 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFAAR: Efficient Frequency-Aware Multi-Task Fine-Tuning via Automatic Rank Selection
Mar 20, 2026Adapting models pre-trained on large-scale datasets is a proven way to reach strong performance quickly for down-stream tasks. However, the growth of state-of-the-art mod-els makes traditional full fine-tuning unsuitable and difficult, especially for multi-task learning (MTL) where cost scales with the number of tasks. As a result, recent studies investigate parameter-efficient fine-tuning (PEFT) using low-rank adaptation to significantly reduce the number of trainable parameters. However, these existing methods use a single, fixed rank, which may not be optimal for differ-ent tasks or positions in the MTL architecture. Moreover, these methods fail to learn spatial information that cap-tures inter-task relationships and helps to improve diverse task predictions. This paper introduces Frequency-Aware and Automatic Rank (FAAR) for efficient MTL fine-tuning. Our method introduces Performance-Driven Rank Shrink-ing (PDRS) to allocate the optimal rank per adapter location and per task. Moreover, by analyzing the image frequency spectrum, FAAR proposes a Task-Spectral Pyramidal Decoder (TS-PD) that injects input-specific context into spatial bias learning to better reflect cross-task relationships. Experiments performed on dense visual task benchmarks show the superiority of our method in terms of both accuracy and efficiency compared to other PEFT methods in MTL. FAAR reduces the number of parameters by up to 9 times compared to traditional MTL fine-tuning whilst improving overall performance. Our code is available.
Optimizing Dense Visual Predictions Through Multi-Task Coherence and Prioritization
Dec 04, 2024



Multi-Task Learning (MTL) involves the concurrent training of multiple tasks, offering notable advantages for dense prediction tasks in computer vision. MTL not only reduces training and inference time as opposed to having multiple single-task models, but also enhances task accuracy through the interaction of multiple tasks. However, existing methods face limitations. They often rely on suboptimal cross-task interactions, resulting in task-specific predictions with poor geometric and predictive coherence. In addition, many approaches use inadequate loss weighting strategies, which do not address the inherent variability in task evolution during training. To overcome these challenges, we propose an advanced MTL model specifically designed for dense vision tasks. Our model leverages state-of-the-art vision transformers with task-specific decoders. To enhance cross-task coherence, we introduce a trace-back method that improves both cross-task geometric and predictive features. Furthermore, we present a novel dynamic task balancing approach that projects task losses onto a common scale and prioritizes more challenging tasks during training. Extensive experiments demonstrate the superiority of our method, establishing new state-of-the-art performance across two benchmark datasets. The code is available at:https://github.com/Klodivio355/MT-CP
Few-Shot Anomaly Detection via Category-Agnostic Registration Learning
Jun 13, 2024Most existing anomaly detection methods require a dedicated model for each category. Such a paradigm, despite its promising results, is computationally expensive and inefficient, thereby failing to meet the requirements for real-world applications. Inspired by how humans detect anomalies, by comparing a query image to known normal ones, this paper proposes a novel few-shot anomaly detection (FSAD) framework. Using a training set of normal images from various categories, registration, aiming to align normal images of the same categories, is leveraged as the proxy task for self-supervised category-agnostic representation learning. At test time, an image and its corresponding support set, consisting of a few normal images from the same category, are supplied, and anomalies are identified by comparing the registered features of the test image to its corresponding support image features. Such a setup enables the model to generalize to novel test categories. It is, to our best knowledge, the first FSAD method that requires no model fine-tuning for novel categories: enabling a single model to be applied to all categories. Extensive experiments demonstrate the effectiveness of the proposed method. Particularly, it improves the current state-of-the-art for FSAD by 11.3% and 8.3% on the MVTec and MPDD benchmarks, respectively. The source code is available at https://github.com/Haoyan-Guan/CAReg.
One Prompt Word is Enough to Boost Adversarial Robustness for Pre-trained Vision-Language Models
Mar 04, 2024



Large pre-trained Vision-Language Models (VLMs) like CLIP, despite having remarkable generalization ability, are highly vulnerable to adversarial examples. This work studies the adversarial robustness of VLMs from the novel perspective of the text prompt instead of the extensively studied model weights (frozen in this work). We first show that the effectiveness of both adversarial attack and defense are sensitive to the used text prompt. Inspired by this, we propose a method to improve resilience to adversarial attacks by learning a robust text prompt for VLMs. The proposed method, named Adversarial Prompt Tuning (APT), is effective while being both computationally and data efficient. Extensive experiments are conducted across 15 datasets and 4 data sparsity schemes (from 1-shot to full training data settings) to show APT's superiority over hand-engineered prompts and other state-of-the-art adaption methods. APT demonstrated excellent abilities in terms of the in-distribution performance and the generalization under input distribution shift and across datasets. Surprisingly, by simply adding one learned word to the prompts, APT can significantly boost the accuracy and robustness (epsilon=4/255) over the hand-engineered prompts by +13% and +8.5% on average respectively. The improvement further increases, in our most effective setting, to +26.4% for accuracy and +16.7% for robustness. Code is available at https://github.com/TreeLLi/APT.
The Importance of Anti-Aliasing in Tiny Object Detection
Oct 22, 2023



