 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntropyPrune: Matrix Entropy Guided Visual Token Pruning for Multimodal Large Language Models
Feb 19, 2026Multimodal large language models (MLLMs) incur substantial inference cost due to the processing of hundreds of visual tokens per image. Although token pruning has proven effective for accelerating inference, determining when and where to prune remains largely heuristic. Existing approaches typically rely on static, empirically selected layers, which limit interpretability and transferability across models. In this work, we introduce a matrix-entropy perspective and identify an "Entropy Collapse Layer" (ECL), where the information content of visual representations exhibits a sharp and consistent drop, which provides a principled criterion for selecting the pruning stage. Building on this observation, we propose EntropyPrune, a novel matrix-entropy-guided token pruning framework that quantifies the information value of individual visual tokens and prunes redundant ones without relying on attention maps. Moreover, to enable efficient computation, we exploit the spectral equivalence of dual Gram matrices, reducing the complexity of entropy computation and yielding up to a 64x theoretical speedup. Extensive experiments on diverse multimodal benchmarks demonstrate that EntropyPrune consistently outperforms state-of-the-art pruning methods in both accuracy and efficiency. On LLaVA-1.5-7B, our method achieves a 68.2% reduction in FLOPs while preserving 96.0% of the original performance. Furthermore, EntropyPrune generalizes effectively to high-resolution and video-based models, highlighting the strong robustness and scalability in practical MLLM acceleration. The code will be publicly available at https://github.com/YahongWang1/EntropyPrune.
All You Need Are Random Visual Tokens? Demystifying Token Pruning in VLLMs
Dec 08, 2025Vision Large Language Models (VLLMs) incur high computational costs due to their reliance on hundreds of visual tokens to represent images. While token pruning offers a promising solution for accelerating inference, this paper, however, identifies a key observation: in deeper layers (e.g., beyond the 20th), existing training-free pruning methods perform no better than random pruning. We hypothesize that this degradation is caused by "vanishing token information", where visual tokens progressively lose their salience with increasing network depth. To validate this hypothesis, we quantify a token's information content by measuring the change in the model output probabilities upon its removal. Using this proposed metric, our analysis of the information of visual tokens across layers reveals three key findings: (1) As layers deepen, the information of visual tokens gradually becomes uniform and eventually vanishes at an intermediate layer, which we term as "information horizon", beyond which the visual tokens become redundant; (2) The position of this horizon is not static; it extends deeper for visually intensive tasks, such as Optical Character Recognition (OCR), compared to more general tasks like Visual Question Answering (VQA); (3) This horizon is also strongly correlated with model capacity, as stronger VLLMs (e.g., Qwen2.5-VL) employ deeper visual tokens than weaker models (e.g., LLaVA-1.5). Based on our findings, we show that simple random pruning in deep layers efficiently balances performance and efficiency. Moreover, integrating random pruning consistently enhances existing methods. Using DivPrune with random pruning achieves state-of-the-art results, maintaining 96.9% of Qwen-2.5-VL-7B performance while pruning 50% of visual tokens. The code will be publicly available at https://github.com/YahongWang1/Information-Horizon.
One Prototype Is Enough: Single-Prototype Activation for Interpretable Image Classification
Jun 24, 2025In this paper, we propose ProtoSolo, a novel deep neural architecture for interpretable image classification inspired by prototypical networks such as ProtoPNet. Existing prototype networks usually rely on the collaborative decision-making of multiple prototypes to achieve the classification and interpretation of a single category. In contrast, ProtoSolo only requires the activation of a single prototype to complete the classification. This allows the network to explain each category decision by only providing the features that are most similar to the prototype of that category, significantly reducing the cognitive complexity of the explanation. Secondly, we propose a feature-based comparison method, which uses feature map instead of full-channel feature vector as the object of similarity comparison and prototype learning. This design enables ProtoSolo to utilize richer global information for classification while relying on a single prototype activation. In addition, we propose a non-prototype projection learning strategy, which preserves the information association between the prototype and the training image patches while avoiding the sharp change of the network structure caused by the projection operation, thus avoiding its negative impact on the classification performance. Experiments on the CUB-200-2011 and Stanford Cars datasets show that ProtoSolo achieves superior performance in classification tasks and reaches the best level in terms of cognitive complexity of explanations compared to state-of-the-art interpretable methods. The code is available at https://github.com/pyt19/ProtoSolo.
