 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUrbanCraft: Urban View Extrapolation via Hierarchical Sem-Geometric Priors
May 29, 2025

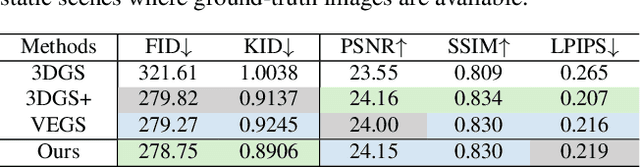
Existing neural rendering-based urban scene reconstruction methods mainly focus on the Interpolated View Synthesis (IVS) setting that synthesizes from views close to training camera trajectory. However, IVS can not guarantee the on-par performance of the novel view outside the training camera distribution (\textit{e.g.}, looking left, right, or downwards), which limits the generalizability of the urban reconstruction application. Previous methods have optimized it via image diffusion, but they fail to handle text-ambiguous or large unseen view angles due to coarse-grained control of text-only diffusion. In this paper, we design UrbanCraft, which surmounts the Extrapolated View Synthesis (EVS) problem using hierarchical sem-geometric representations serving as additional priors. Specifically, we leverage the partially observable scene to reconstruct coarse semantic and geometric primitives, establishing a coarse scene-level prior through an occupancy grid as the base representation. Additionally, we incorporate fine instance-level priors from 3D bounding boxes to enhance object-level details and spatial relationships. Building on this, we propose the \textbf{H}ierarchical \textbf{S}emantic-Geometric-\textbf{G}uided Variational Score Distillation (HSG-VSD), which integrates semantic and geometric constraints from pretrained UrbanCraft2D into the score distillation sampling process, forcing the distribution to be consistent with the observable scene. Qualitative and quantitative comparisons demonstrate the effectiveness of our methods on EVS problem.
Range and Bird's Eye View Fused Cross-Modal Visual Place Recognition
Feb 17, 2025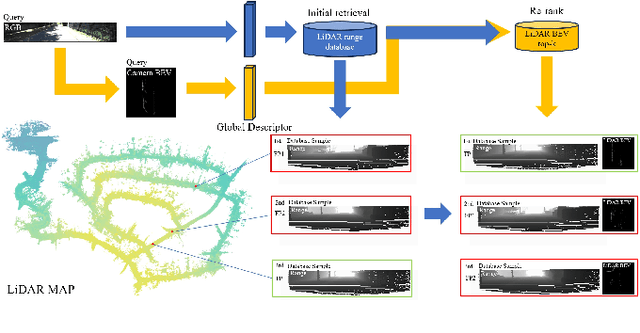
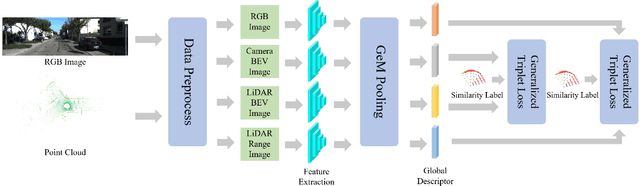
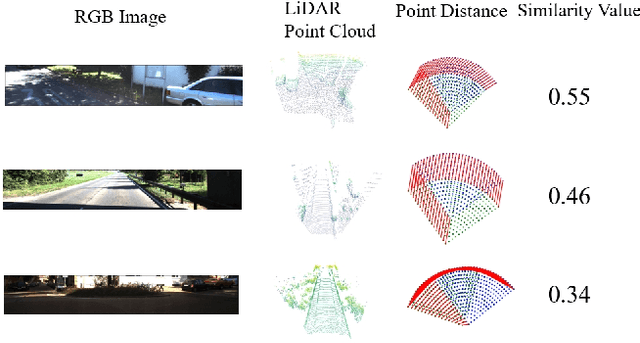
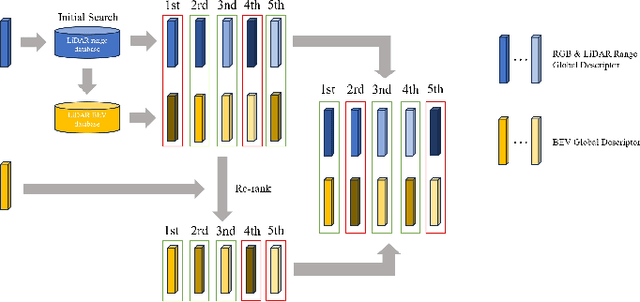
Image-to-point cloud cross-modal Visual Place Recognition (VPR) is a challenging task where the query is an RGB image, and the database samples are LiDAR point clouds. Compared to single-modal VPR, this approach benefits from the widespread availability of RGB cameras and the robustness of point clouds in providing accurate spatial geometry and distance information. However, current methods rely on intermediate modalities that capture either the vertical or horizontal field of view, limiting their ability to fully exploit the complementary information from both sensors. In this work, we propose an innovative initial retrieval + re-rank method that effectively combines information from range (or RGB) images and Bird's Eye View (BEV) images. Our approach relies solely on a computationally efficient global descriptor similarity search process to achieve re-ranking. Additionally, we introduce a novel similarity label supervision technique to maximize the utility of limited training data. Specifically, we employ points average distance to approximate appearance similarity and incorporate an adaptive margin, based on similarity differences, into the vanilla triplet loss. Experimental results on the KITTI dataset demonstrate that our method significantly outperforms state-of-the-art approaches.
