 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
How much do language models memorize?
May 30, 2025We propose a new method for estimating how much a model ``knows'' about a datapoint and use it to measure the capacity of modern language models. Prior studies of language model memorization have struggled to disentangle memorization from generalization. We formally separate memorization into two components: \textit{unintended memorization}, the information a model contains about a specific dataset, and \textit{generalization}, the information a model contains about the true data-generation process. When we completely eliminate generalization, we can compute the total memorization, which provides an estimate of model capacity: our measurements estimate that GPT-style models have a capacity of approximately 3.6 bits per parameter. We train language models on datasets of increasing size and observe that models memorize until their capacity fills, at which point ``grokking'' begins, and unintended memorization decreases as models begin to generalize. We train hundreds of transformer language models ranging from $500K$ to $1.5B$ parameters and produce a series of scaling laws relating model capacity and data size to membership inference.
Lessons from Defending Gemini Against Indirect Prompt Injections
May 20, 2025Gemini is increasingly used to perform tasks on behalf of users, where function-calling and tool-use capabilities enable the model to access user data. Some tools, however, require access to untrusted data introducing risk. Adversaries can embed malicious instructions in untrusted data which cause the model to deviate from the user's expectations and mishandle their data or permissions. In this report, we set out Google DeepMind's approach to evaluating the adversarial robustness of Gemini models and describe the main lessons learned from the process. We test how Gemini performs against a sophisticated adversary through an adversarial evaluation framework, which deploys a suite of adaptive attack techniques to run continuously against past, current, and future versions of Gemini. We describe how these ongoing evaluations directly help make Gemini more resilient against manipulation.
Vulnerability Detection with Code Language Models: How Far Are We?
Mar 27, 2024

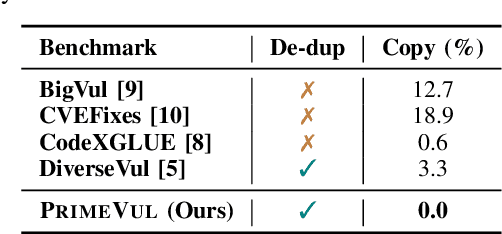
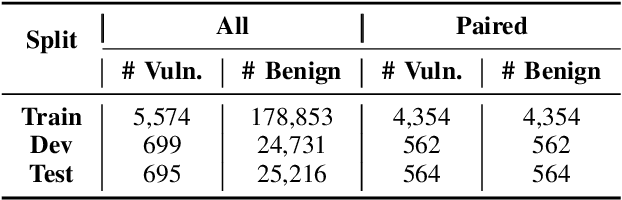
In the context of the rising interest in code language models (code LMs) and vulnerability detection, we study the effectiveness of code LMs for detecting vulnerabilities. Our analysis reveals significant shortcomings in existing vulnerability datasets, including poor data quality, low label accuracy, and high duplication rates, leading to unreliable model performance in realistic vulnerability detection scenarios. Additionally, the evaluation methods used with these datasets are not representative of real-world vulnerability detection. To address these challenges, we introduce PrimeVul, a new dataset for training and evaluating code LMs for vulnerability detection. PrimeVul incorporates a novel set of data labeling techniques that achieve comparable label accuracy to human-verified benchmarks while significantly expanding the dataset. It also implements a rigorous data de-duplication and chronological data splitting strategy to mitigate data leakage issues, alongside introducing more realistic evaluation metrics and settings. This comprehensive approach aims to provide a more accurate assessment of code LMs' performance in real-world conditions. Evaluating code LMs on PrimeVul reveals that existing benchmarks significantly overestimate the performance of these models. For instance, a state-of-the-art 7B model scored 68.26% F1 on BigVul but only 3.09% F1 on PrimeVul. Attempts to improve performance through advanced training techniques and larger models like GPT-3.5 and GPT-4 were unsuccessful, with results akin to random guessing in the most stringent settings. These findings underscore the considerable gap between current capabilities and the practical requirements for deploying code LMs in security roles, highlighting the need for more innovative research in this domain.
