 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePointACT: Vision-Language-Action Models with Multi-Scale Point-Action Interaction
May 20, 2026Vision-Language-Action (VLA) models have shown strong potential for general-purpose robotic manipulation by leveraging large pretrained vision-language backbones. However, most existing VLAs rely primarily on 2D visual representations, which limit their ability to reason about fine-grained geometry and spatial grounding - capabilities that are essential for precise and robust manipulation in 3D environments. In this paper, we propose PointACT, a dual-system 3D-aware VLA policy that integrates hierarchical 3D point cloud representations directly into the action decoding process. PointACT employs a multi-scale point-action interaction mechanism with efficient bottleneck window self-attention, enabling evolving action tokens to densely attend to both local geometric detail and global scene structure. We evaluate PointACT on the LIBERO and RLBench benchmarks and systematically compare it against monolithic and dual-system VLA baselines, including variants augmented with point cloud inputs. PointACT achieves consistent improvements across both benchmarks, increasing success rates by 10% on the challenging RLBench-10Tasks suite over state-of-the-art pretrained VLAs, with even larger gains when the vision-language backbone is frozen and the action expert is trained from scratch. Extensive ablation studies demonstrate that tightly coupling hierarchical 3D geometry with pretrained 2D semantic representations is critical for robust and spatially grounded robot control. Our results also highlight the promise of pretrained 3D representations for 3D-aware VLA policies.
HO-Flow: Generalizable Hand-Object Interaction Generation with Latent Flow Matching
Apr 12, 2026Generating realistic 3D hand-object interactions (HOI) is a fundamental challenge in computer vision and robotics, requiring both temporal coherence and high-fidelity physical plausibility. Existing methods remain limited in their ability to learn expressive motion representations for generation and perform temporal reasoning. In this paper, we present HO-Flow, a framework for synthesizing realistic hand-object motion sequences from texts and canoncial 3D objects. HO-Flow first employs an interaction-aware variational autoencoder to encode sequences of hand and object motions into a unified latent manifold by incorporating hand and object kinematics, enabling the representation to capture rich interaction dynamics. It then leverages a masked flow matching model that combines auto-regressive temporal reasoning with continuous latent generation, improving temporal coherence. To further enhance generalization, HO-Flow predicts object motions relative to the initial frame, enabling effective pre-training on large-scale synthetic data. Experiments on the GRAB, OakInk, and DexYCB benchmarks demonstrate that HO-Flow achieves state-of-the-art performance in both physical plausibility and motion diversity for interaction motion synthesis.
FIRE-CIR: Fine-grained Reasoning for Composed Fashion Image Retrieval
Apr 10, 2026Composed image retrieval (CIR) aims to retrieve a target image that depicts a reference image modified by a textual description. While recent vision-language models (VLMs) achieve promising CIR performance by embedding images and text into a shared space for retrieval, they often fail to reason about what to preserve and what to change. This limitation hinders interpretability and yields suboptimal results, particularly in fine-grained domains like fashion. In this paper, we introduce FIRE-CIR, a model that brings compositional reasoning and interpretability to fashion CIR. Instead of relying solely on embedding similarity, FIRE-CIR performs question-driven visual reasoning: it automatically generates attribute-focused visual questions derived from the modification text, and verifies the corresponding visual evidence in both reference and candidate images. To train such a reasoning system, we automatically construct a large-scale fashion-specific visual question answering dataset, containing questions requiring either single- or dual-image analysis. During retrieval, our model leverages this explicit reasoning to re-rank candidate results, filtering out images inconsistent with the intended modifications. Experimental results on the Fashion IQ benchmark show that FIRE-CIR outperforms state-of-the-art methods in retrieval accuracy. It also provides interpretable, attribute-level insights into retrieval decisions.
MAGICIAN: Efficient Long-Term Planning with Imagined Gaussians for Active Mapping
Mar 23, 2026Active mapping aims to determine how an agent should move to efficiently reconstruct an unknown environment. Most existing approaches rely on greedy next-best-view prediction, resulting in inefficient exploration and incomplete scene reconstruction. To address this limitation, we introduce MAGICIAN, a novel long-term planning framework that maximizes accumulated surface coverage gain through Imagined Gaussians, a scene representation derived from a pre-trained occupancy network with strong structural priors. This representation enables efficient computation of coverage gain for any novel viewpoint via fast volumetric rendering, allowing its integration into a tree-search algorithm for long-horizon planning. We update Imagined Gaussians and refine the planned trajectory in a closed-loop manner. Our method achieves state-of-the-art performance across indoor and outdoor benchmarks with varying action spaces, demonstrating the critical advantage of long-term planning in active mapping.
Gondola: Grounded Vision Language Planning for Generalizable Robotic Manipulation
Jun 12, 2025