GSGTrack: Gaussian Splatting-Guided Object Pose Tracking from RGB Videos
Dec 03, 2024
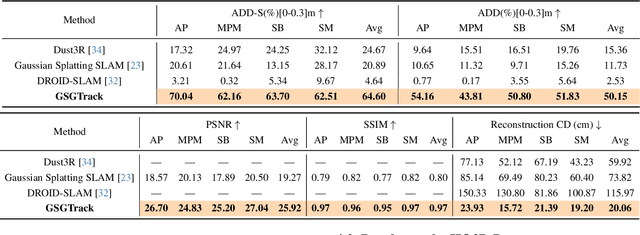
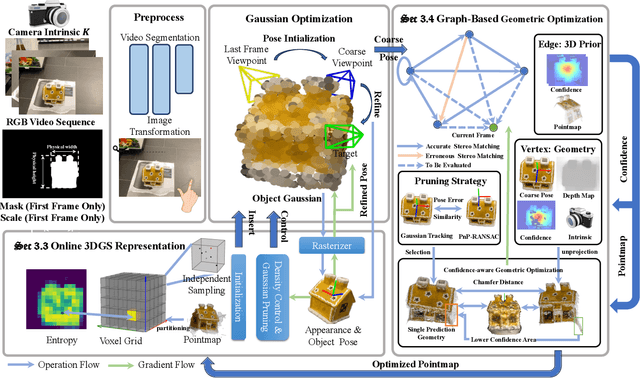
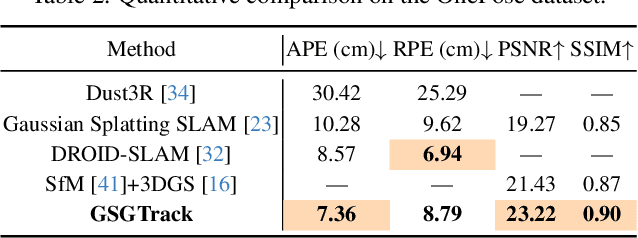
Tracking the 6DoF pose of unknown objects in monocular RGB video sequences is crucial for robotic manipulation. However, existing approaches typically rely on accurate depth information, which is non-trivial to obtain in real-world scenarios. Although depth estimation algorithms can be employed, geometric inaccuracy can lead to failures in RGBD-based pose tracking methods. To address this challenge, we introduce GSGTrack, a novel RGB-based pose tracking framework that jointly optimizes geometry and pose. Specifically, we adopt 3D Gaussian Splatting to create an optimizable 3D representation, which is learned simultaneously with a graph-based geometry optimization to capture the object's appearance features and refine its geometry. However, the joint optimization process is susceptible to perturbations from noisy pose and geometry data. Thus, we propose an object silhouette loss to address the issue of pixel-wise loss being overly sensitive to pose noise during tracking. To mitigate the geometric ambiguities caused by inaccurate depth information, we propose a geometry-consistent image pair selection strategy, which filters out low-confidence pairs and ensures robust geometric optimization. Extensive experiments on the OnePose and HO3D datasets demonstrate the effectiveness of GSGTrack in both 6DoF pose tracking and object reconstruction.
