 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent Systems: From Classical Paradigms to Large Foundation Model-Enabled Futures
Apr 20, 2026With the rapid advancement of artificial intelligence, multi-agent systems (MASs) are evolving from classical paradigms toward architectures built upon large foundation models (LFMs). This survey provides a systematic review and comparative analysis of classical MASs (CMASs) and LFM-based MASs (LMASs). First, within a closed-loop coordination framework, CMASs are reviewed across four fundamental dimensions: perception, communication, decision-making, and control. Beyond this framework, LMASs integrate LFMs to lift collaboration from low-level state exchanges to semantic-level reasoning, enabling more flexible coordination and improved adaptability across diverse scenarios. Then, a comparative analysis is conducted to contrast CMASs and LMASs across architecture, operating mechanism, adaptability, and application. Finally, future perspectives on MASs are presented, summarizing open challenges and potential research opportunities.
Universal Skeleton Understanding via Differentiable Rendering and MLLMs
Mar 18, 2026Multimodal large language models (MLLMs) exhibit strong visual-language reasoning, yet remain confined to their native modalities and cannot directly process structured, non-visual data such as human skeletons. Existing methods either compress skeleton dynamics into lossy feature vectors for text alignment, or quantize motion into discrete tokens that generalize poorly across heterogeneous skeleton formats. We present SkeletonLLM, which achieves universal skeleton understanding by translating arbitrary skeleton sequences into the MLLM's native visual modality. At its core is DrAction, a differentiable, format-agnostic renderer that converts skeletal kinematics into compact image sequences. Because the pipeline is end-to-end differentiable, MLLM gradients can directly guide the rendering to produce task-informative visual tokens. To further enhance reasoning capabilities, we introduce a cooperative training strategy: Causal Reasoning Distillation transfers structured, step-by-step reasoning from a teacher model, while Discriminative Finetuning sharpens decision boundaries between confusable actions. SkeletonLLM demonstrates strong generalization on diverse tasks including recognition, captioning, reasoning, and cross-format transfer -- suggesting a viable path for applying MLLMs to non-native modalities. Code will be released upon acceptance.
Olbedo: An Albedo and Shading Aerial Dataset for Large-Scale Outdoor Environments
Feb 24, 2026Intrinsic image decomposition (IID) of outdoor scenes is crucial for relighting, editing, and understanding large-scale environments, but progress has been limited by the lack of real-world datasets with reliable albedo and shading supervision. We introduce Olbedo, a large-scale aerial dataset for outdoor albedo--shading decomposition in the wild. Olbedo contains 5,664 UAV images captured across four landscape types, multiple years, and diverse illumination conditions. Each view is accompanied by multi-view consistent albedo and shading maps, metric depth, surface normals, sun and sky shading components, camera poses, and, for recent flights, measured HDR sky domes. These annotations are derived from an inverse-rendering refinement pipeline over multi-view stereo reconstructions and calibrated sky illumination, together with per-pixel confidence masks. We demonstrate that Olbedo enables state-of-the-art diffusion-based IID models, originally trained on synthetic indoor data, to generalize to real outdoor imagery: fine-tuning on Olbedo significantly improves single-view outdoor albedo prediction on the MatrixCity benchmark. We further illustrate applications of Olbedo-trained models to multi-view consistent relighting of 3D assets, material editing, and scene change analysis for urban digital twins. We release the dataset, baseline models, and an evaluation protocol to support future research in outdoor intrinsic decomposition and illumination-aware aerial vision.
Scalable and General Whole-Body Control for Cross-Humanoid Locomotion
Feb 05, 2026Learning-based whole-body controllers have become a key driver for humanoid robots, yet most existing approaches require robot-specific training. In this paper, we study the problem of cross-embodiment humanoid control and show that a single policy can robustly generalize across a wide range of humanoid robot designs with one-time training. We introduce XHugWBC, a novel cross-embodiment training framework that enables generalist humanoid control through: (1) physics-consistent morphological randomization, (2) semantically aligned observation and action spaces across diverse humanoid robots, and (3) effective policy architectures modeling morphological and dynamical properties. XHugWBC is not tied to any specific robot. Instead, it internalizes a broad distribution of morphological and dynamical characteristics during training. By learning motion priors from diverse randomized embodiments, the policy acquires a strong structural bias that supports zero-shot transfer to previously unseen robots. Experiments on twelve simulated humanoids and seven real-world robots demonstrate the strong generalization and robustness of the resulting universal controller.