Tiny object detection has gained considerable attention in the research community owing to the frequent occurrence of tiny objects in numerous critical real-world scenarios. However, convolutional neural networks (CNNs) used as the backbone for object detection architectures typically neglect Nyquist's sampling theorem during down-sampling operations, resulting in aliasing and degraded performance. This is likely to be a particular issue for tiny objects that occupy very few pixels and therefore have high spatial frequency features. This paper applied an existing approach WaveCNet for anti-aliasing to tiny object detection. WaveCNet addresses aliasing by replacing standard down-sampling processes in CNNs with Wavelet Pooling (WaveletPool) layers, effectively suppressing aliasing. We modify the original WaveCNet to apply WaveletPool in a consistent way in both pathways of the residual blocks in ResNets. Additionally, we also propose a bottom-heavy version of the backbone, which further improves the performance of tiny object detection while also reducing the required number of parameters by almost half. Experimental results on the TinyPerson, WiderFace, and DOTA datasets demonstrate the importance of anti-aliasing in tiny object detection and the effectiveness of the proposed method which achieves new state-of-the-art results on all three datasets. Codes and experiment results are released at https://github.com/freshn/Anti-aliasing-Tiny-Object-Detection.git.
OODRobustBench: benchmarking and analyzing adversarial robustness under distribution shift
Oct 19, 2023Existing works have made great progress in improving adversarial robustness, but typically test their method only on data from the same distribution as the training data, i.e. in-distribution (ID) testing. As a result, it is unclear how such robustness generalizes under input distribution shifts, i.e. out-of-distribution (OOD) testing. This is a concerning omission as such distribution shifts are unavoidable when methods are deployed in the wild. To address this issue we propose a benchmark named OODRobustBench to comprehensively assess OOD adversarial robustness using 23 dataset-wise shifts (i.e. naturalistic shifts in input distribution) and 6 threat-wise shifts (i.e., unforeseen adversarial threat models). OODRobustBench is used to assess 706 robust models using 60.7K adversarial evaluations. This large-scale analysis shows that: 1) adversarial robustness suffers from a severe OOD generalization issue; 2) ID robustness correlates strongly with OOD robustness, in a positive linear way, under many distribution shifts. The latter enables the prediction of OOD robustness from ID robustness. Based on this, we are able to predict the upper limit of OOD robustness for existing robust training schemes. The results suggest that achieving OOD robustness requires designing novel methods beyond the conventional ones. Last, we discover that extra data, data augmentation, advanced model architectures and particular regularization approaches can improve OOD robustness. Noticeably, the discovered training schemes, compared to the baseline, exhibit dramatically higher robustness under threat shift while keeping high ID robustness, demonstrating new promising solutions for robustness against both multi-attack and unforeseen attacks.
When Multi-Task Learning Meets Partial Supervision: A Computer Vision Review
Jul 25, 2023



Multi-Task Learning (MTL) aims to learn multiple tasks simultaneously while exploiting their mutual relationships. By using shared resources to simultaneously calculate multiple outputs, this learning paradigm has the potential to have lower memory requirements and inference times compared to the traditional approach of using separate methods for each task. Previous work in MTL has mainly focused on fully-supervised methods, as task relationships can not only be leveraged to lower the level of data-dependency of those methods but they can also improve performance. However, MTL introduces a set of challenges due to a complex optimisation scheme and a higher labeling requirement. This review focuses on how MTL could be utilised under different partial supervision settings to address these challenges. First, this review analyses how MTL traditionally uses different parameter sharing techniques to transfer knowledge in between tasks. Second, it presents the different challenges arising from such a multi-objective optimisation scheme. Third, it introduces how task groupings can be achieved by analysing task relationships. Fourth, it focuses on how partially supervised methods applied to MTL can tackle the aforementioned challenges. Lastly, this review presents the available datasets, tools and benchmarking results of such methods.
AROID: Improving Adversarial Robustness through Online Instance-wise Data Augmentation
Jun 12, 2023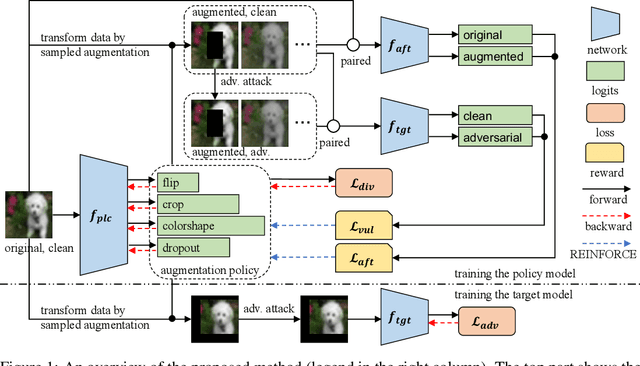