Robotic manipulation faces a significant challenge in generalizing across unseen objects, environments and tasks specified by diverse language instructions. To improve generalization capabilities, recent research has incorporated large language models (LLMs) for planning and action execution. While promising, these methods often fall short in generating grounded plans in visual environments. Although efforts have been made to perform visual instructional tuning on LLMs for robotic manipulation, existing methods are typically constrained by single-view image input and struggle with precise object grounding. In this work, we introduce Gondola, a novel grounded vision-language planning model based on LLMs for generalizable robotic manipulation. Gondola takes multi-view images and history plans to produce the next action plan with interleaved texts and segmentation masks of target objects and locations. To support the training of Gondola, we construct three types of datasets using the RLBench simulator, namely robot grounded planning, multi-view referring expression and pseudo long-horizon task datasets. Gondola outperforms the state-of-the-art LLM-based method across all four generalization levels of the GemBench dataset, including novel placements, rigid objects, articulated objects and long-horizon tasks.
ComposeAnything: Composite Object Priors for Text-to-Image Generation
May 30, 2025



Generating images from text involving complex and novel object arrangements remains a significant challenge for current text-to-image (T2I) models. Although prior layout-based methods improve object arrangements using spatial constraints with 2D layouts, they often struggle to capture 3D positioning and sacrifice quality and coherence. In this work, we introduce ComposeAnything, a novel framework for improving compositional image generation without retraining existing T2I models. Our approach first leverages the chain-of-thought reasoning abilities of LLMs to produce 2.5D semantic layouts from text, consisting of 2D object bounding boxes enriched with depth information and detailed captions. Based on this layout, we generate a spatial and depth aware coarse composite of objects that captures the intended composition, serving as a strong and interpretable prior that replaces stochastic noise initialization in diffusion-based T2I models. This prior guides the denoising process through object prior reinforcement and spatial-controlled denoising, enabling seamless generation of compositional objects and coherent backgrounds, while allowing refinement of inaccurate priors. ComposeAnything outperforms state-of-the-art methods on the T2I-CompBench and NSR-1K benchmarks for prompts with 2D/3D spatial arrangements, high object counts, and surreal compositions. Human evaluations further demonstrate that our model generates high-quality images with compositions that faithfully reflect the text.
HORT: Monocular Hand-held Objects Reconstruction with Transformers
Mar 27, 2025



Reconstructing hand-held objects in 3D from monocular images remains a significant challenge in computer vision. Most existing approaches rely on implicit 3D representations, which produce overly smooth reconstructions and are time-consuming to generate explicit 3D shapes. While more recent methods directly reconstruct point clouds with diffusion models, the multi-step denoising makes high-resolution reconstruction inefficient. To address these limitations, we propose a transformer-based model to efficiently reconstruct dense 3D point clouds of hand-held objects. Our method follows a coarse-to-fine strategy, first generating a sparse point cloud from the image and progressively refining it into a dense representation using pixel-aligned image features. To enhance reconstruction accuracy, we integrate image features with 3D hand geometry to jointly predict the object point cloud and its pose relative to the hand. Our model is trained end-to-end for optimal performance. Experimental results on both synthetic and real datasets demonstrate that our method achieves state-of-the-art accuracy with much faster inference speed, while generalizing well to in-the-wild images.
Online 3D Scene Reconstruction Using Neural Object Priors
Mar 24, 2025This paper addresses the problem of reconstructing a scene online at the level of objects given an RGB-D video sequence. While current object-aware neural implicit representations hold promise, they are limited in online reconstruction efficiency and shape completion. Our main contributions to alleviate the above limitations are twofold. First, we propose a feature grid interpolation mechanism to continuously update grid-based object-centric neural implicit representations as new object parts are revealed. Second, we construct an object library with previously mapped objects in advance and leverage the corresponding shape priors to initialize geometric object models in new videos, subsequently completing them with novel views as well as synthesized past views to avoid losing original object details. Extensive experiments on synthetic environments from the Replica dataset, real-world ScanNet sequences and videos captured in our laboratory demonstrate that our approach outperforms state-of-the-art neural implicit models for this task in terms of reconstruction accuracy and completeness.
NextBestPath: Efficient 3D Mapping of Unseen Environments
Feb 07, 2025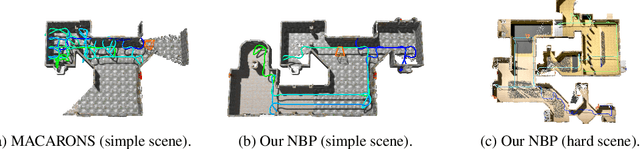


