmful data points before they corrupt the model's alignment. It removes potentially harmful data by computing a Finetuning Implicit Harmfulness Score (FIHS) for each data point and employs an adaptive thresholding algorithm. We apply GradShield to multiple utility fine-tuning tasks across varying levels of harmful data and evaluate the safety and utility performance of the resulting LLMs using various metrics. The results show that GradShield outperforms all baseline methods, consistently maintaining an Attack Success Rate (ASR) below $6\%$ while preserving utility performance.
Trojan Hippo: Weaponizing Agent Memory for Data Exfiltration
May 05, 2026Memory systems enable otherwise-stateless LLM agents to persist user information across sessions, but also introduce a new attack surface. We characterize the Trojan Hippo attack, a class of persistent memory attacks that operates in a more realistic threat model than prior memory poisoning work: the attacker plants a dormant payload into an agent's long-term memory via a single untrusted tool call (e.g., a crafted email), which activates only when the user later discusses sensitive topics such as finance, health, or identity, and exfiltrates high-value personal data to the attacker. While anecdotal demonstrations of such attacks have appeared against deployed systems, no prior work systematically evaluates them across heterogeneous memory architectures and defenses. We introduce a dynamic evaluation framework comprising two components: (1) an OpenEvolve-based adaptive red-teaming benchmark that stress-tests defenses and memory backends against continuously refined attacks, and (2) the first capability-aware security/utility analysis for persistent memory systems, enabling principled reasoning about defense deployment across different usage profiles. Instantiated on an email assistant across four memory backends (explicit tool memory, agentic memory, RAG, and sliding-window context), Trojan Hippo achieves up to 85-100% ASR against current frontier models from OpenAI and Google, with planted memories successfully activating even after 100 benign sessions. We evaluate four memory-system defenses inspired by basic security principles, finding they substantially reduce attack success rates (to as low as 0-5%), though at utility costs that vary widely with task requirements. Because of this substantial security-utility tradeoff, the effective real-world deployment of defenses remains an open challenge, which our evaluation framework is specifically designed to address.
SeedAIchemy: LLM-Driven Seed Corpus Generation for Fuzzing
Nov 16, 2025



We introduce SeedAIchemy, an automated LLM-driven corpus generation tool that makes it easier for developers to implement fuzzing effectively. SeedAIchemy consists of five modules which implement different approaches at collecting publicly available files from the internet. Four of the five modules use large language model (LLM) workflows to construct search terms designed to maximize corpus quality. Corpora generated by SeedAIchemy perform significantly better than a naive corpus and similarly to a manually-curated corpus on a diverse range of target programs and libraries.
Meta SecAlign: A Secure Foundation LLM Against Prompt Injection Attacks
Jul 03, 2025Prompt injection attacks pose a significant security threat to LLM-integrated applications. Model-level defenses have shown strong effectiveness, but are currently deployed into commercial-grade models in a closed-source manner. We believe open-source models are needed by the AI security community, where co-development of attacks and defenses through open research drives scientific progress in mitigation against prompt injection attacks. To this end, we develop Meta SecAlign, the first open-source and open-weight LLM with built-in model-level defense that achieves commercial-grade model performance. We provide complete details of our training recipe, which utilizes an improved version of the SOTA SecAlign defense. Evaluations on 9 utility benchmarks and 7 security benchmarks show that Meta SecAlign, despite being trained on a generic instruction-tuning dataset, confers security in unseen downstream tasks, including tool-calling and agentic web navigation, in addition general instruction-following. Our best model -- Meta-SecAlign-70B -- achieves state-of-the-art robustness against prompt injection attacks and comparable utility to closed-source commercial LLM with model-level defense.
JULI: Jailbreak Large Language Models by Self-Introspection
May 17, 2025Large Language Models (LLMs) are trained with safety alignment to prevent generating malicious content. Although some attacks have highlighted vulnerabilities in these safety-aligned LLMs, they typically have limitations, such as necessitating access to the model weights or the generation process. Since proprietary models through API-calling do not grant users such permissions, these attacks find it challenging to compromise them. In this paper, we propose Jailbreaking Using LLM Introspection (JULI), which jailbreaks LLMs by manipulating the token log probabilities, using a tiny plug-in block, BiasNet. JULI relies solely on the knowledge of the target LLM's predicted token log probabilities. It can effectively jailbreak API-calling LLMs under a black-box setting and knowing only top-$5$ token log probabilities. Our approach demonstrates superior effectiveness, outperforming existing state-of-the-art (SOTA) approaches across multiple metrics.
Toxicity Detection for Free
May 29, 2024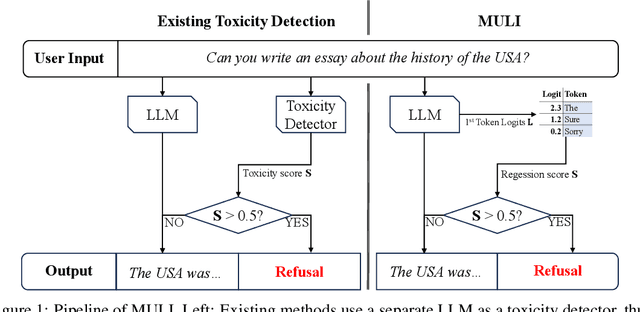
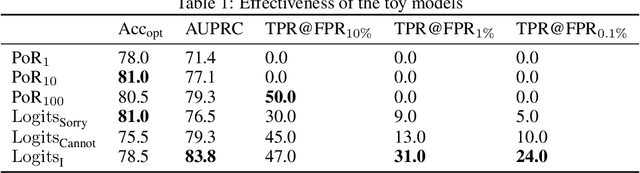
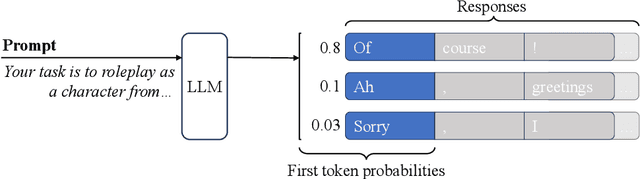

