 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFAAR: Efficient Frequency-Aware Multi-Task Fine-Tuning via Automatic Rank Selection
Mar 20, 2026Adapting models pre-trained on large-scale datasets is a proven way to reach strong performance quickly for down-stream tasks. However, the growth of state-of-the-art mod-els makes traditional full fine-tuning unsuitable and difficult, especially for multi-task learning (MTL) where cost scales with the number of tasks. As a result, recent studies investigate parameter-efficient fine-tuning (PEFT) using low-rank adaptation to significantly reduce the number of trainable parameters. However, these existing methods use a single, fixed rank, which may not be optimal for differ-ent tasks or positions in the MTL architecture. Moreover, these methods fail to learn spatial information that cap-tures inter-task relationships and helps to improve diverse task predictions. This paper introduces Frequency-Aware and Automatic Rank (FAAR) for efficient MTL fine-tuning. Our method introduces Performance-Driven Rank Shrink-ing (PDRS) to allocate the optimal rank per adapter location and per task. Moreover, by analyzing the image frequency spectrum, FAAR proposes a Task-Spectral Pyramidal Decoder (TS-PD) that injects input-specific context into spatial bias learning to better reflect cross-task relationships. Experiments performed on dense visual task benchmarks show the superiority of our method in terms of both accuracy and efficiency compared to other PEFT methods in MTL. FAAR reduces the number of parameters by up to 9 times compared to traditional MTL fine-tuning whilst improving overall performance. Our code is available.
Bootstrapping MLLM for Weakly-Supervised Class-Agnostic Object Counting
Feb 13, 2026Object counting is a fundamental task in computer vision, with broad applicability in many real-world scenarios. Fully-supervised counting methods require costly point-level annotations per object. Few weakly-supervised methods leverage only image-level object counts as supervision and achieve fairly promising results. They are, however, often limited to counting a single category, e.g. person. In this paper, we propose WS-COC, the first MLLM-driven weakly-supervised framework for class-agnostic object counting. Instead of directly fine-tuning MLLMs to predict object counts, which can be challenging due to the modality gap, we incorporate three simple yet effective strategies to bootstrap the counting paradigm in both training and testing: First, a divide-and-discern dialogue tuning strategy is proposed to guide the MLLM to determine whether the object count falls within a specific range and progressively break down the range through multi-round dialogue. Second, a compare-and-rank count optimization strategy is introduced to train the MLLM to optimize the relative ranking of multiple images according to their object counts. Third, a global-and-local counting enhancement strategy aggregates and fuses local and global count predictions to improve counting performance in dense scenes. Extensive experiments on FSC-147, CARPK, PUCPR+, and ShanghaiTech show that WS-COC matches or even surpasses many state-of-art fully-supervised methods while significantly reducing annotation costs. Code is available at https://github.com/viscom-tongji/WS-COC.
Text-promptable Object Counting via Quantity Awareness Enhancement
Jul 09, 2025