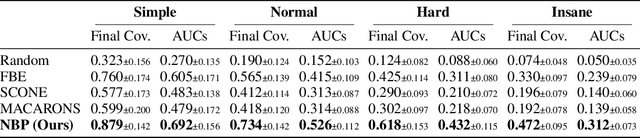
This work addresses the problem of active 3D mapping, where an agent must find an efficient trajectory to exhaustively reconstruct a new scene. Previous approaches mainly predict the next best view near the agent's location, which is prone to getting stuck in local areas. Additionally, existing indoor datasets are insufficient due to limited geometric complexity and inaccurate ground truth meshes. To overcome these limitations, we introduce a novel dataset AiMDoom with a map generator for the Doom video game, enabling to better benchmark active 3D mapping in diverse indoor environments. Moreover, we propose a new method we call next-best-path (NBP), which predicts long-term goals rather than focusing solely on short-sighted views. The model jointly predicts accumulated surface coverage gains for long-term goals and obstacle maps, allowing it to efficiently plan optimal paths with a unified model. By leveraging online data collection, data augmentation and curriculum learning, NBP significantly outperforms state-of-the-art methods on both the existing MP3D dataset and our AiMDoom dataset, achieving more efficient mapping in indoor environments of varying complexity.
Towards Generalizable Vision-Language Robotic Manipulation: A Benchmark and LLM-guided 3D Policy
Oct 02, 2024


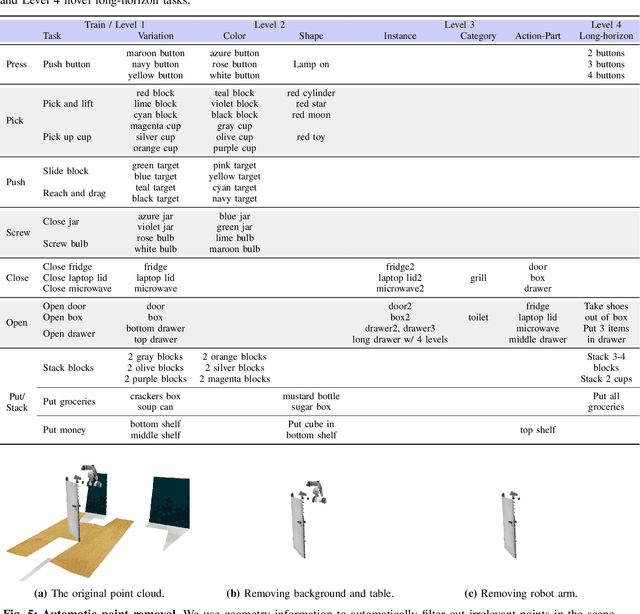
Generalizing language-conditioned robotic policies to new tasks remains a significant challenge, hampered by the lack of suitable simulation benchmarks. In this paper, we address this gap by introducing GemBench, a novel benchmark to assess generalization capabilities of vision-language robotic manipulation policies. GemBench incorporates seven general action primitives and four levels of generalization, spanning novel placements, rigid and articulated objects, and complex long-horizon tasks. We evaluate state-of-the-art approaches on GemBench and also introduce a new method. Our approach 3D-LOTUS leverages rich 3D information for action prediction conditioned on language. While 3D-LOTUS excels in both efficiency and performance on seen tasks, it struggles with novel tasks. To address this, we present 3D-LOTUS++, a framework that integrates 3D-LOTUS's motion planning capabilities with the task planning capabilities of LLMs and the object grounding accuracy of VLMs. 3D-LOTUS++ achieves state-of-the-art performance on novel tasks of GemBench, setting a new standard for generalization in robotic manipulation. The benchmark, codes and trained models are available at \url{https://www.di.ens.fr/willow/research/gembench/}.