 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgexVerify: Efficient Answer Verifier for Reasoning Model Evaluations
Apr 14, 2025With the release of the o1 model by OpenAI, reasoning models adopting slow thinking strategies have gradually emerged. As the responses generated by such models often include complex reasoning, intermediate steps, and self-reflection, existing evaluation methods are often inadequate. They struggle to determine whether the LLM output is truly equivalent to the reference answer, and also have difficulty identifying and extracting the final answer from long, complex responses. To address this issue, we propose xVerify, an efficient answer verifier for reasoning model evaluations. xVerify demonstrates strong capability in equivalence judgment, enabling it to effectively determine whether the answers produced by reasoning models are equivalent to reference answers across various types of objective questions. To train and evaluate xVerify, we construct the VAR dataset by collecting question-answer pairs generated by multiple LLMs across various datasets, leveraging multiple reasoning models and challenging evaluation sets designed specifically for reasoning model assessment. A multi-round annotation process is employed to ensure label accuracy. Based on the VAR dataset, we train multiple xVerify models of different scales. In evaluation experiments conducted on both the test set and generalization set, all xVerify models achieve overall F1 scores and accuracy exceeding 95\%. Notably, the smallest variant, xVerify-0.5B-I, outperforms all evaluation methods except GPT-4o, while xVerify-3B-Ib surpasses GPT-4o in overall performance. These results validate the effectiveness and generalizability of xVerify.
Controlling Large Language Model with Latent Actions
Mar 27, 2025Adapting Large Language Models (LLMs) to downstream tasks using Reinforcement Learning (RL) has proven to be an effective approach. However, LLMs do not inherently define the structure of an agent for RL training, particularly in terms of defining the action space. This paper studies learning a compact latent action space to enhance the controllability and exploration of RL for LLMs. We propose Controlling Large Language Models with Latent Actions (CoLA), a framework that integrates a latent action space into pre-trained LLMs. We apply CoLA to the Llama-3.1-8B model. Our experiments demonstrate that, compared to RL with token-level actions, CoLA's latent action enables greater semantic diversity in text generation. For enhancing downstream tasks, we show that CoLA with RL achieves a score of 42.4 on the math500 benchmark, surpassing the baseline score of 38.2, and reaches 68.2 when augmented with a Monte Carlo Tree Search variant. Furthermore, CoLA with RL consistently improves performance on agent-based tasks without degrading the pre-trained LLM's capabilities, unlike the baseline. Finally, CoLA reduces computation time by half in tasks involving enhanced thinking prompts for LLMs by RL. These results highlight CoLA's potential to advance RL-based adaptation of LLMs for downstream applications.
WHALE: Towards Generalizable and Scalable World Models for Embodied Decision-making
Nov 08, 2024



World models play a crucial role in decision-making within embodied environments, enabling cost-free explorations that would otherwise be expensive in the real world. To facilitate effective decision-making, world models must be equipped with strong generalizability to support faithful imagination in out-of-distribution (OOD) regions and provide reliable uncertainty estimation to assess the credibility of the simulated experiences, both of which present significant challenges for prior scalable approaches. This paper introduces WHALE, a framework for learning generalizable world models, consisting of two key techniques: behavior-conditioning and retracing-rollout. Behavior-conditioning addresses the policy distribution shift, one of the primary sources of the world model generalization error, while retracing-rollout enables efficient uncertainty estimation without the necessity of model ensembles. These techniques are universal and can be combined with any neural network architecture for world model learning. Incorporating these two techniques, we present Whale-ST, a scalable spatial-temporal transformer-based world model with enhanced generalizability. We demonstrate the superiority of Whale-ST in simulation tasks by evaluating both value estimation accuracy and video generation fidelity. Additionally, we examine the effectiveness of our uncertainty estimation technique, which enhances model-based policy optimization in fully offline scenarios. Furthermore, we propose Whale-X, a 414M parameter world model trained on 970K trajectories from Open X-Embodiment datasets. We show that Whale-X exhibits promising scalability and strong generalizability in real-world manipulation scenarios using minimal demonstrations.
MIPI 2024 Challenge on Few-shot RAW Image Denoising: Methods and Results
Jun 11, 2024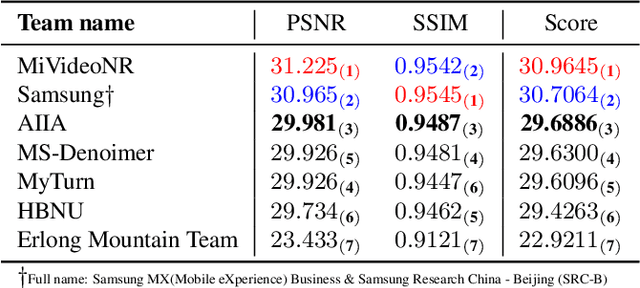
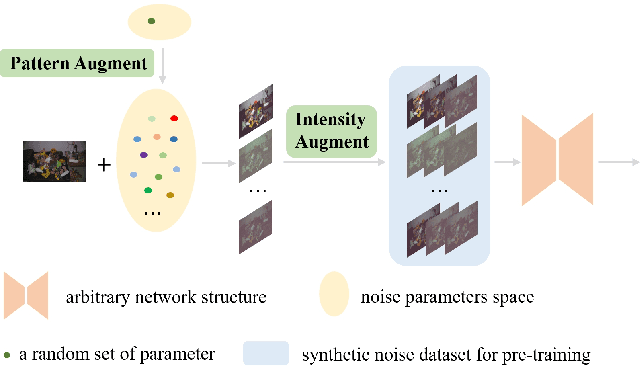

