 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiCam: On-the-fly Multi-Camera Pose Estimation Using Spatiotemporal Overlaps of Known Objects
Mar 24, 2026Multi-camera dynamic Augmented Reality (AR) applications require a camera pose estimation to leverage individual information from each camera in one common system. This can be achieved by combining contextual information, such as markers or objects, across multiple views. While commonly cameras are calibrated in an initial step or updated through the constant use of markers, another option is to leverage information already present in the scene, like known objects. Another downside of marker-based tracking is that markers have to be tracked inside the field-of-view (FoV) of the cameras. To overcome these limitations, we propose a constant dynamic camera pose estimation leveraging spatiotemporal FoV overlaps of known objects on the fly. To achieve that, we enhance the state-of-the-art object pose estimator to update our spatiotemporal scene graph, enabling a relation even among non-overlapping FoV cameras. To evaluate our approach, we introduce a multi-camera, multi-object pose estimation dataset with temporal FoV overlap, including static and dynamic cameras. Furthermore, in FoV overlapping scenarios, we outperform the state-of-the-art on the widely used YCB-V and T-LESS dataset in camera pose accuracy. Our performance on both previous and our proposed datasets validates the effectiveness of our marker-less approach for AR applications. The code and dataset are available on https://github.com/roth-hex-lab/IEEE-VR-2026-MultiCam.
Render-of-Thought: Rendering Textual Chain-of-Thought as Images for Visual Latent Reasoning
Jan 21, 2026Chain-of-Thought (CoT) prompting has achieved remarkable success in unlocking the reasoning capabilities of Large Language Models (LLMs). Although CoT prompting enhances reasoning, its verbosity imposes substantial computational overhead. Recent works often focus exclusively on outcome alignment and lack supervision on the intermediate reasoning process. These deficiencies obscure the analyzability of the latent reasoning chain. To address these challenges, we introduce Render-of-Thought (RoT), the first framework to reify the reasoning chain by rendering textual steps into images, making the latent rationale explicit and traceable. Specifically, we leverage the vision encoders of existing Vision Language Models (VLMs) as semantic anchors to align the vision embeddings with the textual space. This design ensures plug-and-play implementation without incurring additional pre-training overhead. Extensive experiments on mathematical and logical reasoning benchmarks demonstrate that our method achieves 3-4x token compression and substantial inference acceleration compared to explicit CoT. Furthermore, it maintains competitive performance against other methods, validating the feasibility of this paradigm. Our code is available at https://github.com/TencentBAC/RoT
ReSeek: A Self-Correcting Framework for Search Agents with Instructive Rewards
Oct 01, 2025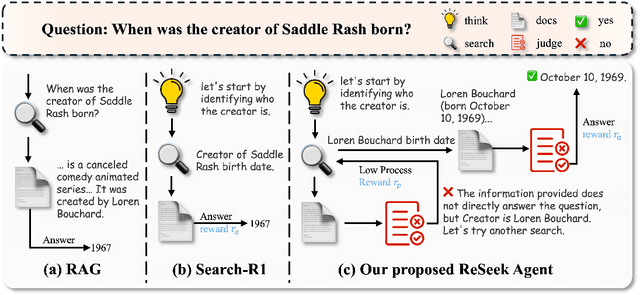

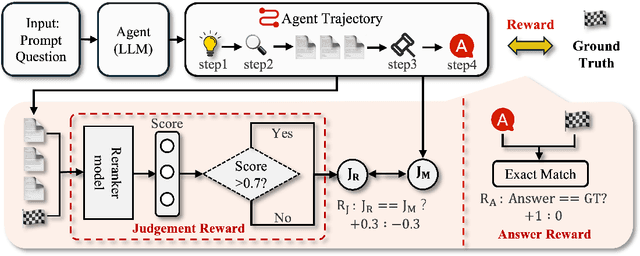

Search agents powered by Large Language Models (LLMs) have demonstrated significant potential in tackling knowledge-intensive tasks. Reinforcement learning (RL) has emerged as a powerful paradigm for training these agents to perform complex, multi-step reasoning. However, prior RL-based methods often rely on sparse or rule-based rewards, which can lead agents to commit to suboptimal or erroneous reasoning paths without the ability to recover. To address these limitations, we propose ReSeek, a novel self-correcting framework for training search agents. Our framework introduces a self-correction mechanism that empowers the agent to dynamically identify and recover from erroneous search paths during an episode. By invoking a special JUDGE action, the agent can judge the information and re-plan its search strategy. To guide this process, we design a dense, instructive process reward function, which decomposes into a correctness reward for retrieving factual information and a utility reward for finding information genuinely useful for the query. Furthermore, to mitigate the risk of data contamination in existing datasets, we introduce FictionalHot, a new and challenging benchmark with recently curated questions requiring complex reasoning. Being intuitively reasonable and practically simple, extensive experiments show that agents trained with ReSeek significantly outperform SOTA baselines in task success rate and path faithfulness.