Render-of-Thought: Rendering Textual Chain-of-Thought as Images for Visual Latent Reasoning
Jan 21, 2026Chain-of-Thought (CoT) prompting has achieved remarkable success in unlocking the reasoning capabilities of Large Language Models (LLMs). Although CoT prompting enhances reasoning, its verbosity imposes substantial computational overhead. Recent works often focus exclusively on outcome alignment and lack supervision on the intermediate reasoning process. These deficiencies obscure the analyzability of the latent reasoning chain. To address these challenges, we introduce Render-of-Thought (RoT), the first framework to reify the reasoning chain by rendering textual steps into images, making the latent rationale explicit and traceable. Specifically, we leverage the vision encoders of existing Vision Language Models (VLMs) as semantic anchors to align the vision embeddings with the textual space. This design ensures plug-and-play implementation without incurring additional pre-training overhead. Extensive experiments on mathematical and logical reasoning benchmarks demonstrate that our method achieves 3-4x token compression and substantial inference acceleration compared to explicit CoT. Furthermore, it maintains competitive performance against other methods, validating the feasibility of this paradigm. Our code is available at https://github.com/TencentBAC/RoT
In defense of the two-stage framework for open-set domain adaptive semantic segmentation
Jan 04, 2026Open-Set Domain Adaptation for Semantic Segmentation (OSDA-SS) presents a significant challenge, as it requires both domain adaptation for known classes and the distinction of unknowns. Existing methods attempt to address both tasks within a single unified stage. We question this design, as the annotation imbalance between known and unknown classes often leads to negative transfer of known classes and underfitting for unknowns. To overcome these issues, we propose SATS, a Separating-then-Adapting Training Strategy, which addresses OSDA-SS through two sequential steps: known/unknown separation and unknown-aware domain adaptation. By providing the model with more accurate and well-aligned unknown classes, our method ensures a balanced learning of discriminative features for both known and unknown classes, steering the model toward discovering truly unknown objects. Additionally, we present hard unknown exploration, an innovative data augmentation method that exposes the model to more challenging unknowns, strengthening its ability to capture more comprehensive understanding of target unknowns. We evaluate our method on public OSDA-SS benchmarks. Experimental results demonstrate that our method achieves a substantial advancement, with a +3.85% H-Score improvement for GTA5-to-Cityscapes and +18.64% for SYNTHIA-to-Cityscapes, outperforming previous state-of-the-art methods.
HCPO: Hierarchical Conductor-Based Policy Optimization in Multi-Agent Reinforcement Learning
Nov 15, 2025In cooperative Multi-Agent Reinforcement Learning (MARL), efficient exploration is crucial for optimizing the performance of joint policy. However, existing methods often update joint policies via independent agent exploration, without coordination among agents, which inherently constrains the expressive capacity and exploration of joint policies. To address this issue, we propose a conductor-based joint policy framework that directly enhances the expressive capacity of joint policies and coordinates exploration. In addition, we develop a Hierarchical Conductor-based Policy Optimization (HCPO) algorithm that instructs policy updates for the conductor and agents in a direction aligned with performance improvement. A rigorous theoretical guarantee further establishes the monotonicity of the joint policy optimization process. By deploying local conductors, HCPO retains centralized training benefits while eliminating inter-agent communication during execution. Finally, we evaluate HCPO on three challenging benchmarks: StarCraftII Multi-agent Challenge, Multi-agent MuJoCo, and Multi-agent Particle Environment. The results indicate that HCPO outperforms competitive MARL baselines regarding cooperative efficiency and stability.
Robust and Efficient Communication in Multi-Agent Reinforcement Learning
Nov 14, 2025Multi-agent reinforcement learning (MARL) has made significant strides in enabling coordinated behaviors among autonomous agents. However, most existing approaches assume that communication is instantaneous, reliable, and has unlimited bandwidth; these conditions are rarely met in real-world deployments. This survey systematically reviews recent advances in robust and efficient communication strategies for MARL under realistic constraints, including message perturbations, transmission delays, and limited bandwidth. Furthermore, because the challenges of low-latency reliability, bandwidth-intensive data sharing, and communication-privacy trade-offs are central to practical MARL systems, we focus on three applications involving cooperative autonomous driving, distributed simultaneous localization and mapping, and federated learning. Finally, we identify key open challenges and future research directions, advocating a unified approach that co-designs communication, learning, and robustness to bridge the gap between theoretical MARL models and practical implementations.