AFiRe: Anatomy-Driven Self-Supervised Learning for Fine-Grained Representation in Radiographic Images
Apr 15, 2025



Current self-supervised methods, such as contrastive learning, predominantly focus on global discrimination, neglecting the critical fine-grained anatomical details required for accurate radiographic analysis. To address this challenge, we propose an Anatomy-driven self-supervised framework for enhancing Fine-grained Representation in radiographic image analysis (AFiRe). The core idea of AFiRe is to align the anatomical consistency with the unique token-processing characteristics of Vision Transformer. Specifically, AFiRe synergistically performs two self-supervised schemes: (i) Token-wise anatomy-guided contrastive learning, which aligns image tokens based on structural and categorical consistency, thereby enhancing fine-grained spatial-anatomical discrimination; (ii) Pixel-level anomaly-removal restoration, which particularly focuses on local anomalies, thereby refining the learned discrimination with detailed geometrical information. Additionally, we propose Synthetic Lesion Mask to enhance anatomical diversity while preserving intra-consistency, which is typically corrupted by traditional data augmentations, such as Cropping and Affine transformations. Experimental results show that AFiRe: (i) provides robust anatomical discrimination, achieving more cohesive feature clusters compared to state-of-the-art contrastive learning methods; (ii) demonstrates superior generalization, surpassing 7 radiography-specific self-supervised methods in multi-label classification tasks with limited labeling; and (iii) integrates fine-grained information, enabling precise anomaly detection using only image-level annotations.
Enhancing Generalized Few-Shot Semantic Segmentation via Effective Knowledge Transfer
Dec 20, 2024
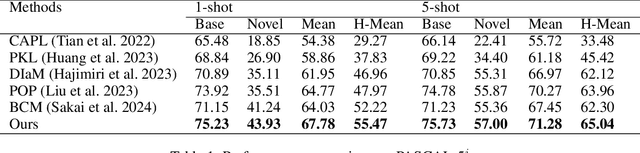


Generalized few-shot semantic segmentation (GFSS) aims to segment objects of both base and novel classes, using sufficient samples of base classes and few samples of novel classes. Representative GFSS approaches typically employ a two-phase training scheme, involving base class pre-training followed by novel class fine-tuning, to learn the classifiers for base and novel classes respectively. Nevertheless, distribution gap exists between base and novel classes in this process. To narrow this gap, we exploit effective knowledge transfer from base to novel classes. First, a novel prototype modulation module is designed to modulate novel class prototypes by exploiting the correlations between base and novel classes. Second, a novel classifier calibration module is proposed to calibrate the weight distribution of the novel classifier according to that of the base classifier. Furthermore, existing GFSS approaches suffer from a lack of contextual information for novel classes due to their limited samples, we thereby introduce a context consistency learning scheme to transfer the contextual knowledge from base to novel classes. Extensive experiments on PASCAL-5$^i$ and COCO-20$^i$ demonstrate that our approach significantly enhances the state of the art in the GFSS setting. The code is available at: https://github.com/HHHHedy/GFSS-EKT.
Visual Neural Decoding via Improved Visual-EEG Semantic Consistency
Aug 13, 2024Visual neural decoding refers to the process of extracting and interpreting original visual experiences from human brain activity. Recent advances in metric learning-based EEG visual decoding methods have delivered promising results and demonstrated the feasibility of decoding novel visual categories from brain activity. However, methods that directly map EEG features to the CLIP embedding space may introduce mapping bias and cause semantic inconsistency among features, thereby degrading alignment and impairing decoding performance. To further explore the semantic consistency between visual and neural signals. In this work, we construct a joint semantic space and propose a Visual-EEG Semantic Decouple Framework that explicitly extracts the semantic-related features of these two modalities to facilitate optimal alignment. Specifically, a cross-modal information decoupling module is introduced to guide the extraction of semantic-related information from modalities. Then, by quantifying the mutual information between visual image and EEG features, we observe a strong positive correlation between the decoding performance and the magnitude of mutual information. Furthermore, inspired by the mechanisms of visual object understanding from neuroscience, we propose an intra-class geometric consistency approach during the alignment process. This strategy maps visual samples within the same class to consistent neural patterns, which further enhances the robustness and the performance of EEG visual decoding. Experiments on a large Image-EEG dataset show that our method achieves state-of-the-art results in zero-shot neural decoding tasks.