Conan-Embedding-v2: Training an LLM from Scratch for Text Embeddings
Sep 16, 2025Large language models (LLMs) have recently demonstrated excellent performance in text embedding tasks. Previous work usually use LoRA to fine-tune existing LLMs, which are limited by the data and training gap between LLMs and embedding models. In this work, we introduce Conan-embedding-v2, a new 1.4B-parameter LLM trained from scratch and fine-tuned as a text embedder. First, we add news data and multilingual pairs for LLM pretraining to bridge the data gap. Based on this, we propose a cross-lingual retrieval dataset that enables the LLM to better integrate embeddings across different languages. Second, whereas LLMs use a causal mask with token-level loss, embedding models use a bidirectional mask with sentence-level loss. This training gap makes full fine-tuning less effective than LoRA. We introduce a soft-masking mechanism to gradually transition between these two types of masks, enabling the model to learn more comprehensive representations. Based on this, we propose a dynamic hard negative mining method that exposes the model to more difficult negative examples throughout the training process. Being intuitive and effective, with only approximately 1.4B parameters, Conan-embedding-v2 achieves SOTA performance on both the Massive Text Embedding Benchmark (MTEB) and Chinese MTEB (May 19, 2025).
TAlignDiff: Automatic Tooth Alignment assisted by Diffusion-based Transformation Learning
Aug 06, 2025Orthodontic treatment hinges on tooth alignment, which significantly affects occlusal function, facial aesthetics, and patients' quality of life. Current deep learning approaches predominantly concentrate on predicting transformation matrices through imposing point-to-point geometric constraints for tooth alignment. Nevertheless, these matrices are likely associated with the anatomical structure of the human oral cavity and possess particular distribution characteristics that the deterministic point-to-point geometric constraints in prior work fail to capture. To address this, we introduce a new automatic tooth alignment method named TAlignDiff, which is supported by diffusion-based transformation learning. TAlignDiff comprises two main components: a primary point cloud-based regression network (PRN) and a diffusion-based transformation matrix denoising module (DTMD). Geometry-constrained losses supervise PRN learning for point cloud-level alignment. DTMD, as an auxiliary module, learns the latent distribution of transformation matrices from clinical data. We integrate point cloud-based transformation regression and diffusion-based transformation modeling into a unified framework, allowing bidirectional feedback between geometric constraints and diffusion refinement. Extensive ablation and comparative experiments demonstrate the effectiveness and superiority of our method, highlighting its potential in orthodontic treatment.
Breaking Down Video LLM Benchmarks: Knowledge, Spatial Perception, or True Temporal Understanding?
May 20, 2025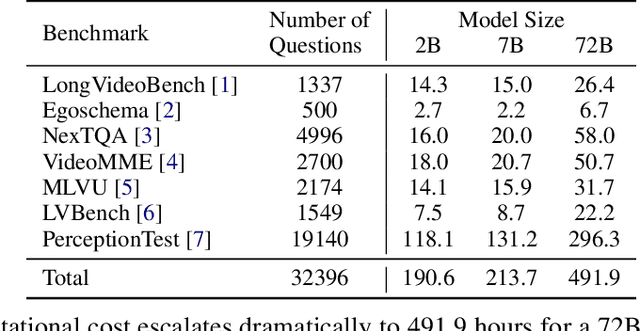

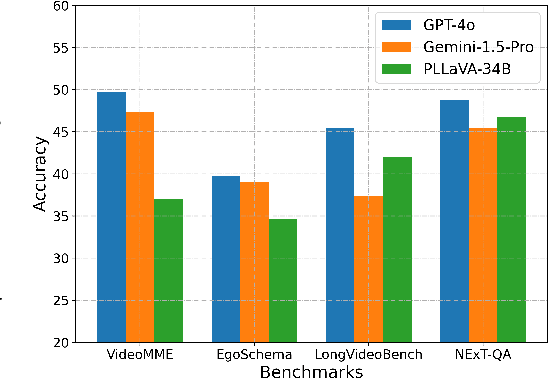
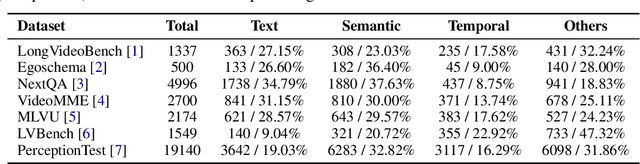
Existing video understanding benchmarks often conflate knowledge-based and purely image-based questions, rather than clearly isolating a model's temporal reasoning ability, which is the key aspect that distinguishes video understanding from other modalities. We identify two major limitations that obscure whether higher scores truly indicate stronger understanding of the dynamic content in videos: (1) strong language priors, where models can answer questions without watching the video; and (2) shuffling invariance, where models maintain similar performance on certain questions even when video frames are temporally shuffled. To alleviate these issues, we propose VBenchComp, an automated pipeline that categorizes questions into different domains: LLM-Answerable, Semantic, and Temporal. Specifically, LLM-Answerable questions can be answered without viewing the video; Semantic questions remain answerable even when the video frames are shuffled; and Temporal questions require understanding the correct temporal order of frames. The rest of the questions are labeled as Others. This can enable fine-grained evaluation of different capabilities of a video LLM. Our analysis reveals nuanced model weaknesses that are hidden by traditional overall scores, and we offer insights and recommendations for designing future benchmarks that more accurately assess video LLMs.
