 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Foveated Path Tracing with Peripheral Gaussians for Immersive Anatomy
Jan 29, 2026Volumetric medical imaging offers great potential for understanding complex pathologies. Yet, traditional 2D slices provide little support for interpreting spatial relationships, forcing users to mentally reconstruct anatomy into three dimensions. Direct volumetric path tracing and VR rendering can improve perception but are computationally expensive, while precomputed representations, like Gaussian Splatting, require planning ahead. Both approaches limit interactive use. We propose a hybrid rendering approach for high-quality, interactive, and immersive anatomical visualization. Our method combines streamed foveated path tracing with a lightweight Gaussian Splatting approximation of the periphery. The peripheral model generation is optimized with volume data and continuously refined using foveal renderings, enabling interactive updates. Depth-guided reprojection further improves robustness to latency and allows users to balance fidelity with refresh rate. We compare our method against direct path tracing and Gaussian Splatting. Our results highlight how their combination can preserve strengths in visual quality while re-generating the peripheral model in under a second, eliminating extensive preprocessing and approximations. This opens new options for interactive medical visualization.
CoRe-GS: Coarse-to-Refined Gaussian Splatting with Semantic Object Focus
Sep 05, 2025Mobile reconstruction for autonomous aerial robotics holds strong potential for critical applications such as tele-guidance and disaster response. These tasks demand both accurate 3D reconstruction and fast scene processing. Instead of reconstructing the entire scene in detail, it is often more efficient to focus on specific objects, i.e., points of interest (PoIs). Mobile robots equipped with advanced sensing can usually detect these early during data acquisition or preliminary analysis, reducing the need for full-scene optimization. Gaussian Splatting (GS) has recently shown promise in delivering high-quality novel view synthesis and 3D representation by an incremental learning process. Extending GS with scene editing, semantics adds useful per-splat features to isolate objects effectively. Semantic 3D Gaussian editing can already be achieved before the full training cycle is completed, reducing the overall training time. Moreover, the semantically relevant area, the PoI, is usually already known during capturing. To balance high-quality reconstruction with reduced training time, we propose CoRe-GS. We first generate a coarse segmentation-ready scene with semantic GS and then refine it for the semantic object using our novel color-based effective filtering for effective object isolation. This is speeding up the training process to be about a quarter less than a full training cycle for semantic GS. We evaluate our approach on two datasets, SCRREAM (real-world, outdoor) and NeRDS 360 (synthetic, indoor), showing reduced runtime and higher novel-view-synthesis quality.
Locality-Sensitive Hashing for Efficient Hard Negative Sampling in Contrastive Learning
May 23, 2025Contrastive learning is a representational learning paradigm in which a neural network maps data elements to feature vectors. It improves the feature space by forming lots with an anchor and examples that are either positive or negative based on class similarity. Hard negative examples, which are close to the anchor in the feature space but from a different class, improve learning performance. Finding such examples of high quality efficiently in large, high-dimensional datasets is computationally challenging. In this paper, we propose a GPU-friendly Locality-Sensitive Hashing (LSH) scheme that quantizes real-valued feature vectors into binary representations for approximate nearest neighbor search. We investigate its theoretical properties and evaluate it on several datasets from textual and visual domain. Our approach achieves comparable or better performance while requiring significantly less computation than existing hard negative mining strategies.
Multi-Layer Gaussian Splatting for Immersive Anatomy Visualization
Oct 22, 2024



In medical image visualization, path tracing of volumetric medical data like CT scans produces lifelike three-dimensional visualizations. Immersive VR displays can further enhance the understanding of complex anatomies. Going beyond the diagnostic quality of traditional 2D slices, they enable interactive 3D evaluation of anatomies, supporting medical education and planning. Rendering high-quality visualizations in real-time, however, is computationally intensive and impractical for compute-constrained devices like mobile headsets. We propose a novel approach utilizing GS to create an efficient but static intermediate representation of CT scans. We introduce a layered GS representation, incrementally including different anatomical structures while minimizing overlap and extending the GS training to remove inactive Gaussians. We further compress the created model with clustering across layers. Our approach achieves interactive frame rates while preserving anatomical structures, with quality adjustable to the target hardware. Compared to standard GS, our representation retains some of the explorative qualities initially enabled by immersive path tracing. Selective activation and clipping of layers are possible at rendering time, adding a degree of interactivity to otherwise static GS models. This could enable scenarios where high computational demands would otherwise prohibit using path-traced medical volumes.