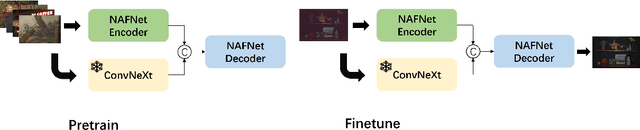
The increasing demand for computational photography and imaging on mobile platforms has led to the widespread development and integration of advanced image sensors with novel algorithms in camera systems. However, the scarcity of high-quality data for research and the rare opportunity for in-depth exchange of views from industry and academia constrain the development of mobile intelligent photography and imaging (MIPI). Building on the achievements of the previous MIPI Workshops held at ECCV 2022 and CVPR 2023, we introduce our third MIPI challenge including three tracks focusing on novel image sensors and imaging algorithms. In this paper, we summarize and review the Few-shot RAW Image Denoising track on MIPI 2024. In total, 165 participants were successfully registered, and 7 teams submitted results in the final testing phase. The developed solutions in this challenge achieved state-of-the-art erformance on Few-shot RAW Image Denoising. More details of this challenge and the link to the dataset can be found at https://mipichallenge.org/MIPI2024.
BWArea Model: Learning World Model, Inverse Dynamics, and Policy for Controllable Language Generation
May 27, 2024



Large language models (LLMs) have catalyzed a paradigm shift in natural language processing, yet their limited controllability poses a significant challenge for downstream applications. We aim to address this by drawing inspiration from the neural mechanisms of the human brain, specifically Broca's and Wernicke's areas, which are crucial for language generation and comprehension, respectively. In particular, Broca's area receives cognitive decision signals from Wernicke's area, treating the language generation as an intricate decision-making process, which differs from the fully auto-regressive language generation of existing LLMs. In a similar vein, our proposed system, the BWArea model, conceptualizes language generation as a decision-making task. This model has three components: a language world model, an inverse dynamics model, and a cognitive policy. Like Wernicke's area, the inverse dynamics model is designed to deduce the underlying cognitive intentions, or latent actions, behind each token. The BWArea model is amenable to both pre-training and fine-tuning like existing LLMs. With 30B clean pre-training tokens, we have trained a BWArea model, which achieves competitive performance with LLMs of equal size (1B parameters). Unlike fully auto-regressive LLMs, its pre-training performance does not degenerate if dirty data unintentionally appears. This shows the advantage of a decomposed structure of BWArea model in reducing efforts in laborious data selection and labeling. Finally, we reveal that the BWArea model offers enhanced controllability via fine-tuning the cognitive policy with downstream reward metrics, thereby facilitating alignment with greater simplicity. On 9 out of 10 tasks from two suites, TextWorld and BigBench Hard, our method shows superior performance to auto-regressive LLMs.
Empowering Language Models with Active Inquiry for Deeper Understanding
Feb 06, 2024The rise of large language models (LLMs) has revolutionized the way that we interact with artificial intelligence systems through natural language. However, LLMs often misinterpret user queries because of their uncertain intention, leading to less helpful responses. In natural human interactions, clarification is sought through targeted questioning to uncover obscure information. Thus, in this paper, we introduce LaMAI (Language Model with Active Inquiry), designed to endow LLMs with this same level of interactive engagement. LaMAI leverages active learning techniques to raise the most informative questions, fostering a dynamic bidirectional dialogue. This approach not only narrows the contextual gap but also refines the output of the LLMs, aligning it more closely with user expectations. Our empirical studies, across a variety of complex datasets where LLMs have limited conversational context, demonstrate the effectiveness of LaMAI. The method improves answer accuracy from 31.9% to 50.9%, outperforming other leading question-answering frameworks. Moreover, in scenarios involving human participants, LaMAI consistently generates responses that are superior or comparable to baseline methods in more than 82% of the cases. The applicability of LaMAI is further evidenced by its successful integration with various LLMs, highlighting its potential for the future of interactive language models.
GS-Pose: Category-Level Object Pose Estimation via Geometric and Semantic Correspondence
Nov 23, 2023