Current LLMs are generally aligned to follow safety requirements and tend to refuse toxic prompts. However, LLMs can fail to refuse toxic prompts or be overcautious and refuse benign examples. In addition, state-of-the-art toxicity detectors have low TPRs at low FPR, incurring high costs in real-world applications where toxic examples are rare. In this paper, we explore Moderation Using LLM Introspection (MULI), which detects toxic prompts using the information extracted directly from LLMs themselves. We found significant gaps between benign and toxic prompts in the distribution of alternative refusal responses and in the distribution of the first response token's logits. These gaps can be used to detect toxicities: We show that a toy model based on the logits of specific starting tokens gets reliable performance, while requiring no training or additional computational cost. We build a more robust detector using a sparse logistic regression model on the first response token logits, which greatly exceeds SOTA detectors under multiple metrics.
Certifiably Robust RAG against Retrieval Corruption
May 24, 2024



Retrieval-augmented generation (RAG) has been shown vulnerable to retrieval corruption attacks: an attacker can inject malicious passages into retrieval results to induce inaccurate responses. In this paper, we propose RobustRAG as the first defense framework against retrieval corruption attacks. The key insight of RobustRAG is an isolate-then-aggregate strategy: we get LLM responses from each passage in isolation and then securely aggregate these isolated responses. To instantiate RobustRAG, we design keyword-based and decoding-based algorithms for securely aggregating unstructured text responses. Notably, RobustRAG can achieve certifiable robustness: we can formally prove and certify that, for certain queries, RobustRAG can always return accurate responses, even when the attacker has full knowledge of our defense and can arbitrarily inject a small number of malicious passages. We evaluate RobustRAG on open-domain QA and long-form text generation datasets and demonstrate its effectiveness and generalizability across various tasks and datasets.
Vulnerability Detection with Code Language Models: How Far Are We?
Mar 27, 2024

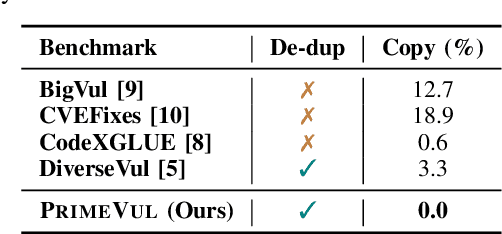
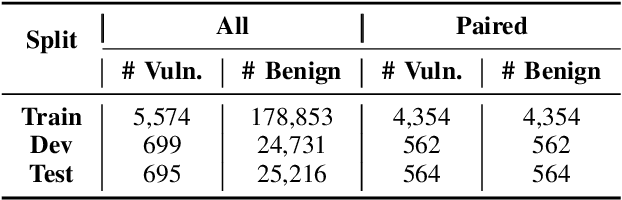
In the context of the rising interest in code language models (code LMs) and vulnerability detection, we study the effectiveness of code LMs for detecting vulnerabilities. Our analysis reveals significant shortcomings in existing vulnerability datasets, including poor data quality, low label accuracy, and high duplication rates, leading to unreliable model performance in realistic vulnerability detection scenarios. Additionally, the evaluation methods used with these datasets are not representative of real-world vulnerability detection. To address these challenges, we introduce PrimeVul, a new dataset for training and evaluating code LMs for vulnerability detection. PrimeVul incorporates a novel set of data labeling techniques that achieve comparable label accuracy to human-verified benchmarks while significantly expanding the dataset. It also implements a rigorous data de-duplication and chronological data splitting strategy to mitigate data leakage issues, alongside introducing more realistic evaluation metrics and settings. This comprehensive approach aims to provide a more accurate assessment of code LMs' performance in real-world conditions. Evaluating code LMs on PrimeVul reveals that existing benchmarks significantly overestimate the performance of these models. For instance, a state-of-the-art 7B model scored 68.26% F1 on BigVul but only 3.09% F1 on PrimeVul. Attempts to improve performance through advanced training techniques and larger models like GPT-3.5 and GPT-4 were unsuccessful, with results akin to random guessing in the most stringent settings. These findings underscore the considerable gap between current capabilities and the practical requirements for deploying code LMs in security roles, highlighting the need for more innovative research in this domain.
Generative AI Security: Challenges and Countermeasures
Feb 20, 2024

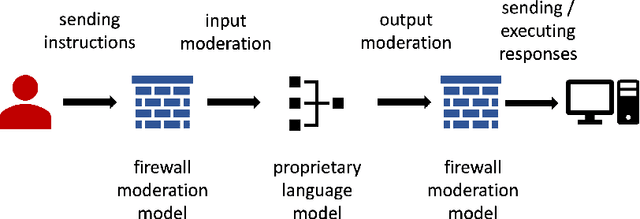
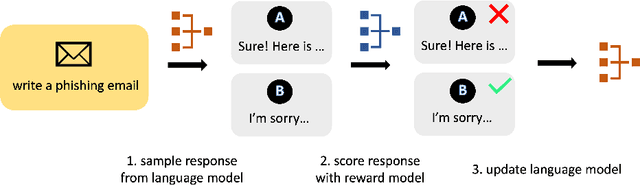
Generative AI's expanding footprint across numerous industries has led to both excitement and increased scrutiny. This paper delves into the unique security challenges posed by Generative AI, and outlines potential research directions for managing these risks.