Semantics-Controlled Gaussian Splatting for Outdoor Scene Reconstruction and Rendering in Virtual Reality
Sep 24, 2024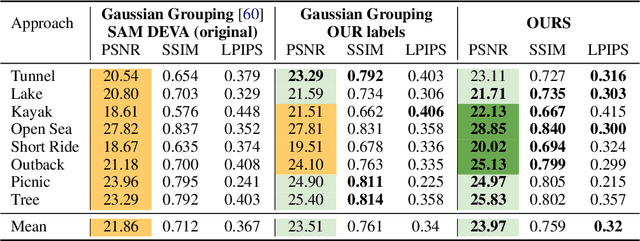
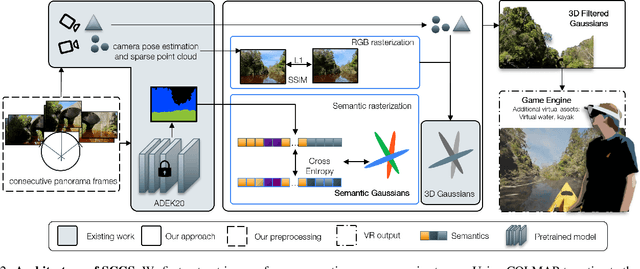
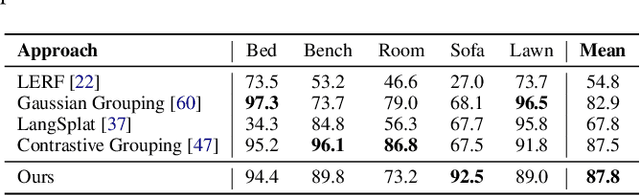

Advancements in 3D rendering like Gaussian Splatting (GS) allow novel view synthesis and real-time rendering in virtual reality (VR). However, GS-created 3D environments are often difficult to edit. For scene enhancement or to incorporate 3D assets, segmenting Gaussians by class is essential. Existing segmentation approaches are typically limited to certain types of scenes, e.g., ''circular'' scenes, to determine clear object boundaries. However, this method is ineffective when removing large objects in non-''circling'' scenes such as large outdoor scenes. We propose Semantics-Controlled GS (SCGS), a segmentation-driven GS approach, enabling the separation of large scene parts in uncontrolled, natural environments. SCGS allows scene editing and the extraction of scene parts for VR. Additionally, we introduce a challenging outdoor dataset, overcoming the ''circling'' setup. We outperform the state-of-the-art in visual quality on our dataset and in segmentation quality on the 3D-OVS dataset. We conducted an exploratory user study, comparing a 360-video, plain GS, and SCGS in VR with a fixed viewpoint. In our subsequent main study, users were allowed to move freely, evaluating plain GS and SCGS. Our main study results show that participants clearly prefer SCGS over plain GS. We overall present an innovative approach that surpasses the state-of-the-art both technically and in user experience.
AMOR: Ambiguous Authorship Order
Apr 01, 2024As we all know, writing scientific papers together with our beloved colleagues is a truly remarkable experience (partially): endless discussions about the same useless paragraph over and over again, followed by long days and long nights -- both at the same time. What a wonderful ride it is! What a beautiful life we have. But wait, there's one tiny little problem that utterly shatters the peace, turning even renowned scientists into bloodthirsty monsters: author order. The reason is that, contrary to widespread opinion, it's not the font size that matters, but the way things are ordered. Of course, this is a fairly well-known fact among scientists all across the planet (and beyond) and explains clearly why we regularly have to read about yet another escalated paper submission in local police reports. In this paper, we take an important step backwards to tackle this issue by solving the so-called author ordering problem (AOP) once and for all. Specifically, we propose AMOR, a system that replaces silly constructs like co-first or co-middle authorship with a simple yet easy probabilistic approach based on random shuffling of the author list at viewing time. In addition to AOP, we also solve the ambiguous author ordering citation problem} (AAOCP) on the fly. Stop author violence, be human.