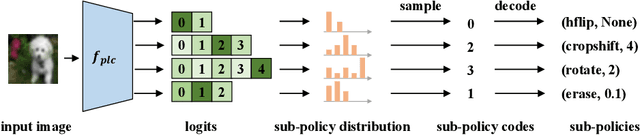
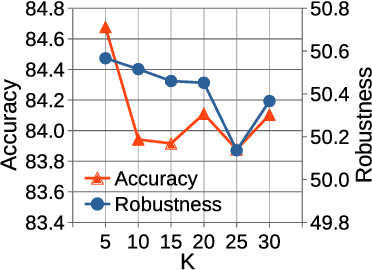
Deep neural networks are vulnerable to adversarial examples. Adversarial training (AT) is an effective defense against adversarial examples. However, AT is prone to overfitting which degrades robustness substantially. Recently, data augmentation (DA) was shown to be effective in mitigating robust overfitting if appropriately designed and optimized for AT. This work proposes a new method to automatically learn online, instance-wise, DA policies to improve robust generalization for AT. A novel policy learning objective, consisting of Vulnerability, Affinity and Diversity, is proposed and shown to be sufficiently effective and efficient to be practical for automatic DA generation during AT. This allows our method to efficiently explore a large search space for a more effective DA policy and evolve the policy as training progresses. Empirically, our method is shown to outperform or match all competitive DA methods across various model architectures (CNNs and ViTs) and datasets (CIFAR10, SVHN and Imagenette). Our DA policy reinforced vanilla AT to surpass several state-of-the-art AT methods (with baseline DA) in terms of both accuracy and robustness. It can also be combined with those advanced AT methods to produce a further boost in robustness.
Improved Adversarial Training Through Adaptive Instance-wise Loss Smoothing
Mar 27, 2023



Deep neural networks can be easily fooled into making incorrect predictions through corruption of the input by adversarial perturbations: human-imperceptible artificial noise. So far adversarial training has been the most successful defense against such adversarial attacks. This work focuses on improving adversarial training to boost adversarial robustness. We first analyze, from an instance-wise perspective, how adversarial vulnerability evolves during adversarial training. We find that during training an overall reduction of adversarial loss is achieved by sacrificing a considerable proportion of training samples to be more vulnerable to adversarial attack, which results in an uneven distribution of adversarial vulnerability among data. Such "uneven vulnerability", is prevalent across several popular robust training methods and, more importantly, relates to overfitting in adversarial training. Motivated by this observation, we propose a new adversarial training method: Instance-adaptive Smoothness Enhanced Adversarial Training (ISEAT). It jointly smooths both input and weight loss landscapes in an adaptive, instance-specific, way to enhance robustness more for those samples with higher adversarial vulnerability. Extensive experiments demonstrate the superiority of our method over existing defense methods. Noticeably, our method, when combined with the latest data augmentation and semi-supervised learning techniques, achieves state-of-the-art robustness against $\ell_{\infty}$-norm constrained attacks on CIFAR10 of 59.32% for Wide ResNet34-10 without extra data, and 61.55% for Wide ResNet28-10 with extra data. Code is available at https://github.com/TreeLLi/Instance-adaptive-Smoothness-Enhanced-AT.
Rethinking the backbone architecture for tiny object detection
Mar 20, 2023



Tiny object detection has become an active area of research because images with tiny targets are common in several important real-world scenarios. However, existing tiny object detection methods use standard deep neural networks as their backbone architecture. We argue that such backbones are inappropriate for detecting tiny objects as they are designed for the classification of larger objects, and do not have the spatial resolution to identify small targets. Specifically, such backbones use max-pooling or a large stride at early stages in the architecture. This produces lower resolution feature-maps that can be efficiently processed by subsequent layers. However, such low-resolution feature-maps do not contain information that can reliably discriminate tiny objects. To solve this problem we design 'bottom-heavy' versions of backbones that allocate more resources to processing higher-resolution features without introducing any additional computational burden overall. We also investigate if pre-training these backbones on images of appropriate size, using CIFAR100 and ImageNet32, can further improve performance on tiny object detection. Results on TinyPerson and WiderFace show that detectors with our proposed backbones achieve better results than the current state-of-the-art methods.