SPAN: Spatial-Projection Alignment for Monocular 3D Object Detection
Nov 10, 2025Existing monocular 3D detectors typically tame the pronounced nonlinear regression of 3D bounding box through decoupled prediction paradigm, which employs multiple branches to estimate geometric center, depth, dimensions, and rotation angle separately. Although this decoupling strategy simplifies the learning process, it inherently ignores the geometric collaborative constraints between different attributes, resulting in the lack of geometric consistency prior, thereby leading to suboptimal performance. To address this issue, we propose novel Spatial-Projection Alignment (SPAN) with two pivotal components: (i). Spatial Point Alignment enforces an explicit global spatial constraint between the predicted and ground-truth 3D bounding boxes, thereby rectifying spatial drift caused by decoupled attribute regression. (ii). 3D-2D Projection Alignment ensures that the projected 3D box is aligned tightly within its corresponding 2D detection bounding box on the image plane, mitigating projection misalignment overlooked in previous works. To ensure training stability, we further introduce a Hierarchical Task Learning strategy that progressively incorporates spatial-projection alignment as 3D attribute predictions refine, preventing early stage error propagation across attributes. Extensive experiments demonstrate that the proposed method can be easily integrated into any established monocular 3D detector and delivers significant performance improvements.
Temporal-Guided Visual Foundation Models for Event-Based Vision
Nov 09, 2025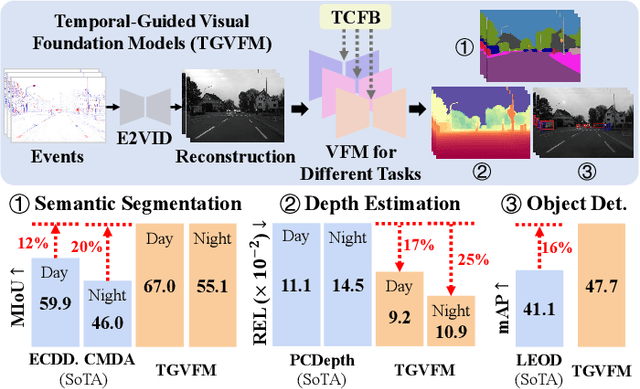
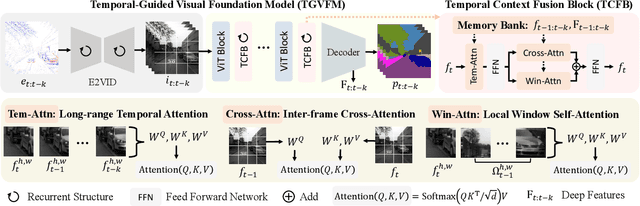


Event cameras offer unique advantages for vision tasks in challenging environments, yet processing asynchronous event streams remains an open challenge. While existing methods rely on specialized architectures or resource-intensive training, the potential of leveraging modern Visual Foundation Models (VFMs) pretrained on image data remains under-explored for event-based vision. To address this, we propose Temporal-Guided VFM (TGVFM), a novel framework that integrates VFMs with our temporal context fusion block seamlessly to bridge this gap. Our temporal block introduces three key components: (1) Long-Range Temporal Attention to model global temporal dependencies, (2) Dual Spatiotemporal Attention for multi-scale frame correlation, and (3) Deep Feature Guidance Mechanism to fuse semantic-temporal features. By retraining event-to-video models on real-world data and leveraging transformer-based VFMs, TGVFM preserves spatiotemporal dynamics while harnessing pretrained representations. Experiments demonstrate SoTA performance across semantic segmentation, depth estimation, and object detection, with improvements of 16%, 21%, and 16% over existing methods, respectively. Overall, this work unlocks the cross-modality potential of image-based VFMs for event-based vision with temporal reasoning. Code is available at https://github.com/XiaRho/TGVFM.