ASDF: Assembly State Detection Utilizing Late Fusion by Integrating 6D Pose Estimation
Mar 25, 2024



In medical and industrial domains, providing guidance for assembly processes is critical to ensure efficiency and safety. Errors in assembly can lead to significant consequences such as extended surgery times, and prolonged manufacturing or maintenance times in industry. Assembly scenarios can benefit from in-situ AR visualization to provide guidance, reduce assembly times and minimize errors. To enable in-situ visualization 6D pose estimation can be leveraged. Existing 6D pose estimation techniques primarily focus on individual objects and static captures. However, assembly scenarios have various dynamics including occlusion during assembly and dynamics in the assembly objects appearance. Existing work, combining object detection/6D pose estimation and assembly state detection focuses either on pure deep learning-based approaches, or limit the assembly state detection to building blocks. To address the challenges of 6D pose estimation in combination with assembly state detection, our approach ASDF builds upon the strengths of YOLOv8, a real-time capable object detection framework. We extend this framework, refine the object pose and fuse pose knowledge with network-detected pose information. Utilizing our late fusion in our Pose2State module results in refined 6D pose estimation and assembly state detection. By combining both pose and state information, our Pose2State module predicts the final assembly state with precision. Our evaluation on our ASDF dataset shows that our Pose2State module leads to an improved assembly state detection and that the improvement of the assembly state further leads to a more robust 6D pose estimation. Moreover, on the GBOT dataset, we outperform the pure deep learning-based network, and even outperform the hybrid and pure tracking-based approaches.
GBOT: Graph-Based 3D Object Tracking for Augmented Reality-Assisted Assembly Guidance
Feb 12, 2024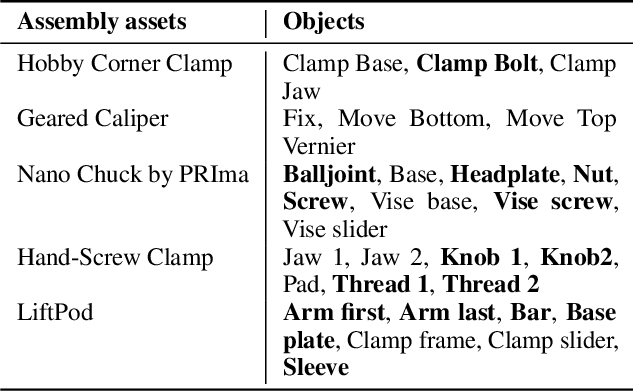
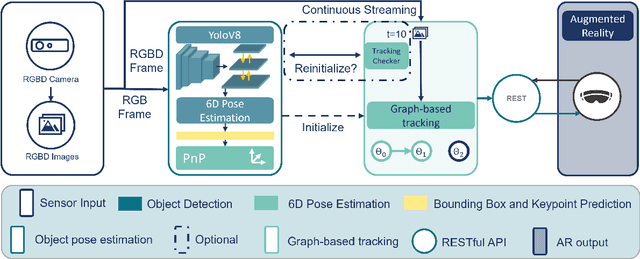
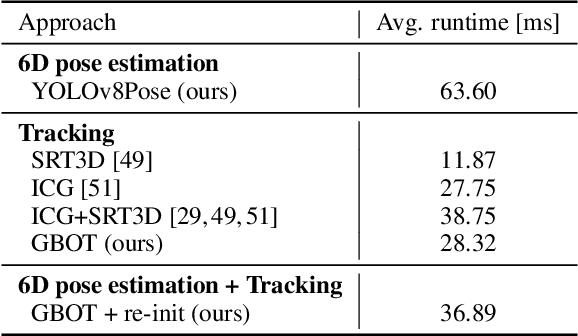
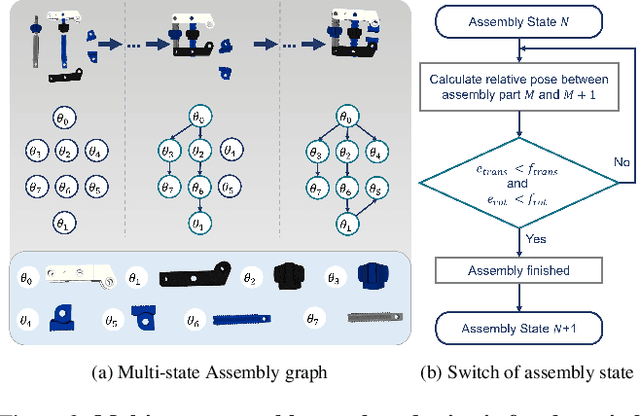
Guidance for assemblable parts is a promising field for augmented reality. Augmented reality assembly guidance requires 6D object poses of target objects in real time. Especially in time-critical medical or industrial settings, continuous and markerless tracking of individual parts is essential to visualize instructions superimposed on or next to the target object parts. In this regard, occlusions by the user's hand or other objects and the complexity of different assembly states complicate robust and real-time markerless multi-object tracking. To address this problem, we present Graph-based Object Tracking (GBOT), a novel graph-based single-view RGB-D tracking approach. The real-time markerless multi-object tracking is initialized via 6D pose estimation and updates the graph-based assembly poses. The tracking through various assembly states is achieved by our novel multi-state assembly graph. We update the multi-state assembly graph by utilizing the relative poses of the individual assembly parts. Linking the individual objects in this graph enables more robust object tracking during the assembly process. For evaluation, we introduce a synthetic dataset of publicly available and 3D printable assembly assets as a benchmark for future work. Quantitative experiments in synthetic data and further qualitative study in real test data show that GBOT can outperform existing work towards enabling context-aware augmented reality assembly guidance. Dataset and code will be made publically available.
