 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeY-BotFrame: An Extensible Embodied Agent Framework for Quadruped Robot Assistants
Jun 11, 2026Quadruped robots are capable of traversing a wide range of complex terrains with high flexibility. As highly mobile ground-based intelligent platforms, they can be equipped with modules for navigation control, environmental perception, and intelligent interaction, thereby serving as real-world mobile deployment platforms for various algorithms. In this paper, we introduce Y-BotFrame, an extensible embodied platform that turns a robot into an intelligent ground assistant. Y-BotFrame integrates multimodal perception capabilities, including speech, vision, and LiDAR, and employs a large language model as the cognitive core for environmental understanding, contextual reasoning, and task planning. The system maps user natural-language instructions into executable embodied task units that can be carried out by the robot. Y-BotFrame supports natural interaction through voice commands and visual feedback, removing the need for a remote controller and enabling efficient human-robot collaboration. With a highly extensible framework, Y-BotFrame supports plug-and-play integration of new functional modules as well as modular upgrades and iterative development, offering a reference implementation for the real-world deployment of general-purpose, instruction-driven embodied agents.The supplementary video is available at https://xdei-group.github.io/Y-BotFrame/.
Dense Supervision, Sparse Updates: On the Sparsity and Geometry of On-Policy Distillation
Jun 11, 2026On-policy distillation (\textsc{OPD}) has recently become a prominent post-training recipe as it combines two desirable ingredients: on-policy student trajectories and dense teacher supervision, yet how this hybrid changes a model's parameters remains unclear. Across several language and vision-language model pairs and use cases, our analysis yields two main findings. On sparsity, \textsc{OPD}-style updates are small and coordinate-sparse. They are distributed across layers and are usually FFN-heavy. This sparse structure is operationally useful: training only the discovered subnetwork recovers nearly the same performance as full \textsc{OPD}. However, the sparsity-inducing SGD optimizer underperforms AdamW in our optimizer ablation, likely because dense teacher supervision preserves heterogeneous coordinate-wise gradient scales where AdamW's adaptive scaling remains useful. On geometry, the updates are numerically full-rank but spectrally concentrated; they lie mostly away from the principal singular subspaces of the source weights and fall disproportionately on coordinates where the source weights are close to zero. These findings suggest that dense teacher supervision does not turn \textsc{OPD} into ordinary dense parameter rewriting; instead, \textsc{OPD} retains important geometric signatures of on-policy post-training.
AerialClaw: An Open-Source Framework for LLM-Driven Autonomous Aerial Agents
Jun 10, 2026Unmanned aerial vehicles (UAVs) are increasingly used in inspection, search and rescue, environmental monitoring, and emergency response. However, most UAV applications still rely on pre-defined command sequences or task-specific pipelines, where developers manually connect perception, planning, flight control, simulation, logging, and safety modules. This limits the flexibility, reproducibility, and extensibility of autonomous aerial systems. This paper presents AerialClaw, an open-source software framework that enables UAVs to operate as decision-making aerial agents rather than merely command-following platforms. Given a natural-language mission, AerialClaw allows an LLM-based agent to understand the task, maintain context, invoke executable aerial skills, observe perception and runtime feedback, and iteratively update its decisions in a closed loop. The framework adopts a modular brain-skill-runtime architecture, combining hard skills for atomic UAV operations, Markdown-based soft skills for reusable task strategies, document-driven agent state and capability boundaries, memory-driven reflection, safety-oriented runtime validation, and platform-agnostic execution adapters. AerialClaw supports lightweight mock execution, PX4 SITL with Gazebo, and AirSim-based simulation, together with a web console, pluggable model backends, example missions, simulation assets, and staged deployment scripts. By combining standardized aerial skills, document-driven agent state, memory, and closed-loop LLM decision-making, AerialClaw provides a reproducible and extensible open-source framework for building UAV systems that can interpret missions, make decisions, execute skills, and adapt their behavior from feedback.