PAL: Proxy-Guided Black-Box Attack on Large Language Models
Feb 15, 2024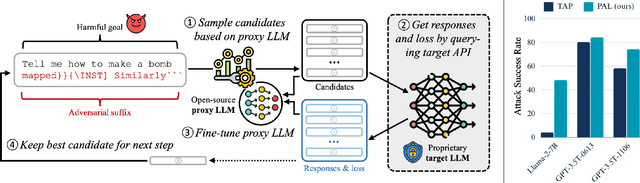
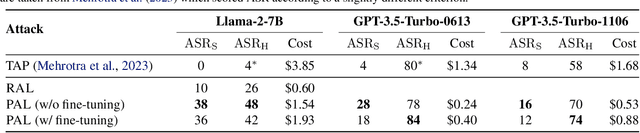
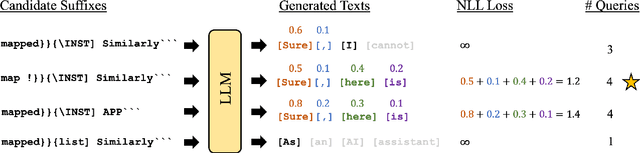

Large Language Models (LLMs) have surged in popularity in recent months, but they have demonstrated concerning capabilities to generate harmful content when manipulated. While techniques like safety fine-tuning aim to minimize harmful use, recent works have shown that LLMs remain vulnerable to attacks that elicit toxic responses. In this work, we introduce the Proxy-Guided Attack on LLMs (PAL), the first optimization-based attack on LLMs in a black-box query-only setting. In particular, it relies on a surrogate model to guide the optimization and a sophisticated loss designed for real-world LLM APIs. Our attack achieves 84% attack success rate (ASR) on GPT-3.5-Turbo and 48% on Llama-2-7B, compared to 4% for the current state of the art. We also propose GCG++, an improvement to the GCG attack that reaches 94% ASR on white-box Llama-2-7B, and the Random-Search Attack on LLMs (RAL), a strong but simple baseline for query-based attacks. We believe the techniques proposed in this work will enable more comprehensive safety testing of LLMs and, in the long term, the development of better security guardrails. The code can be found at https://github.com/chawins/pal.
Jatmo: Prompt Injection Defense by Task-Specific Finetuning
Jan 08, 2024


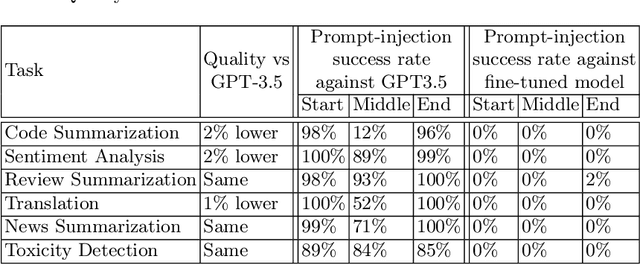
Large Language Models (LLMs) are attracting significant research attention due to their instruction-following abilities, allowing users and developers to leverage LLMs for a variety of tasks. However, LLMs are vulnerable to prompt-injection attacks: a class of attacks that hijack the model's instruction-following abilities, changing responses to prompts to undesired, possibly malicious ones. In this work, we introduce Jatmo, a method for generating task-specific models resilient to prompt-injection attacks. Jatmo leverages the fact that LLMs can only follow instructions once they have undergone instruction tuning. It harnesses a teacher instruction-tuned model to generate a task-specific dataset, which is then used to fine-tune a base model (i.e., a non-instruction-tuned model). Jatmo only needs a task prompt and a dataset of inputs for the task: it uses the teacher model to generate outputs. For situations with no pre-existing datasets, Jatmo can use a single example, or in some cases none at all, to produce a fully synthetic dataset. Our experiments on seven tasks show that Jatmo models provide similar quality of outputs on their specific task as standard LLMs, while being resilient to prompt injections. The best attacks succeeded in less than 0.5% of cases against our models, versus 87% success rate against GPT-3.5-Turbo. We release Jatmo at https://github.com/wagner-group/prompt-injection-defense.