HGL: Hierarchical Geometry Learning for Test-time Adaptation in 3D Point Cloud Segmentation
Jul 17, 2024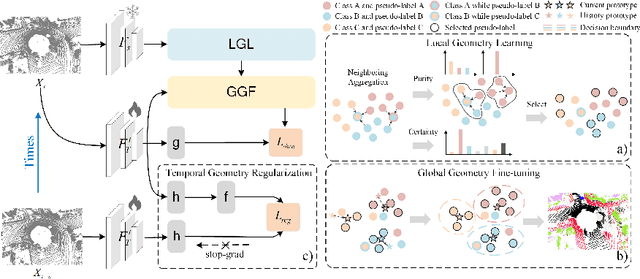
3D point cloud segmentation has received significant interest for its growing applications. However, the generalization ability of models suffers in dynamic scenarios due to the distribution shift between test and training data. To promote robustness and adaptability across diverse scenarios, test-time adaptation (TTA) has recently been introduced. Nevertheless, most existing TTA methods are developed for images, and limited approaches applicable to point clouds ignore the inherent hierarchical geometric structures in point cloud streams, i.e., local (point-level), global (object-level), and temporal (frame-level) structures. In this paper, we delve into TTA in 3D point cloud segmentation and propose a novel Hierarchical Geometry Learning (HGL) framework. HGL comprises three complementary modules from local, global to temporal learning in a bottom-up manner.Technically, we first construct a local geometry learning module for pseudo-label generation. Next, we build prototypes from the global geometry perspective for pseudo-label fine-tuning. Furthermore, we introduce a temporal consistency regularization module to mitigate negative transfer. Extensive experiments on four datasets demonstrate the effectiveness and superiority of our HGL. Remarkably, on the SynLiDAR to SemanticKITTI task, HGL achieves an overall mIoU of 46.91\%, improving GIPSO by 3.0\% and significantly reducing the required adaptation time by 80\%. The code is available at https://github.com/tpzou/HGL.
ELF-UA: Efficient Label-Free User Adaptation in Gaze Estimation
Jun 13, 2024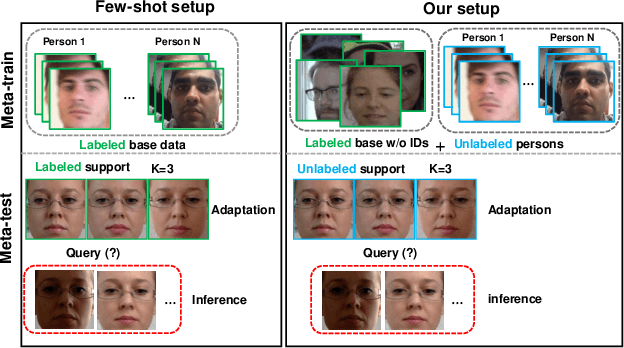

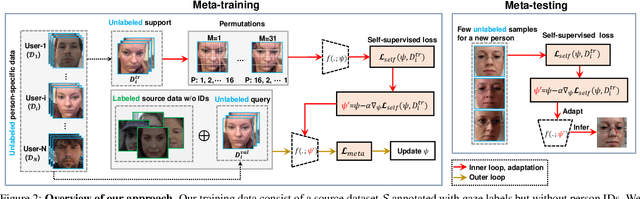
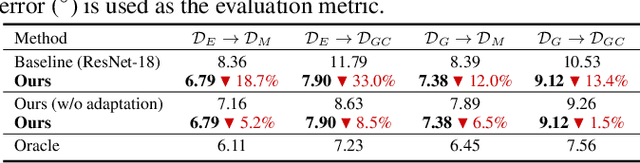
We consider the problem of user-adaptive 3D gaze estimation. The performance of person-independent gaze estimation is limited due to interpersonal anatomical differences. Our goal is to provide a personalized gaze estimation model specifically adapted to a target user. Previous work on user-adaptive gaze estimation requires some labeled images of the target person data to fine-tune the model at test time. However, this can be unrealistic in real-world applications, since it is cumbersome for an end-user to provide labeled images. In addition, previous work requires the training data to have both gaze labels and person IDs. This data requirement makes it infeasible to use some of the available data. To tackle these challenges, this paper proposes a new problem called efficient label-free user adaptation in gaze estimation. Our model only needs a few unlabeled images of a target user for the model adaptation. During offline training, we have some labeled source data without person IDs and some unlabeled person-specific data. Our proposed method uses a meta-learning approach to learn how to adapt to a new user with only a few unlabeled images. Our key technical innovation is to use a generalization bound from domain adaptation to define the loss function in meta-learning, so that our method can effectively make use of both the labeled source data and the unlabeled person-specific data during training. Extensive experiments validate the effectiveness of our method on several challenging benchmarks.
