 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Text to Simulation: A Multi-Agent LLM Workflow for Automated Chemical Process Design
Jan 11, 2026Process simulation is a critical cornerstone of chemical engineering design. Current automated chemical design methodologies focus mainly on various representations of process flow diagrams. However, transforming these diagrams into executable simulation flowsheets remains a time-consuming and labor-intensive endeavor, requiring extensive manual parameter configuration within simulation software. In this work, we propose a novel multi-agent workflow that leverages the semantic understanding capabilities of large language models(LLMs) and enables iterative interactions with chemical process simulation software, achieving end-to-end automated simulation from textual process specifications to computationally validated software configurations for design enhancement. Our approach integrates four specialized agents responsible for task understanding, topology generation, parameter configuration, and evaluation analysis, respectively, coupled with Enhanced Monte Carlo Tree Search to accurately interpret semantics and robustly generate configurations. Evaluated on Simona, a large-scale process description dataset, our method achieves a 31.1% improvement in the simulation convergence rate compared to state-of-the-art baselines and reduces the design time by 89. 0% compared to the expert manual design. This work demonstrates the potential of AI-assisted chemical process design, which bridges the gap between conceptual design and practical implementation. Our workflow is applicable to diverse process-oriented industries, including pharmaceuticals, petrochemicals, food processing, and manufacturing, offering a generalizable solution for automated process design.
Adversarial Semantic Augmentation for Training Generative Adversarial Networks under Limited Data
Feb 02, 2025Generative adversarial networks (GANs) have made remarkable achievements in synthesizing images in recent years. Typically, training GANs requires massive data, and the performance of GANs deteriorates significantly when training data is limited. To improve the synthesis performance of GANs in low-data regimes, existing approaches use various data augmentation techniques to enlarge the training sets. However, it is identified that these augmentation techniques may leak or even alter the data distribution. To remedy this, we propose an adversarial semantic augmentation (ASA) technique to enlarge the training data at the semantic level instead of the image level. Concretely, considering semantic features usually encode informative information of images, we estimate the covariance matrices of semantic features for both real and generated images to find meaningful transformation directions. Such directions translate original features to another semantic representation, e.g., changing the backgrounds or expressions of the human face dataset. Moreover, we derive an upper bound of the expected adversarial loss. By optimizing the upper bound, our semantic augmentation is implicitly achieved. Such design avoids redundant sampling of the augmented features and introduces negligible computation overhead, making our approach computation efficient. Extensive experiments on both few-shot and large-scale datasets demonstrate that our method consistently improve the synthesis quality under various data regimes, and further visualized and analytic results suggesting satisfactory versatility of our proposed method.
Differentiable Distributionally Robust Optimization Layers
Jun 24, 2024



In recent years, there has been a growing research interest in decision-focused learning, which embeds optimization problems as a layer in learning pipelines and demonstrates a superior performance than the prediction-focused approach. However, for distributionally robust optimization (DRO), a popular paradigm for decision-making under uncertainty, it is still unknown how to embed it as a layer, i.e., how to differentiate decisions with respect to an ambiguity set. In this paper, we develop such differentiable DRO layers for generic mixed-integer DRO problems with parameterized second-order conic ambiguity sets and discuss its extension to Wasserstein ambiguity sets. To differentiate the mixed-integer decisions, we propose a novel dual-view methodology by handling continuous and discrete parts of decisions via different principles. Specifically, we construct a differentiable energy-based surrogate to implement the dual-view methodology and use importance sampling to estimate its gradient. We further prove that such a surrogate enjoys the asymptotic convergency under regularization. As an application of the proposed differentiable DRO layers, we develop a novel decision-focused learning pipeline for contextual distributionally robust decision-making tasks and compare it with the prediction-focused approach in experiments.
Knowledge-Assisted Dual-Stage Evolutionary Optimization of Large-Scale Crude Oil Scheduling
Jan 09, 2024



With the scaling up of crude oil scheduling in modern refineries, large-scale crude oil scheduling problems (LSCOSPs) emerge with thousands of binary variables and non-linear constraints, which are challenging to be optimized by traditional optimization methods. To solve LSCOSPs, we take the practical crude oil scheduling from a marine-access refinery as an example and start with modeling LSCOSPs from crude unloading, transportation, crude distillation unit processing, and inventory management of intermediate products. On the basis of the proposed model, a dual-stage evolutionary algorithm driven by heuristic rules (denoted by DSEA/HR) is developed, where the dual-stage search mechanism consists of global search and local refinement. In the global search stage, we devise several heuristic rules based on the empirical operating knowledge to generate a well-performing initial population and accelerate convergence in the mixed variables space. In the local refinement stage, a repair strategy is proposed to move the infeasible solutions towards feasible regions by further optimizing the local continuous variables. During the whole evolutionary process, the proposed dual-stage framework plays a crucial role in balancing exploration and exploitation. Experimental results have shown that DSEA/HR outperforms the state-of-the-art and widely-used mathematical programming methods and metaheuristic algorithms on LSCOSP instances within a reasonable time.