Recent advances in large vision-language models (VLMs) have shown remarkable progress in solving the text-promptable object counting problem. Representative methods typically specify text prompts with object category information in images. This however is insufficient for training the model to accurately distinguish the number of objects in the counting task. To this end, we propose QUANet, which introduces novel quantity-oriented text prompts with a vision-text quantity alignment loss to enhance the model's quantity awareness. Moreover, we propose a dual-stream adaptive counting decoder consisting of a Transformer stream, a CNN stream, and a number of Transformer-to-CNN enhancement adapters (T2C-adapters) for density map prediction. The T2C-adapters facilitate the effective knowledge communication and aggregation between the Transformer and CNN streams. A cross-stream quantity ranking loss is proposed in the end to optimize the ranking orders of predictions from the two streams. Extensive experiments on standard benchmarks such as FSC-147, CARPK, PUCPR+, and ShanghaiTech demonstrate our model's strong generalizability for zero-shot class-agnostic counting. Code is available at https://github.com/viscom-tongji/QUANet
TRAIL: Transferable Robust Adversarial Images via Latent diffusion
May 22, 2025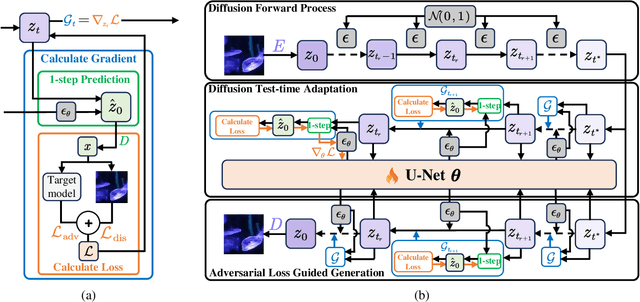
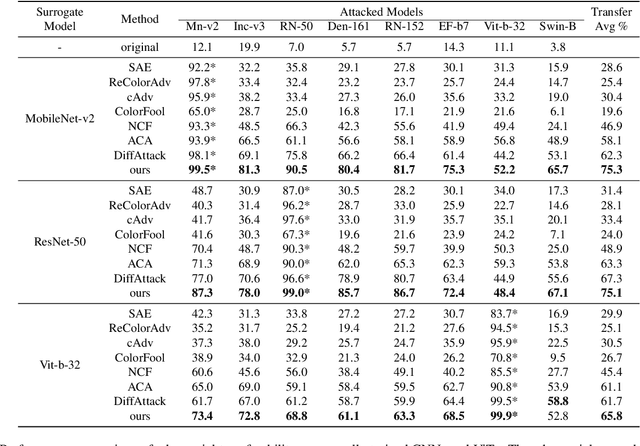
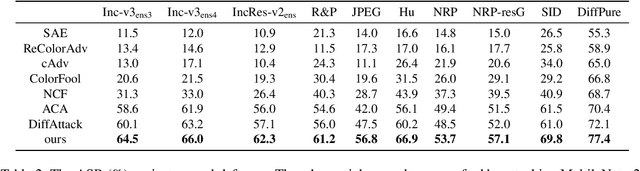

Adversarial attacks exploiting unrestricted natural perturbations present severe security risks to deep learning systems, yet their transferability across models remains limited due to distribution mismatches between generated adversarial features and real-world data. While recent works utilize pre-trained diffusion models as adversarial priors, they still encounter challenges due to the distribution shift between the distribution of ideal adversarial samples and the natural image distribution learned by the diffusion model. To address the challenge, we propose Transferable Robust Adversarial Images via Latent Diffusion (TRAIL), a test-time adaptation framework that enables the model to generate images from a distribution of images with adversarial features and closely resembles the target images. To mitigate the distribution shift, during attacks, TRAIL updates the diffusion U-Net's weights by combining adversarial objectives (to mislead victim models) and perceptual constraints (to preserve image realism). The adapted model then generates adversarial samples through iterative noise injection and denoising guided by these objectives. Experiments demonstrate that TRAIL significantly outperforms state-of-the-art methods in cross-model attack transferability, validating that distribution-aligned adversarial feature synthesis is critical for practical black-box attacks.
MPDrive: Improving Spatial Understanding with Marker-Based Prompt Learning for Autonomous Driving
Apr 01, 2025



Autonomous driving visual question answering (AD-VQA) aims to answer questions related to perception, prediction, and planning based on given driving scene images, heavily relying on the model's spatial understanding capabilities. Prior works typically express spatial information through textual representations of coordinates, resulting in semantic gaps between visual coordinate representations and textual descriptions. This oversight hinders the accurate transmission of spatial information and increases the expressive burden. To address this, we propose a novel Marker-based Prompt learning framework (MPDrive), which represents spatial coordinates by concise visual markers, ensuring linguistic expressive consistency and enhancing the accuracy of both visual perception and spatial expression in AD-VQA. Specifically, we create marker images by employing a detection expert to overlay object regions with numerical labels, converting complex textual coordinate generation into straightforward text-based visual marker predictions. Moreover, we fuse original and marker images as scene-level features and integrate them with detection priors to derive instance-level features. By combining these features, we construct dual-granularity visual prompts that stimulate the LLM's spatial perception capabilities. Extensive experiments on the DriveLM and CODA-LM datasets show that MPDrive achieves state-of-the-art performance, particularly in cases requiring sophisticated spatial understanding.
Enhancing Generalized Few-Shot Semantic Segmentation via Effective Knowledge Transfer
Dec 20, 2024
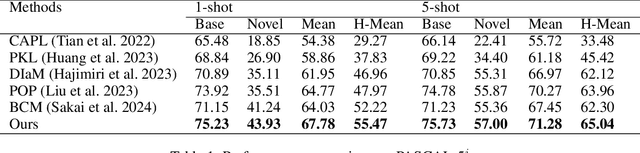