GLC++: Source-Free Universal Domain Adaptation through Global-Local Clustering and Contrastive Affinity Learning
Mar 21, 2024



Deep neural networks often exhibit sub-optimal performance under covariate and category shifts. Source-Free Domain Adaptation (SFDA) presents a promising solution to this dilemma, yet most SFDA approaches are restricted to closed-set scenarios. In this paper, we explore Source-Free Universal Domain Adaptation (SF-UniDA) aiming to accurately classify "known" data belonging to common categories and segregate them from target-private "unknown" data. We propose a novel Global and Local Clustering (GLC) technique, which comprises an adaptive one-vs-all global clustering algorithm to discern between target classes, complemented by a local k-NN clustering strategy to mitigate negative transfer. Despite the effectiveness, the inherent closed-set source architecture leads to uniform treatment of "unknown" data, impeding the identification of distinct "unknown" categories. To address this, we evolve GLC to GLC++, integrating a contrastive affinity learning strategy. We examine the superiority of GLC and GLC++ across multiple benchmarks and category shift scenarios. Remarkably, in the most challenging open-partial-set scenarios, GLC and GLC++ surpass GATE by 16.7% and 18.6% in H-score on VisDA, respectively. GLC++ enhances the novel category clustering accuracy of GLC by 4.3% in open-set scenarios on Office-Home. Furthermore, the introduced contrastive learning strategy not only enhances GLC but also significantly facilitates existing methodologies.
MAP: MAsk-Pruning for Source-Free Model Intellectual Property Protection
Mar 07, 2024Deep learning has achieved remarkable progress in various applications, heightening the importance of safeguarding the intellectual property (IP) of well-trained models. It entails not only authorizing usage but also ensuring the deployment of models in authorized data domains, i.e., making models exclusive to certain target domains. Previous methods necessitate concurrent access to source training data and target unauthorized data when performing IP protection, making them risky and inefficient for decentralized private data. In this paper, we target a practical setting where only a well-trained source model is available and investigate how we can realize IP protection. To achieve this, we propose a novel MAsk Pruning (MAP) framework. MAP stems from an intuitive hypothesis, i.e., there are target-related parameters in a well-trained model, locating and pruning them is the key to IP protection. Technically, MAP freezes the source model and learns a target-specific binary mask to prevent unauthorized data usage while minimizing performance degradation on authorized data. Moreover, we introduce a new metric aimed at achieving a better balance between source and target performance degradation. To verify the effectiveness and versatility, we have evaluated MAP in a variety of scenarios, including vanilla source-available, practical source-free, and challenging data-free. Extensive experiments indicate that MAP yields new state-of-the-art performance.