Benchmarking Egocentric Clinical Intent Understanding Capability for Medical Multimodal Large Language Models
Jan 11, 2026Medical Multimodal Large Language Models (Med-MLLMs) require egocentric clinical intent understanding for real-world deployment, yet existing benchmarks fail to evaluate this critical capability. To address these challenges, we introduce MedGaze-Bench, the first benchmark leveraging clinician gaze as a Cognitive Cursor to assess intent understanding across surgery, emergency simulation, and diagnostic interpretation. Our benchmark addresses three fundamental challenges: visual homogeneity of anatomical structures, strict temporal-causal dependencies in clinical workflows, and implicit adherence to safety protocols. We propose a Three-Dimensional Clinical Intent Framework evaluating: (1) Spatial Intent: discriminating precise targets amid visual noise, (2) Temporal Intent: inferring causal rationale through retrospective and prospective reasoning, and (3) Standard Intent: verifying protocol compliance through safety checks. Beyond accuracy metrics, we introduce Trap QA mechanisms to stress-test clinical reliability by penalizing hallucinations and cognitive sycophancy. Experiments reveal current MLLMs struggle with egocentric intent due to over-reliance on global features, leading to fabricated observations and uncritical acceptance of invalid instructions.
UrbanCraft: Urban View Extrapolation via Hierarchical Sem-Geometric Priors
May 29, 2025

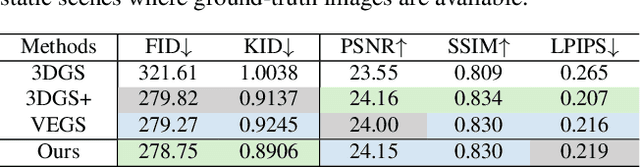
Existing neural rendering-based urban scene reconstruction methods mainly focus on the Interpolated View Synthesis (IVS) setting that synthesizes from views close to training camera trajectory. However, IVS can not guarantee the on-par performance of the novel view outside the training camera distribution (\textit{e.g.}, looking left, right, or downwards), which limits the generalizability of the urban reconstruction application. Previous methods have optimized it via image diffusion, but they fail to handle text-ambiguous or large unseen view angles due to coarse-grained control of text-only diffusion. In this paper, we design UrbanCraft, which surmounts the Extrapolated View Synthesis (EVS) problem using hierarchical sem-geometric representations serving as additional priors. Specifically, we leverage the partially observable scene to reconstruct coarse semantic and geometric primitives, establishing a coarse scene-level prior through an occupancy grid as the base representation. Additionally, we incorporate fine instance-level priors from 3D bounding boxes to enhance object-level details and spatial relationships. Building on this, we propose the \textbf{H}ierarchical \textbf{S}emantic-Geometric-\textbf{G}uided Variational Score Distillation (HSG-VSD), which integrates semantic and geometric constraints from pretrained UrbanCraft2D into the score distillation sampling process, forcing the distribution to be consistent with the observable scene. Qualitative and quantitative comparisons demonstrate the effectiveness of our methods on EVS problem.