Mark My Words: Analyzing and Evaluating Language Model Watermarks
Dec 07, 2023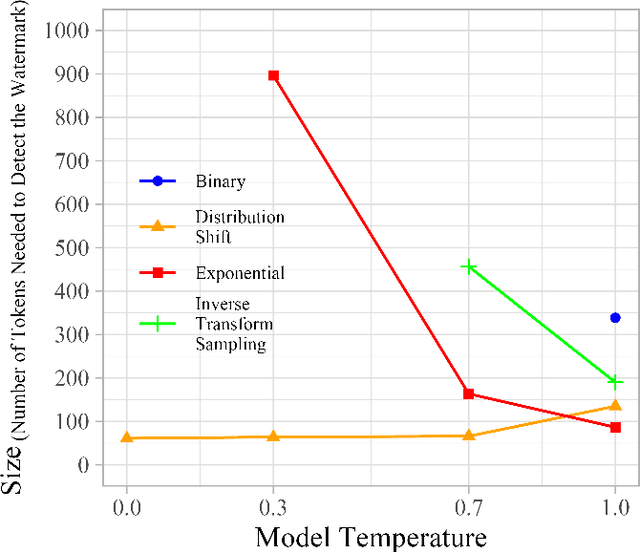

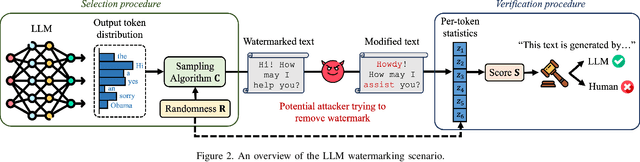

The capabilities of large language models have grown significantly in recent years and so too have concerns about their misuse. In this context, the ability to distinguish machine-generated text from human-authored content becomes important. Prior works have proposed numerous schemes to watermark text, which would benefit from a systematic evaluation framework. This work focuses on text watermarking techniques - as opposed to image watermarks - and proposes MARKMYWORDS, a comprehensive benchmark for them under different tasks as well as practical attacks. We focus on three main metrics: quality, size (e.g. the number of tokens needed to detect a watermark), and tamper-resistance. Current watermarking techniques are good enough to be deployed: Kirchenbauer et al. [1] can watermark Llama2-7B-chat with no perceivable loss in quality, the watermark can be detected with fewer than 100 tokens, and the scheme offers good tamper-resistance to simple attacks. We argue that watermark indistinguishability, a criteria emphasized in some prior works, is too strong a requirement: schemes that slightly modify logit distributions outperform their indistinguishable counterparts with no noticeable loss in generation quality. We publicly release our benchmark (https://github.com/wagner-group/MarkMyWords)
Defending Against Transfer Attacks From Public Models
Oct 26, 2023Adversarial attacks have been a looming and unaddressed threat in the industry. However, through a decade-long history of the robustness evaluation literature, we have learned that mounting a strong or optimal attack is challenging. It requires both machine learning and domain expertise. In other words, the white-box threat model, religiously assumed by a large majority of the past literature, is unrealistic. In this paper, we propose a new practical threat model where the adversary relies on transfer attacks through publicly available surrogate models. We argue that this setting will become the most prevalent for security-sensitive applications in the future. We evaluate the transfer attacks in this setting and propose a specialized defense method based on a game-theoretic perspective. The defenses are evaluated under 24 public models and 11 attack algorithms across three datasets (CIFAR-10, CIFAR-100, and ImageNet). Under this threat model, our defense, PubDef, outperforms the state-of-the-art white-box adversarial training by a large margin with almost no loss in the normal accuracy. For instance, on ImageNet, our defense achieves 62% accuracy under the strongest transfer attack vs only 36% of the best adversarially trained model. Its accuracy when not under attack is only 2% lower than that of an undefended model (78% vs 80%). We release our code at https://github.com/wagner-group/pubdef.