StreamBridge: Turning Your Offline Video Large Language Model into a Proactive Streaming Assistant
May 08, 2025We present StreamBridge, a simple yet effective framework that seamlessly transforms offline Video-LLMs into streaming-capable models. It addresses two fundamental challenges in adapting existing models into online scenarios: (1) limited capability for multi-turn real-time understanding, and (2) lack of proactive response mechanisms. Specifically, StreamBridge incorporates (1) a memory buffer combined with a round-decayed compression strategy, supporting long-context multi-turn interactions, and (2) a decoupled, lightweight activation model that can be effortlessly integrated into existing Video-LLMs, enabling continuous proactive responses. To further support StreamBridge, we construct Stream-IT, a large-scale dataset tailored for streaming video understanding, featuring interleaved video-text sequences and diverse instruction formats. Extensive experiments show that StreamBridge significantly improves the streaming understanding capabilities of offline Video-LLMs across various tasks, outperforming even proprietary models such as GPT-4o and Gemini 1.5 Pro. Simultaneously, it achieves competitive or superior performance on standard video understanding benchmarks.
ProDisc-VAD: An Efficient System for Weakly-Supervised Anomaly Detection in Video Surveillance Applications
May 04, 2025Weakly-supervised video anomaly detection (WS-VAD) using Multiple Instance Learning (MIL) suffers from label ambiguity, hindering discriminative feature learning. We propose ProDisc-VAD, an efficient framework tackling this via two synergistic components. The Prototype Interaction Layer (PIL) provides controlled normality modeling using a small set of learnable prototypes, establishing a robust baseline without being overwhelmed by dominant normal data. The Pseudo-Instance Discriminative Enhancement (PIDE) loss boosts separability by applying targeted contrastive learning exclusively to the most reliable extreme-scoring instances (highest/lowest scores). ProDisc-VAD achieves strong AUCs (97.98% ShanghaiTech, 87.12% UCF-Crime) using only 0.4M parameters, over 800x fewer than recent ViT-based methods like VadCLIP, demonstrating exceptional efficiency alongside state-of-the-art performance. Code is available at https://github.com/modadundun/ProDisc-VAD.
SlowFast-LLaVA-1.5: A Family of Token-Efficient Video Large Language Models for Long-Form Video Understanding
Mar 27, 2025We introduce SlowFast-LLaVA-1.5 (abbreviated as SF-LLaVA-1.5), a family of video large language models (LLMs) offering a token-efficient solution for long-form video understanding. We incorporate the two-stream SlowFast mechanism into a streamlined training pipeline, and perform joint video-image training on a carefully curated data mixture of only publicly available datasets. Our primary focus is on highly efficient model scales (1B and 3B), demonstrating that even relatively small Video LLMs can achieve state-of-the-art performance on video understanding, meeting the demand for mobile-friendly models. Experimental results demonstrate that SF-LLaVA-1.5 achieves superior performance on a wide range of video and image tasks, with robust results at all model sizes (ranging from 1B to 7B). Notably, SF-LLaVA-1.5 achieves state-of-the-art results in long-form video understanding (e.g., LongVideoBench and MLVU) and excels at small scales across various video benchmarks.
Synth4Seg -- Learning Defect Data Synthesis for Defect Segmentation using Bi-level Optimization
Oct 24, 2024Defect segmentation is crucial for quality control in advanced manufacturing, yet data scarcity poses challenges for state-of-the-art supervised deep learning. Synthetic defect data generation is a popular approach for mitigating data challenges. However, many current methods simply generate defects following a fixed set of rules, which may not directly relate to downstream task performance. This can lead to suboptimal performance and may even hinder the downstream task. To solve this problem, we leverage a novel bi-level optimization-based synthetic defect data generation framework. We use an online synthetic defect generation module grounded in the commonly-used Cut\&Paste framework, and adopt an efficient gradient-based optimization algorithm to solve the bi-level optimization problem. We achieve simultaneous training of the defect segmentation network, and learn various parameters of the data synthesis module by maximizing the validation performance of the trained defect segmentation network. Our experimental results on benchmark datasets under limited data settings show that the proposed bi-level optimization method can be used for learning the most effective locations for pasting synthetic defects thereby improving the segmentation performance by up to 18.3\% when compared to pasting defects at random locations. We also demonstrate up to 2.6\% performance gain by learning the importance weights for different augmentation-specific defect data sources when compared to giving equal importance to all the data sources.