GSGTrack: Gaussian Splatting-Guided Object Pose Tracking from RGB Videos
Dec 03, 2024
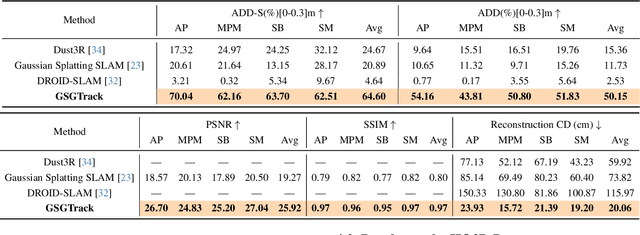
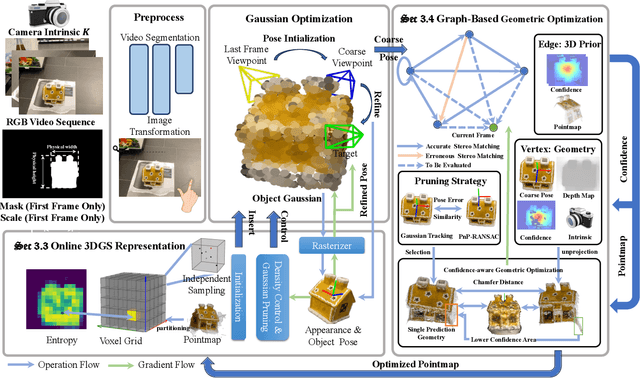
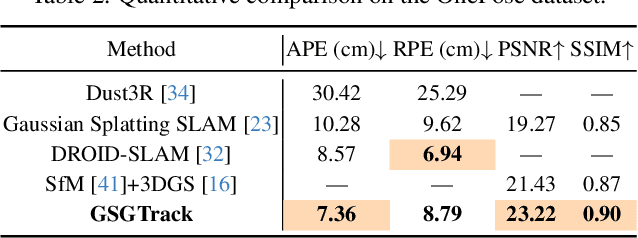
Tracking the 6DoF pose of unknown objects in monocular RGB video sequences is crucial for robotic manipulation. However, existing approaches typically rely on accurate depth information, which is non-trivial to obtain in real-world scenarios. Although depth estimation algorithms can be employed, geometric inaccuracy can lead to failures in RGBD-based pose tracking methods. To address this challenge, we introduce GSGTrack, a novel RGB-based pose tracking framework that jointly optimizes geometry and pose. Specifically, we adopt 3D Gaussian Splatting to create an optimizable 3D representation, which is learned simultaneously with a graph-based geometry optimization to capture the object's appearance features and refine its geometry. However, the joint optimization process is susceptible to perturbations from noisy pose and geometry data. Thus, we propose an object silhouette loss to address the issue of pixel-wise loss being overly sensitive to pose noise during tracking. To mitigate the geometric ambiguities caused by inaccurate depth information, we propose a geometry-consistent image pair selection strategy, which filters out low-confidence pairs and ensures robust geometric optimization. Extensive experiments on the OnePose and HO3D datasets demonstrate the effectiveness of GSGTrack in both 6DoF pose tracking and object reconstruction.
A convex formulation of covariate-adjusted Gaussian graphical models via natural parametrization
Oct 08, 2024
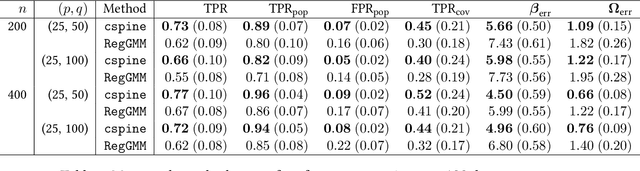

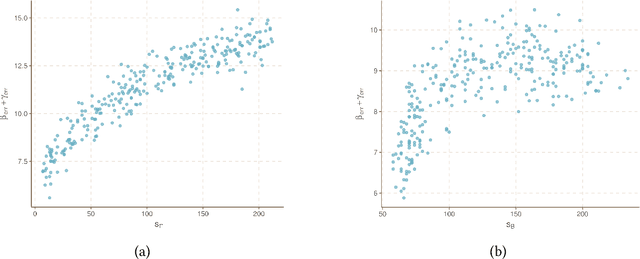
Gaussian graphical models (GGMs) are widely used for recovering the conditional independence structure among random variables. Recently, several key advances have been made to exploit an additional set of variables for better estimating the GGMs of the variables of interest. For example, in co-expression quantitative trait locus (eQTL) studies, both the mean expression level of genes as well as their pairwise conditional independence structure may be adjusted by genetic variants local to those genes. Existing methods to estimate covariate-adjusted GGMs either allow only the mean to depend on covariates or suffer from poor scaling assumptions due to the inherent non-convexity of simultaneously estimating the mean and precision matrix. In this paper, we propose a convex formulation that jointly estimates the covariate-adjusted mean and precision matrix by utilizing the natural parametrization of the multivariate Gaussian likelihood. This convexity yields theoretically better performance as the sparsity and dimension of the covariates grow large relative to the number of samples. We verify our theoretical results with numerical simulations and perform a reanalysis of an eQTL study of glioblastoma multiforme (GBM), an aggressive form of brain cancer.