Generalized few-shot semantic segmentation (GFSS) aims to segment objects of both base and novel classes, using sufficient samples of base classes and few samples of novel classes. Representative GFSS approaches typically employ a two-phase training scheme, involving base class pre-training followed by novel class fine-tuning, to learn the classifiers for base and novel classes respectively. Nevertheless, distribution gap exists between base and novel classes in this process. To narrow this gap, we exploit effective knowledge transfer from base to novel classes. First, a novel prototype modulation module is designed to modulate novel class prototypes by exploiting the correlations between base and novel classes. Second, a novel classifier calibration module is proposed to calibrate the weight distribution of the novel classifier according to that of the base classifier. Furthermore, existing GFSS approaches suffer from a lack of contextual information for novel classes due to their limited samples, we thereby introduce a context consistency learning scheme to transfer the contextual knowledge from base to novel classes. Extensive experiments on PASCAL-5$^i$ and COCO-20$^i$ demonstrate that our approach significantly enhances the state of the art in the GFSS setting. The code is available at: https://github.com/HHHHedy/GFSS-EKT.
SEG-SAM: Semantic-Guided SAM for Unified Medical Image Segmentation
Dec 17, 2024



Recently, developing unified medical image segmentation models gains increasing attention, especially with the advent of the Segment Anything Model (SAM). SAM has shown promising binary segmentation performance in natural domains, however, transferring it to the medical domain remains challenging, as medical images often possess substantial inter-category overlaps. To address this, we propose the SEmantic-Guided SAM (SEG-SAM), a unified medical segmentation model that incorporates semantic medical knowledge to enhance medical segmentation performance. First, to avoid the potential conflict between binary and semantic predictions, we introduce a semantic-aware decoder independent of SAM's original decoder, specialized for both semantic segmentation on the prompted object and classification on unprompted objects in images. To further enhance the model's semantic understanding, we solicit key characteristics of medical categories from large language models and incorporate them into SEG-SAM through a text-to-vision semantic module, adaptively transferring the language information into the visual segmentation task. In the end, we introduce the cross-mask spatial alignment strategy to encourage greater overlap between the predicted masks from SEG-SAM's two decoders, thereby benefiting both predictions. Extensive experiments demonstrate that SEG-SAM outperforms state-of-the-art SAM-based methods in unified binary medical segmentation and task-specific methods in semantic medical segmentation, showcasing promising results and potential for broader medical applications.
Learning Flow Fields in Attention for Controllable Person Image Generation
Dec 12, 2024
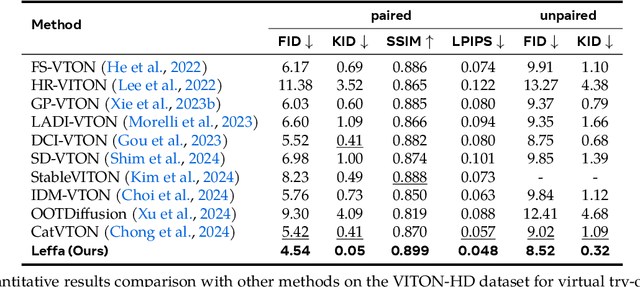
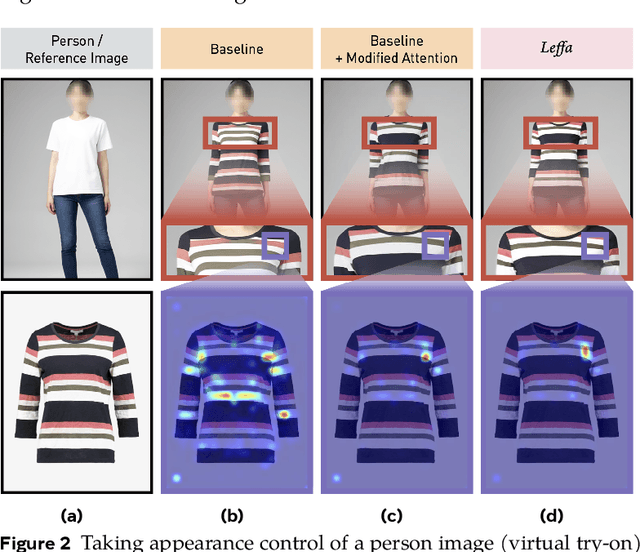
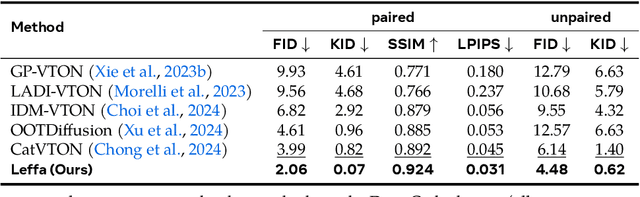
Controllable person image generation aims to generate a person image conditioned on reference images, allowing precise control over the person's appearance or pose. However, prior methods often distort fine-grained textural details from the reference image, despite achieving high overall image quality. We attribute these distortions to inadequate attention to corresponding regions in the reference image. To address this, we thereby propose learning flow fields in attention (Leffa), which explicitly guides the target query to attend to the correct reference key in the attention layer during training. Specifically, it is realized via a regularization loss on top of the attention map within a diffusion-based baseline. Our extensive experiments show that Leffa achieves state-of-the-art performance in controlling appearance (virtual try-on) and pose (pose transfer), significantly reducing fine-grained detail distortion while maintaining high image quality. Additionally, we show that our loss is model-agnostic and can be used to improve the performance of other diffusion models.
Optimizing Dense Visual Predictions Through Multi-Task Coherence and Prioritization
Dec 04, 2024