Towards Fairness-Aware Multi-Objective Optimization
Jul 22, 2022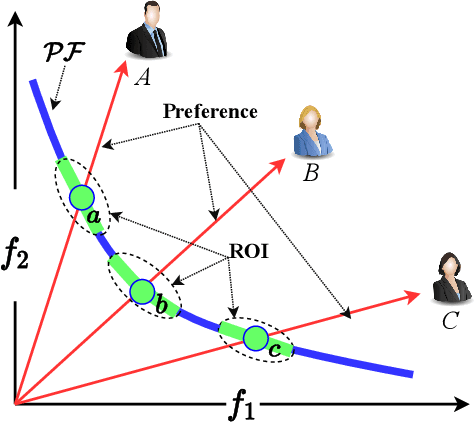
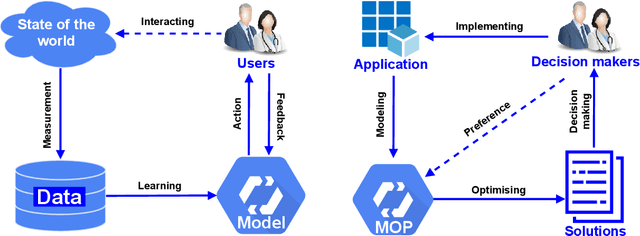
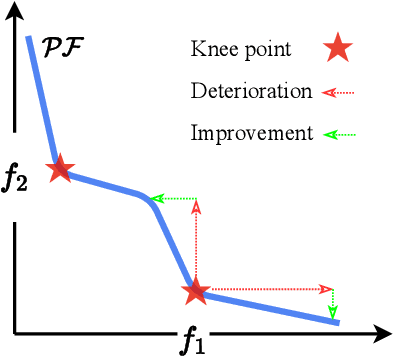
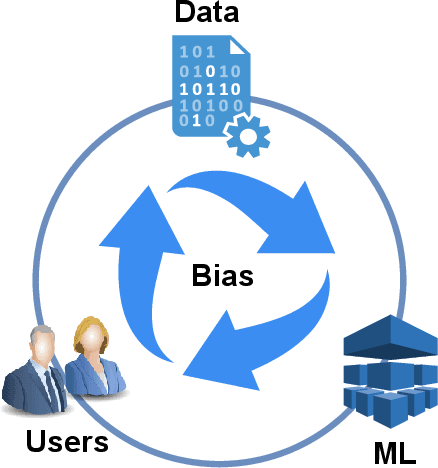
Recent years have seen the rapid development of fairness-aware machine learning in mitigating unfairness or discrimination in decision-making in a wide range of applications. However, much less attention has been paid to the fairness-aware multi-objective optimization, which is indeed commonly seen in real life, such as fair resource allocation problems and data driven multi-objective optimization problems. This paper aims to illuminate and broaden our understanding of multi-objective optimization from the perspective of fairness. To this end, we start with a discussion of user preferences in multi-objective optimization and then explore its relationship to fairness in machine learning and multi-objective optimization. Following the above discussions, representative cases of fairness-aware multiobjective optimization are presented, further elaborating the importance of fairness in traditional multi-objective optimization, data-driven optimization and federated optimization. Finally, challenges and opportunities in fairness-aware multi-objective optimization are addressed. We hope that this article makes a small step forward towards understanding fairness in the context of optimization and promote research interest in fairness-aware multi-objective optimization.