HGL: Hierarchical Geometry Learning for Test-time Adaptation in 3D Point Cloud Segmentation
Jul 17, 2024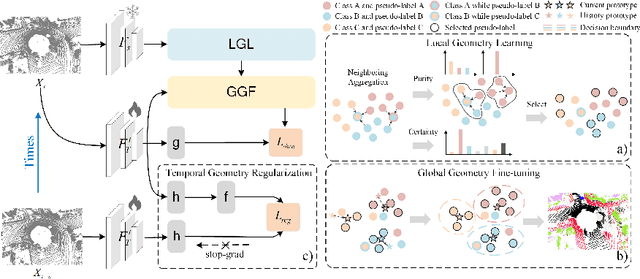
3D point cloud segmentation has received significant interest for its growing applications. However, the generalization ability of models suffers in dynamic scenarios due to the distribution shift between test and training data. To promote robustness and adaptability across diverse scenarios, test-time adaptation (TTA) has recently been introduced. Nevertheless, most existing TTA methods are developed for images, and limited approaches applicable to point clouds ignore the inherent hierarchical geometric structures in point cloud streams, i.e., local (point-level), global (object-level), and temporal (frame-level) structures. In this paper, we delve into TTA in 3D point cloud segmentation and propose a novel Hierarchical Geometry Learning (HGL) framework. HGL comprises three complementary modules from local, global to temporal learning in a bottom-up manner.Technically, we first construct a local geometry learning module for pseudo-label generation. Next, we build prototypes from the global geometry perspective for pseudo-label fine-tuning. Furthermore, we introduce a temporal consistency regularization module to mitigate negative transfer. Extensive experiments on four datasets demonstrate the effectiveness and superiority of our HGL. Remarkably, on the SynLiDAR to SemanticKITTI task, HGL achieves an overall mIoU of 46.91\%, improving GIPSO by 3.0\% and significantly reducing the required adaptation time by 80\%. The code is available at https://github.com/tpzou/HGL.
Hierarchical Salient Patch Identification for Interpretable Fundus Disease Localization
May 23, 2024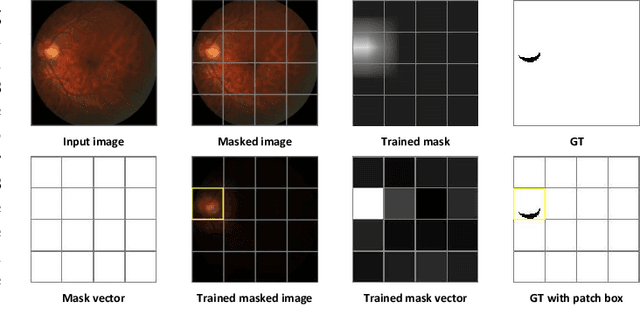
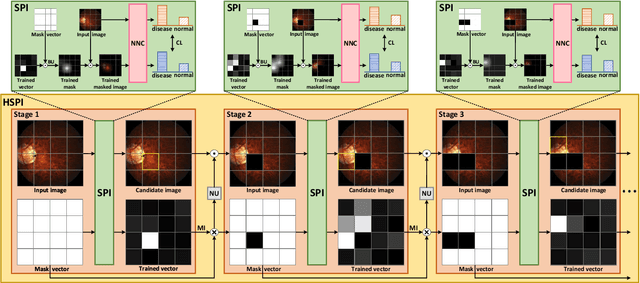
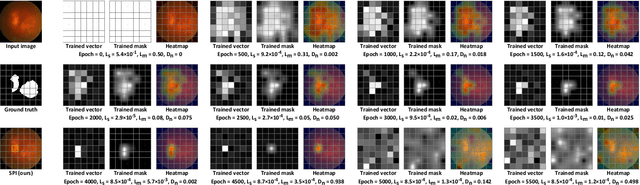
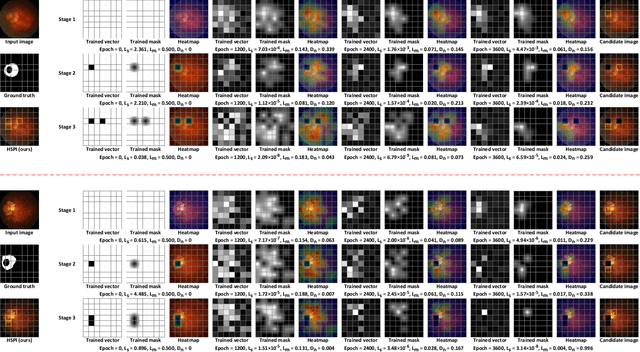
With the widespread application of deep learning technology in medical image analysis, how to effectively explain model decisions and improve diagnosis accuracy has become an urgent problem that needs to be solved. Attribution methods have become a key tool to help doctors better understand the diagnostic basis of models, and they are used to explain and localize diseases in medical images. However, previous methods suffer from inaccurate and incomplete localization problems for fundus diseases with complex and diverse structures. In order to solve the above problems, we propose a weakly supervised interpretable fundus disease localization method hierarchical salient patch identification (HSPI), which can achieve interpretable disease localization using only image-level labels and neural network classifiers. First, we proposed salient patch identification (SPI), which divides the image into several patches and optimizes consistency loss to identify which patch in the input image is most important for decision-making to locate the disease. Secondly, we propose a hierarchical identification strategy to force SPI to analyze the importance of different areas to neural network classifiers decision-making to comprehensively locate disease areas. Then, we introduced conditional peak focusing to ensure that the mask vector can accurately locate the decision area. Finally, we also propose patch selection based on multi-size intersection to filter out incorrectly or additionally identified non-disease regions. We conduct disease localization experiments on medical image datasets and achieve the best performance on multiple evaluation metrics compared with previous interpretable attribution methods. We performed additional ablation studies to verify the effectiveness of each method.