Multi-Task Learning (MTL) involves the concurrent training of multiple tasks, offering notable advantages for dense prediction tasks in computer vision. MTL not only reduces training and inference time as opposed to having multiple single-task models, but also enhances task accuracy through the interaction of multiple tasks. However, existing methods face limitations. They often rely on suboptimal cross-task interactions, resulting in task-specific predictions with poor geometric and predictive coherence. In addition, many approaches use inadequate loss weighting strategies, which do not address the inherent variability in task evolution during training. To overcome these challenges, we propose an advanced MTL model specifically designed for dense vision tasks. Our model leverages state-of-the-art vision transformers with task-specific decoders. To enhance cross-task coherence, we introduce a trace-back method that improves both cross-task geometric and predictive features. Furthermore, we present a novel dynamic task balancing approach that projects task losses onto a common scale and prioritizes more challenging tasks during training. Extensive experiments demonstrate the superiority of our method, establishing new state-of-the-art performance across two benchmark datasets. The code is available at:https://github.com/Klodivio355/MT-CP
Aligning Few-Step Diffusion Models with Dense Reward Difference Learning
Nov 18, 2024



Aligning diffusion models with downstream objectives is essential for their practical applications. However, standard alignment methods often struggle with step generalization when directly applied to few-step diffusion models, leading to inconsistent performance across different denoising step scenarios. To address this, we introduce Stepwise Diffusion Policy Optimization (SDPO), a novel alignment method tailored for few-step diffusion models. Unlike prior approaches that rely on a single sparse reward from only the final step of each denoising trajectory for trajectory-level optimization, SDPO incorporates dense reward feedback at every intermediate step. By learning the differences in dense rewards between paired samples, SDPO facilitates stepwise optimization of few-step diffusion models, ensuring consistent alignment across all denoising steps. To promote stable and efficient training, SDPO introduces an online reinforcement learning framework featuring several novel strategies designed to effectively exploit the stepwise granularity of dense rewards. Experimental results demonstrate that SDPO consistently outperforms prior methods in reward-based alignment across diverse step configurations, underscoring its robust step generalization capabilities. Code is avaliable at https://github.com/ZiyiZhang27/sdpo.