A Federated Data-Driven Evolutionary Algorithm for Expensive Multi/Many-objective Optimization
Jun 22, 2021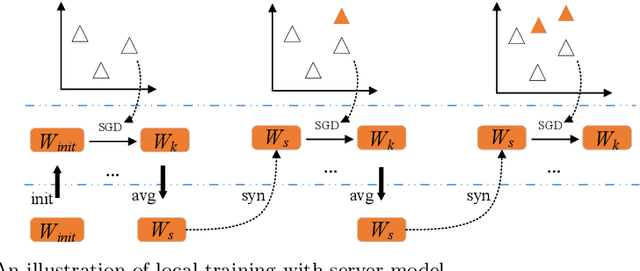
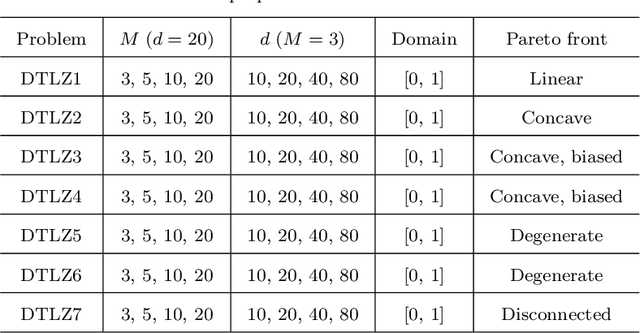

Data-driven optimization has found many successful applications in the real world and received increased attention in the field of evolutionary optimization. Most existing algorithms assume that the data used for optimization is always available on a central server for construction of surrogates. This assumption, however, may fail to hold when the data must be collected in a distributed way and is subject to privacy restrictions. This paper aims to propose a federated data-driven evolutionary multi-/many-objective optimization algorithm. To this end, we leverage federated learning for surrogate construction so that multiple clients collaboratively train a radial-basis-function-network as the global surrogate. Then a new federated acquisition function is proposed for the central server to approximate the objective values using the global surrogate and estimate the uncertainty level of the approximated objective values based on the local models. The performance of the proposed algorithm is verified on a series of multi/many-objective benchmark problems by comparing it with two state-of-the-art surrogate-assisted multi-objective evolutionary algorithms.