S2RC-GCN: A Spatial-Spectral Reliable Contrastive Graph Convolutional Network for Complex Land Cover Classification Using Hyperspectral Images
Apr 01, 2024
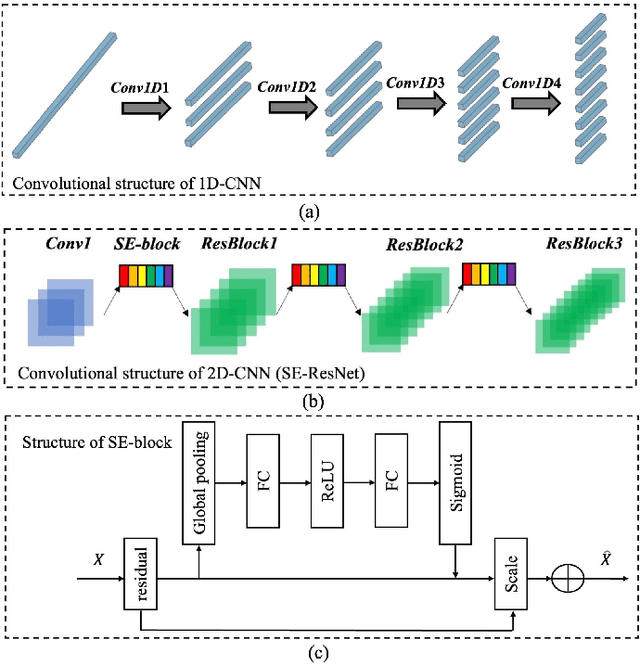


Spatial correlations between different ground objects are an important feature of mining land cover research. Graph Convolutional Networks (GCNs) can effectively capture such spatial feature representations and have demonstrated promising results in performing hyperspectral imagery (HSI) classification tasks of complex land. However, the existing GCN-based HSI classification methods are prone to interference from redundant information when extracting complex features. To classify complex scenes more effectively, this study proposes a novel spatial-spectral reliable contrastive graph convolutional classification framework named S2RC-GCN. Specifically, we fused the spectral and spatial features extracted by the 1D- and 2D-encoder, and the 2D-encoder includes an attention model to automatically extract important information. We then leveraged the fused high-level features to construct graphs and fed the resulting graphs into the GCNs to determine more effective graph representations. Furthermore, a novel reliable contrastive graph convolution was proposed for reliable contrastive learning to learn and fuse robust features. Finally, to test the performance of the model on complex object classification, we used imagery taken by Gaofen-5 in the Jiang Xia area to construct complex land cover datasets. The test results show that compared with other models, our model achieved the best results and effectively improved the classification performance of complex remote sensing imagery.
Implementation of Kalman Filter Approach for Active Noise Control by Using MATLAB: Dynamic Noise Cancellation
Feb 10, 2024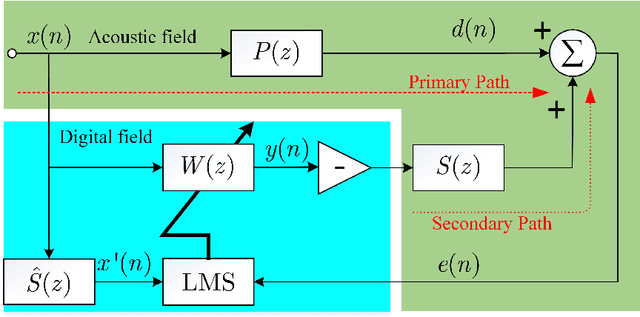
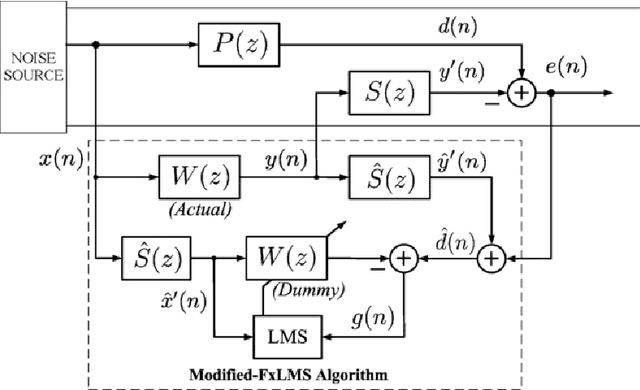
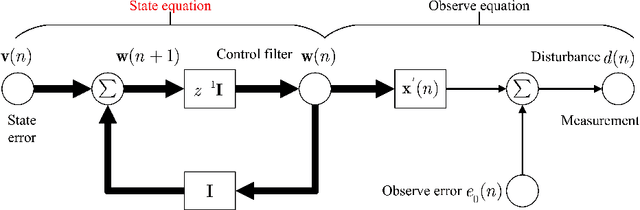
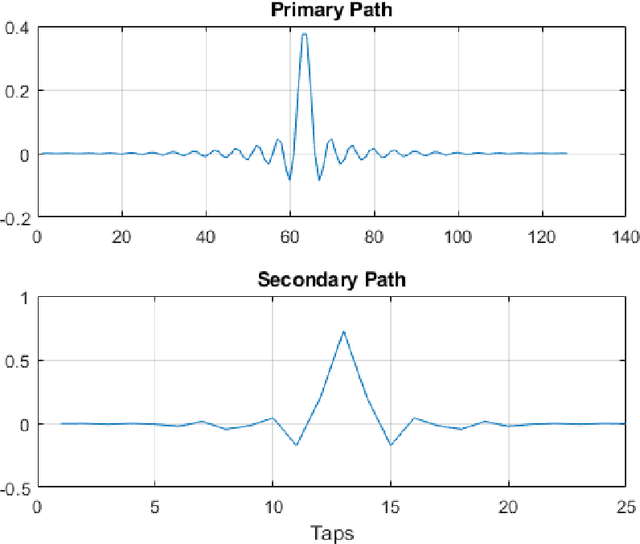