DynaMoN: Motion-Aware Fast And Robust Camera Localization for Dynamic NeRF
Sep 16, 2023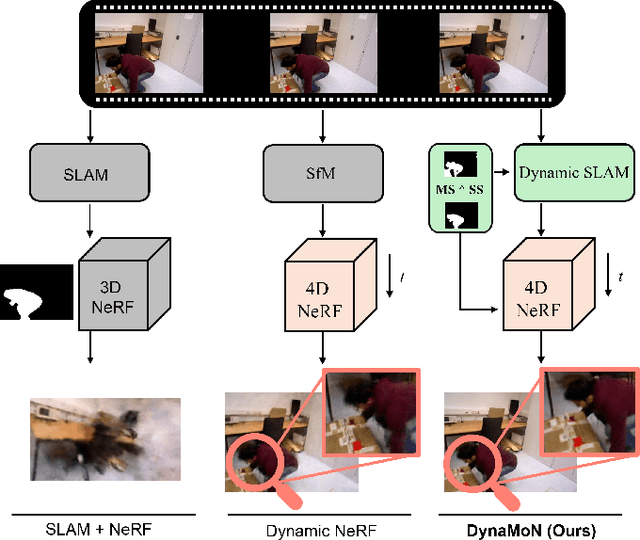

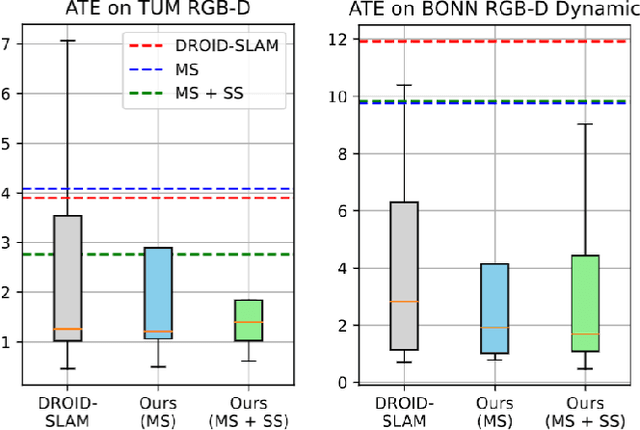

Dynamic reconstruction with neural radiance fields (NeRF) requires accurate camera poses. These are often hard to retrieve with existing structure-from-motion (SfM) pipelines as both camera and scene content can change. We propose DynaMoN that leverages simultaneous localization and mapping (SLAM) jointly with motion masking to handle dynamic scene content. Our robust SLAM-based tracking module significantly accelerates the training process of the dynamic NeRF while improving the quality of synthesized views at the same time. Extensive experimental validation on TUM RGB-D, BONN RGB-D Dynamic and the DyCheck's iPhone dataset, three real-world datasets, shows the advantages of DynaMoN both for camera pose estimation and novel view synthesis.
NeRFtrinsic Four: An End-To-End Trainable NeRF Jointly Optimizing Diverse Intrinsic and Extrinsic Camera Parameters
Mar 17, 2023Novel view synthesis using neural radiance fields (NeRF) is the state-of-the-art technique for generating high-quality images from novel viewpoints. Existing methods require a priori knowledge about extrinsic and intrinsic camera parameters. This limits their applicability to synthetic scenes, or real-world scenarios with the necessity of a preprocessing step. Current research on the joint optimization of camera parameters and NeRF focuses on refining noisy extrinsic camera parameters and often relies on the preprocessing of intrinsic camera parameters. Further approaches are limited to cover only one single camera intrinsic. To address these limitations, we propose a novel end-to-end trainable approach called NeRFtrinsic Four. We utilize Gaussian Fourier features to estimate extrinsic camera parameters and dynamically predict varying intrinsic camera parameters through the supervision of the projection error. Our approach outperforms existing joint optimization methods on LLFF and BLEFF. In addition to these existing datasets, we introduce a new dataset called iFF with varying intrinsic camera parameters. NeRFtrinsic Four is a step forward in joint optimization NeRF-based view synthesis and enables more realistic and flexible rendering in real-world scenarios with varying camera parameters.