A Federated Data-Driven Evolutionary Algorithm
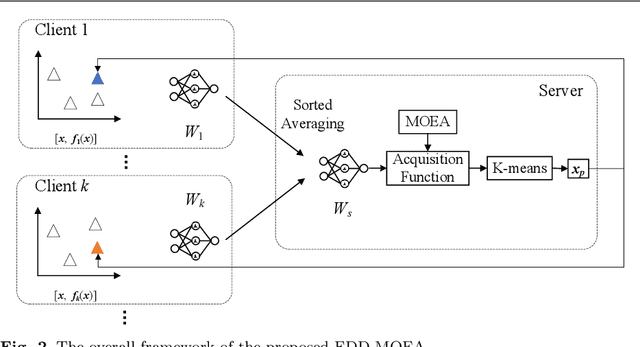
Feb 16, 2021
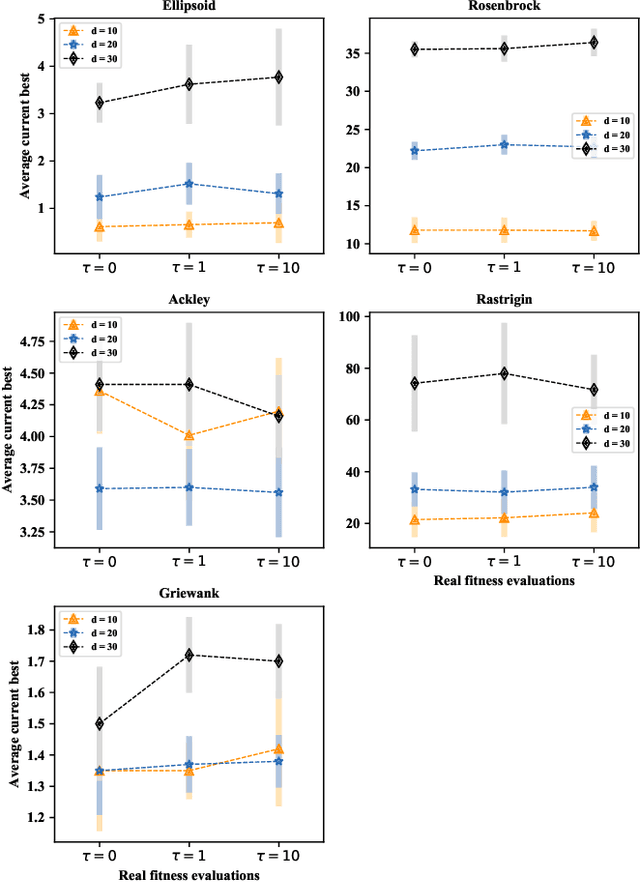
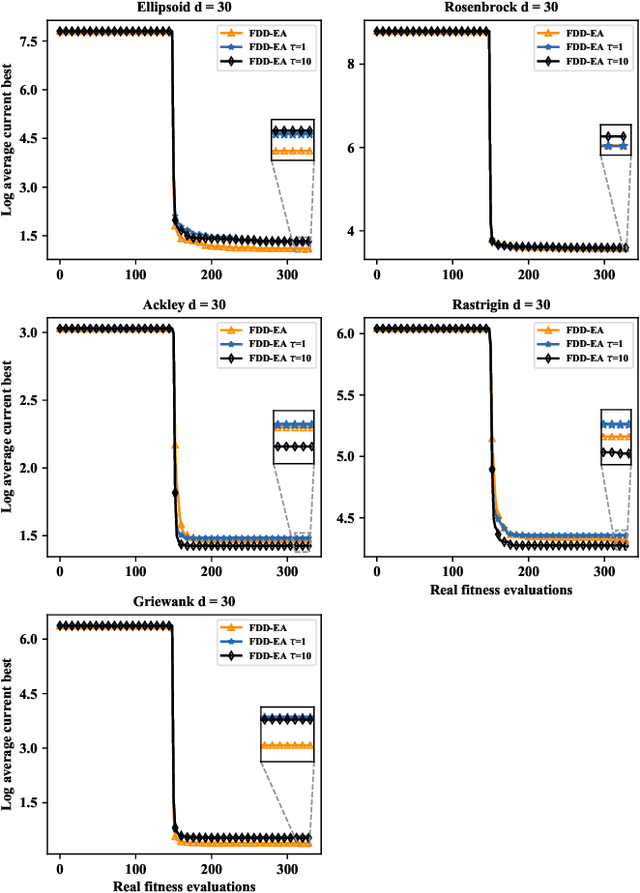
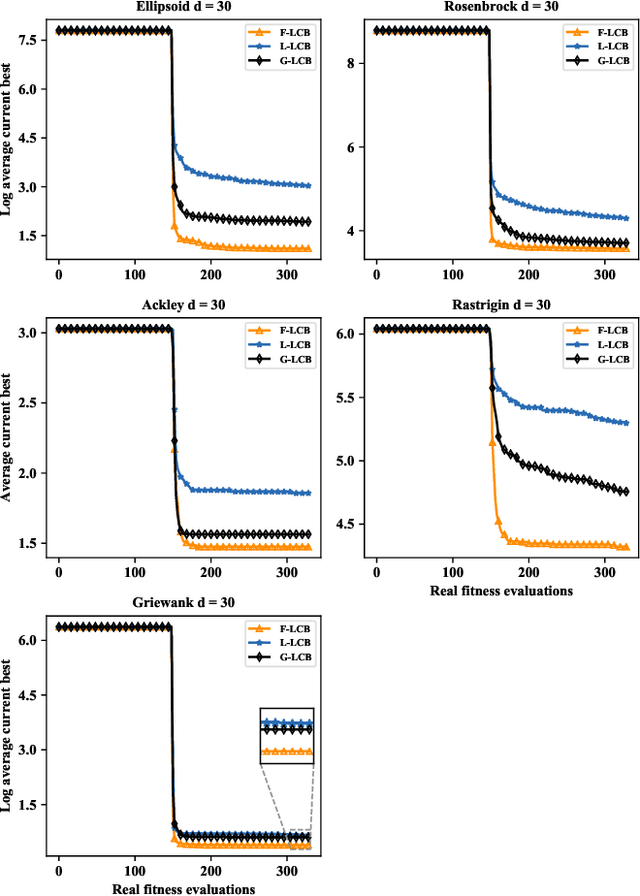
Data-driven evolutionary optimization has witnessed great success in solving complex real-world optimization problems. However, existing data-driven optimization algorithms require that all data are centrally stored, which is not always practical and may be vulnerable to privacy leakage and security threats if the data must be collected from different devices. To address the above issue, this paper proposes a federated data-driven evolutionary optimization framework that is able to perform data driven optimization when the data is distributed on multiple devices. On the basis of federated learning, a sorted model aggregation method is developed for aggregating local surrogates based on radial-basis-function networks. In addition, a federated surrogate management strategy is suggested by designing an acquisition function that takes into account the information of both the global and local surrogate models. Empirical studies on a set of widely used benchmark functions in the presence of various data distributions demonstrate the effectiveness of the proposed framework.