Category-level pose estimation is a challenging task with many potential applications in computer vision and robotics. Recently, deep-learning-based approaches have made great progress, but are typically hindered by the need for large datasets of either pose-labelled real images or carefully tuned photorealistic simulators. This can be avoided by using only geometry inputs such as depth images to reduce the domain-gap but these approaches suffer from a lack of semantic information, which can be vital in the pose estimation problem. To resolve this conflict, we propose to utilize both geometric and semantic features obtained from a pre-trained foundation model.Our approach projects 2D features from this foundation model into 3D for a single object model per category, and then performs matching against this for new single view observations of unseen object instances with a trained matching network. This requires significantly less data to train than prior methods since the semantic features are robust to object texture and appearance. We demonstrate this with a rich evaluation, showing improved performance over prior methods with a fraction of the data required.
CCD-3DR: Consistent Conditioning in Diffusion for Single-Image 3D Reconstruction
Aug 15, 2023



In this paper, we present a novel shape reconstruction method leveraging diffusion model to generate 3D sparse point cloud for the object captured in a single RGB image. Recent methods typically leverage global embedding or local projection-based features as the condition to guide the diffusion model. However, such strategies fail to consistently align the denoised point cloud with the given image, leading to unstable conditioning and inferior performance. In this paper, we present CCD-3DR, which exploits a novel centered diffusion probabilistic model for consistent local feature conditioning. We constrain the noise and sampled point cloud from the diffusion model into a subspace where the point cloud center remains unchanged during the forward diffusion process and reverse process. The stable point cloud center further serves as an anchor to align each point with its corresponding local projection-based features. Extensive experiments on synthetic benchmark ShapeNet-R2N2 demonstrate that CCD-3DR outperforms all competitors by a large margin, with over 40% improvement. We also provide results on real-world dataset Pix3D to thoroughly demonstrate the potential of CCD-3DR in real-world applications. Codes will be released soon
Language Model Self-improvement by Reinforcement Learning Contemplation
May 23, 2023



Large Language Models (LLMs) have exhibited remarkable performance across various natural language processing (NLP) tasks. However, fine-tuning these models often necessitates substantial supervision, which can be expensive and time-consuming to obtain. This paper introduces a novel unsupervised method called LanguageModel Self-Improvement by Reinforcement Learning Contemplation (SIRLC) that improves LLMs without reliance on external labels. Our approach is grounded in the observation that it is simpler for language models to assess text quality than to generate text. Building on this insight, SIRLC assigns LLMs dual roles as both student and teacher. As a student, the LLM generates answers to unlabeled questions, while as a teacher, it evaluates the generated text and assigns scores accordingly. The model parameters are updated using reinforcement learning to maximize the evaluation score. We demonstrate that SIRLC can be applied to various NLP tasks, such as reasoning problems, text generation, and machine translation. Our experiments show that SIRLC effectively improves LLM performance without external supervision, resulting in a 5.6% increase in answering accuracy for reasoning tasks and a rise in BERTScore from 0.82 to 0.86 for translation tasks. Furthermore, SIRLC can be applied to models of different sizes, showcasing its broad applicability.
HouseCat6D -- A Large-Scale Multi-Modal Category Level 6D Object Pose Dataset with Household Objects in Realistic Scenarios
Dec 21, 2022Estimating the 6D pose of objects is one of the major fields in 3D computer vision. Since the promising outcomes from instance-level pose estimation, the research trends are heading towards category-level pose estimation for more practical application scenarios. However, unlike well-established instance-level pose datasets, available category-level datasets lack annotation quality and provided pose quantity. We propose the new category level 6D pose dataset HouseCat6D featuring 1) Multi-modality of Polarimetric RGB+P and Depth, 2) Highly diverse 194 objects of 10 household object categories including 2 photometrically challenging categories, 3) High-quality pose annotation with an error range of only 1.35 mm to 1.74 mm, 4) 41 large scale scenes with extensive viewpoint coverage, 5) Checkerboard-free environment throughout the entire scene. We also provide benchmark results of state-of-the-art category-level pose estimation networks.