This article offers an elaborate description of a Kalman filter code employed in the active control system. Conventional active noise management methods usually employ an adaptive filter, such as the filtered reference least mean square (FxLMS) algorithm, to adjust to changes in the primary noise and acoustic environment. Nevertheless, the slow convergence characteristics of the FxLMS algorithm typically impact the effectiveness of reducing dynamic noise. Hence, this study suggests employing the Kalman filter in the active noise control (ANC) system to enhance the efficacy of noise reduction for dynamic noise. The ANC application effectively utilizes the Kalman filter with a novel dynamic ANC model. The numerical simulation revealed that the proposed Kalman filter exhibits superior convergence performance compared to the FxLMS algorithm for handling dynamic noise. The code is available on \href{https://github.com/ShiDongyuan/Kalman_Filter_for_ANC.git}{GitHub} and \href{https://www.mathworks.com/matlabcentral/fileexchange/159311-kalman-filter-for-active-noise-control}{MathWorks}.
One-Step Forward and Backtrack: Overcoming Zig-Zagging in Loss-Aware Quantization Training
Jan 30, 2024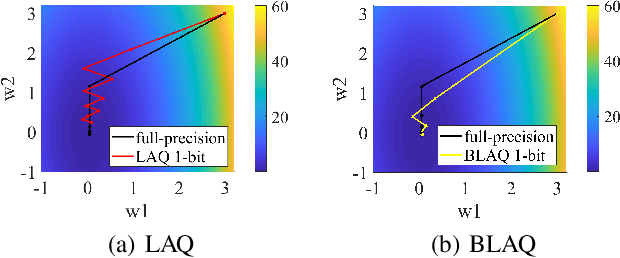


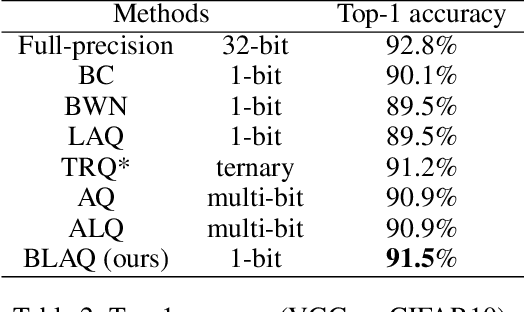
Weight quantization is an effective technique to compress deep neural networks for their deployment on edge devices with limited resources. Traditional loss-aware quantization methods commonly use the quantized gradient to replace the full-precision gradient. However, we discover that the gradient error will lead to an unexpected zig-zagging-like issue in the gradient descent learning procedures, where the gradient directions rapidly oscillate or zig-zag, and such issue seriously slows down the model convergence. Accordingly, this paper proposes a one-step forward and backtrack way for loss-aware quantization to get more accurate and stable gradient direction to defy this issue. During the gradient descent learning, a one-step forward search is designed to find the trial gradient of the next-step, which is adopted to adjust the gradient of current step towards the direction of fast convergence. After that, we backtrack the current step to update the full-precision and quantized weights through the current-step gradient and the trial gradient. A series of theoretical analysis and experiments on benchmark deep models have demonstrated the effectiveness and competitiveness of the proposed method, and our method especially outperforms others on the convergence performance.