MAP: MAsk-Pruning for Source-Free Model Intellectual Property Protection
Mar 07, 2024Deep learning has achieved remarkable progress in various applications, heightening the importance of safeguarding the intellectual property (IP) of well-trained models. It entails not only authorizing usage but also ensuring the deployment of models in authorized data domains, i.e., making models exclusive to certain target domains. Previous methods necessitate concurrent access to source training data and target unauthorized data when performing IP protection, making them risky and inefficient for decentralized private data. In this paper, we target a practical setting where only a well-trained source model is available and investigate how we can realize IP protection. To achieve this, we propose a novel MAsk Pruning (MAP) framework. MAP stems from an intuitive hypothesis, i.e., there are target-related parameters in a well-trained model, locating and pruning them is the key to IP protection. Technically, MAP freezes the source model and learns a target-specific binary mask to prevent unauthorized data usage while minimizing performance degradation on authorized data. Moreover, we introduce a new metric aimed at achieving a better balance between source and target performance degradation. To verify the effectiveness and versatility, we have evaluated MAP in a variety of scenarios, including vanilla source-available, practical source-free, and challenging data-free. Extensive experiments indicate that MAP yields new state-of-the-art performance.
LEAD: Learning Decomposition for Source-free Universal Domain Adaptation
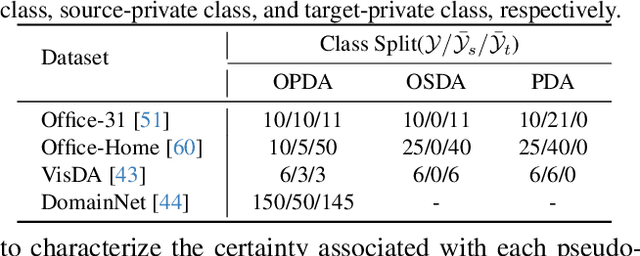
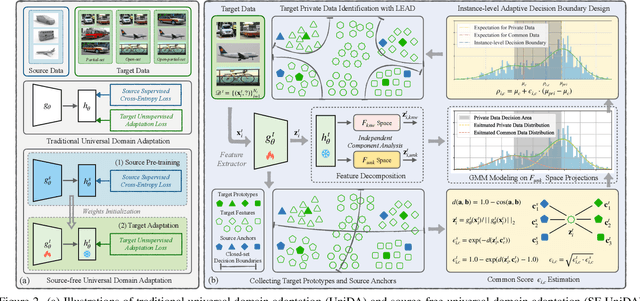
Mar 06, 2024
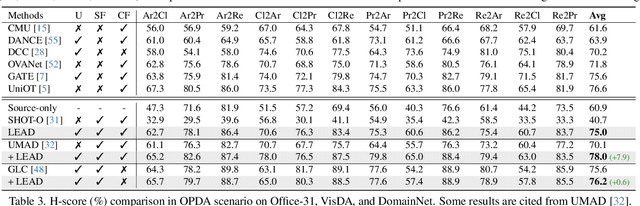
Universal Domain Adaptation (UniDA) targets knowledge transfer in the presence of both covariate and label shifts. Recently, Source-free Universal Domain Adaptation (SF-UniDA) has emerged to achieve UniDA without access to source data, which tends to be more practical due to data protection policies. The main challenge lies in determining whether covariate-shifted samples belong to target-private unknown categories. Existing methods tackle this either through hand-crafted thresholding or by developing time-consuming iterative clustering strategies. In this paper, we propose a new idea of LEArning Decomposition (LEAD), which decouples features into source-known and -unknown components to identify target-private data. Technically, LEAD initially leverages the orthogonal decomposition analysis for feature decomposition. Then, LEAD builds instance-level decision boundaries to adaptively identify target-private data. Extensive experiments across various UniDA scenarios have demonstrated the effectiveness and superiority of LEAD. Notably, in the OPDA scenario on VisDA dataset, LEAD outperforms GLC by 3.5% overall H-score and reduces 75% time to derive pseudo-labeling decision boundaries. Besides, LEAD is also appealing in that it is complementary to most existing methods. The code is available at https://github.com/ispc-lab/LEAD.