Ternary Compression for Communication-Efficient Federated Learning
Mar 07, 2020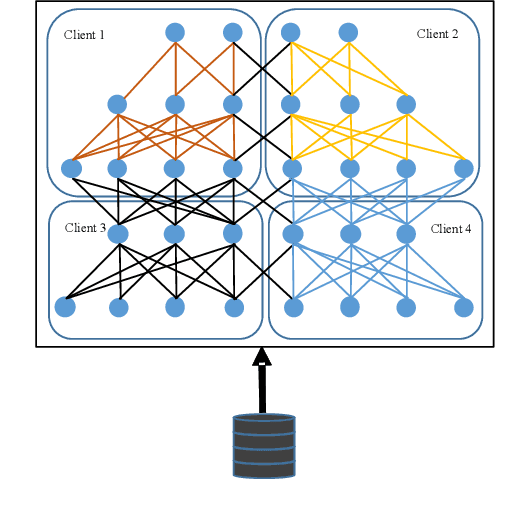
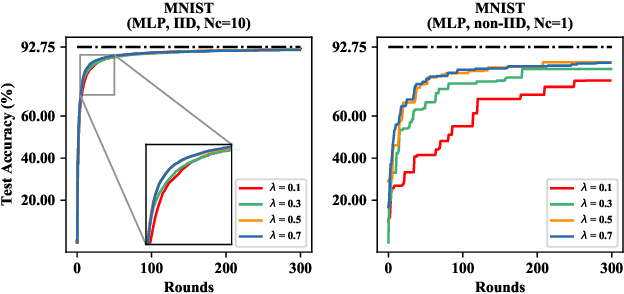
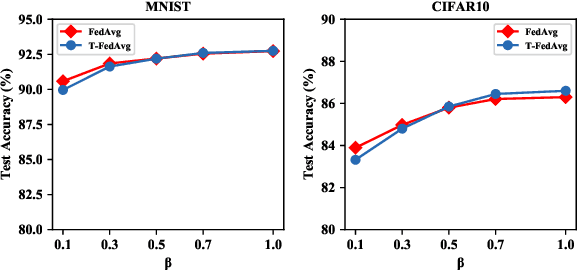
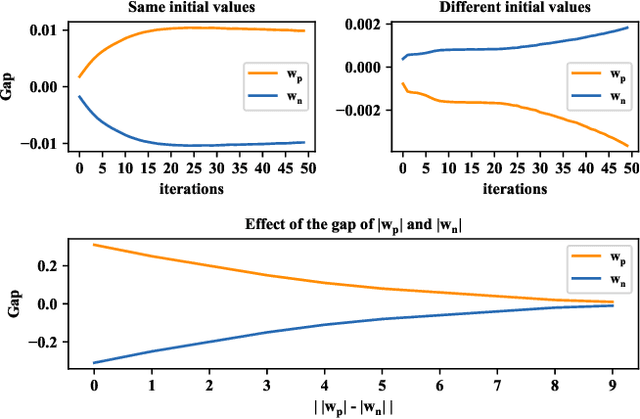
Learning over massive data stored in different locations is essential in many real-world applications. However, sharing data is full of challenges due to the increasing demands of privacy and security with the growing use of smart mobile devices and IoT devices. Federated learning provides a potential solution to privacy-preserving and secure machine learning, by means of jointly training a global model without uploading data distributed on multiple devices to a central server. However, most existing work on federated learning adopts machine learning models with full-precision weights, and almost all these models contain a large number of redundant parameters that do not need to be transmitted to the server, consuming an excessive amount of communication costs. To address this issue, we propose a federated trained ternary quantization (FTTQ) algorithm, which optimizes the quantized networks on the clients through a self-learning quantization factor. A convergence proof of the quantization factor and the unbiasedness of FTTQ is given. In addition, we propose a ternary federated averaging protocol (T-FedAvg) to reduce the upstream and downstream communication of federated learning systems. Empirical experiments are conducted to train widely used deep learning models on publicly available datasets, and our results demonstrate the effectiveness of FTTQ and T-FedAvg compared with the canonical federated learning algorithms in reducing communication costs and maintaining the learning performance.
An Overview of Perception and Decision-Making in Autonomous Systems in the Era of Learning
Feb 24, 2020Autonomous systems possess the features of inferring their own ego-motion, autonomously understanding their surroundings, and planning trajectories. With the applications of deep learning and reinforcement learning, the perception and decision-making abilities of autonomous systems are being efficiently addressed, and many new learning-based algorithms have surfaced with respect to autonomous perception and decision-making. In this review, we focus on the applications of learning-based approaches in perception and decision-making in autonomous systems, which is different from previous reviews that discussed traditional methods. First, we delineate the existing classical simultaneous localization and mapping (SLAM) solutions and review the environmental perception and understanding methods based on deep learning, including deep learning-based monocular depth estimation, ego-motion prediction, image enhancement, object detection, semantic segmentation, and their combinations with traditional SLAM frameworks. Second, we briefly summarize the existing motion planning techniques, such as path planning and trajectory planning methods, and discuss the navigation methods based on reinforcement learning. Finally, we examine the several challenges and promising directions discussed and concluded in related research for future works in the era of computer science, automatic control, and robotics.