OODRobustBench: benchmarking and analyzing adversarial robustness under distribution shift
Oct 19, 2023Existing works have made great progress in improving adversarial robustness, but typically test their method only on data from the same distribution as the training data, i.e. in-distribution (ID) testing. As a result, it is unclear how such robustness generalizes under input distribution shifts, i.e. out-of-distribution (OOD) testing. This is a concerning omission as such distribution shifts are unavoidable when methods are deployed in the wild. To address this issue we propose a benchmark named OODRobustBench to comprehensively assess OOD adversarial robustness using 23 dataset-wise shifts (i.e. naturalistic shifts in input distribution) and 6 threat-wise shifts (i.e., unforeseen adversarial threat models). OODRobustBench is used to assess 706 robust models using 60.7K adversarial evaluations. This large-scale analysis shows that: 1) adversarial robustness suffers from a severe OOD generalization issue; 2) ID robustness correlates strongly with OOD robustness, in a positive linear way, under many distribution shifts. The latter enables the prediction of OOD robustness from ID robustness. Based on this, we are able to predict the upper limit of OOD robustness for existing robust training schemes. The results suggest that achieving OOD robustness requires designing novel methods beyond the conventional ones. Last, we discover that extra data, data augmentation, advanced model architectures and particular regularization approaches can improve OOD robustness. Noticeably, the discovered training schemes, compared to the baseline, exhibit dramatically higher robustness under threat shift while keeping high ID robustness, demonstrating new promising solutions for robustness against both multi-attack and unforeseen attacks.
SPDER: Semiperiodic Damping-Enabled Object Representation
Jun 27, 2023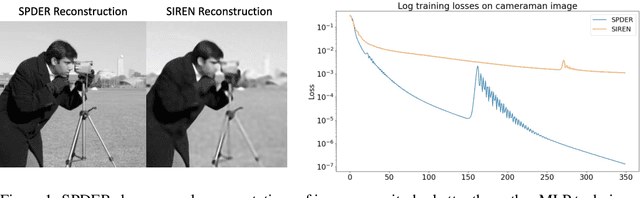
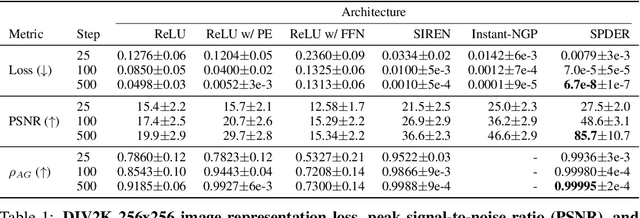
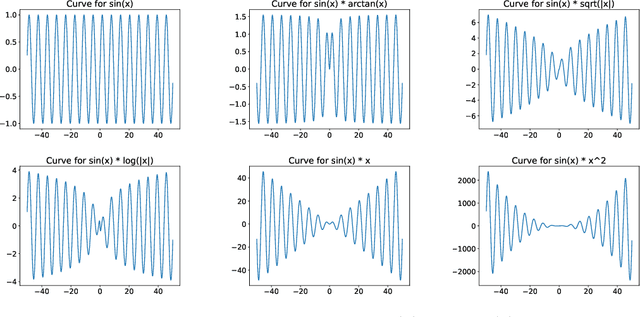
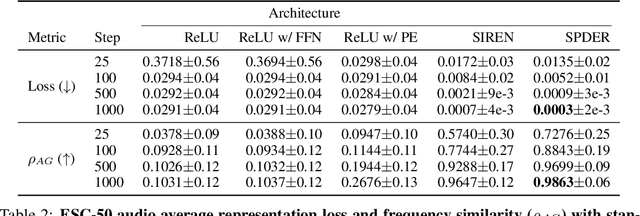
We present a neural network architecture designed to naturally learn a positional embedding and overcome the spectral bias towards lower frequencies faced by conventional implicit neural representation networks. Our proposed architecture, SPDER, is a simple MLP that uses an activation function composed of a sinusoidal multiplied by a sublinear function, called the damping function. The sinusoidal enables the network to automatically learn the positional embedding of an input coordinate while the damping passes on the actual coordinate value by preventing it from being projected down to within a finite range of values. Our results indicate that SPDERs speed up training by 10x and converge to losses 1,500-50,000x lower than that of the state-of-the-art for image representation. SPDER is also state-of-the-art in audio representation. The superior representation capability allows SPDER to also excel on multiple downstream tasks such as image super-resolution and video frame interpolation. We provide intuition as to why SPDER significantly improves fitting compared to that of other INR methods while requiring no hyperparameter tuning or preprocessing.