LEAD: Learning Decomposition for Source-free Universal Domain Adaptation
Mar 06, 2024
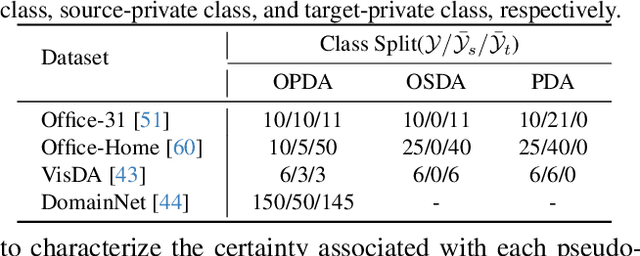
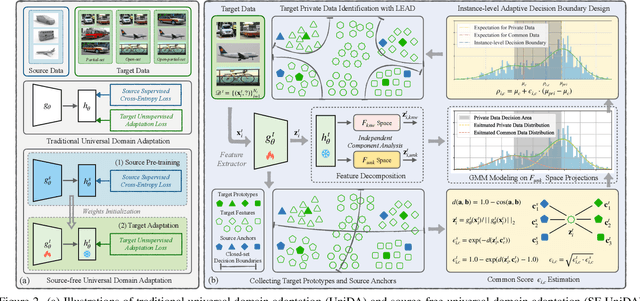
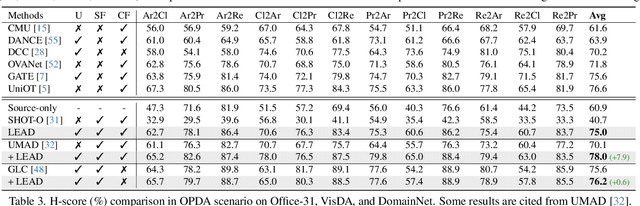
Universal Domain Adaptation (UniDA) targets knowledge transfer in the presence of both covariate and label shifts. Recently, Source-free Universal Domain Adaptation (SF-UniDA) has emerged to achieve UniDA without access to source data, which tends to be more practical due to data protection policies. The main challenge lies in determining whether covariate-shifted samples belong to target-private unknown categories. Existing methods tackle this either through hand-crafted thresholding or by developing time-consuming iterative clustering strategies. In this paper, we propose a new idea of LEArning Decomposition (LEAD), which decouples features into source-known and -unknown components to identify target-private data. Technically, LEAD initially leverages the orthogonal decomposition analysis for feature decomposition. Then, LEAD builds instance-level decision boundaries to adaptively identify target-private data. Extensive experiments across various UniDA scenarios have demonstrated the effectiveness and superiority of LEAD. Notably, in the OPDA scenario on VisDA dataset, LEAD outperforms GLC by 3.5% overall H-score and reduces 75% time to derive pseudo-labeling decision boundaries. Besides, LEAD is also appealing in that it is complementary to most existing methods. The code is available at https://github.com/ispc-lab/LEAD.
PCDepth: Pattern-based Complementary Learning for Monocular Depth Estimation by Best of Both Worlds
Feb 29, 2024Event cameras can record scene dynamics with high temporal resolution, providing rich scene details for monocular depth estimation (MDE) even at low-level illumination. Therefore, existing complementary learning approaches for MDE fuse intensity information from images and scene details from event data for better scene understanding. However, most methods directly fuse two modalities at pixel level, ignoring that the attractive complementarity mainly impacts high-level patterns that only occupy a few pixels. For example, event data is likely to complement contours of scene objects. In this paper, we discretize the scene into a set of high-level patterns to explore the complementarity and propose a Pattern-based Complementary learning architecture for monocular Depth estimation (PCDepth). Concretely, PCDepth comprises two primary components: a complementary visual representation learning module for discretizing the scene into high-level patterns and integrating complementary patterns across modalities and a refined depth estimator aimed at scene reconstruction and depth prediction while maintaining an efficiency-accuracy balance. Through pattern-based complementary learning, PCDepth fully exploits two modalities and achieves more accurate predictions than existing methods, especially in challenging nighttime scenarios. Extensive experiments on MVSEC and DSEC datasets verify the effectiveness and superiority of our PCDepth. Remarkably, compared with state-of-the-art, PCDepth achieves a 37.9% improvement in accuracy in MVSEC nighttime scenarios.
TMA: Temporal Motion Aggregation for Event-based Optical Flow
Mar 21, 2023Event cameras have the ability to record continuous and detailed trajectories of objects with high temporal resolution, thereby providing intuitive motion cues for optical flow estimation. Nevertheless, most existing learning-based approaches for event optical flow estimation directly remould the paradigm of conventional images by representing the consecutive event stream as static frames, ignoring the inherent temporal continuity of event data. In this paper, we argue that temporal continuity is a vital element of event-based optical flow and propose a novel Temporal Motion Aggregation (TMA) approach to unlock its potential. Technically, TMA comprises three components: an event splitting strategy to incorporate intermediate motion information underlying the temporal context, a linear lookup strategy to align temporally continuous motion features and a novel motion pattern aggregation module to emphasize consistent patterns for motion feature enhancement. By incorporating temporally continuous motion information, TMA can derive better flow estimates than existing methods at early stages, which not only enables TMA to obtain more accurate final predictions, but also greatly reduces the demand for a number of refinements. Extensive experiments on DESC-Flow and MVSEC datasets verify the effectiveness and superiority of our TMA. Remarkably, compared to E-RAFT, TMA achieves a 6% improvement in accuracy and a 40% reduction in inference time on DSEC-Flow.