 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeedup Patch: Learning a Plug-and-Play Policy to Accelerate Embodied Manipulation
Mar 21, 2026While current embodied policies exhibit remarkable manipulation skills, their execution remains unsatisfactorily slow as they inherit the tardy pacing of human demonstrations. Existing acceleration methods typically require policy retraining or costly online interactions, limiting their scalability for large-scale foundation models. In this paper, we propose Speedup Patch (SuP), a lightweight, policy-agnostic framework that enables plug-and-play acceleration using solely offline data. SuP introduces an external scheduler that adaptively downsamples action chunks provided by embodied policies to eliminate redundancies. Specifically, we formalize the optimization of our scheduler as a Constrained Markov Decision Process (CMDP) aimed at maximizing efficiency without compromising task performance. Since direct success evaluation is infeasible in offline settings, SuP introduces World Model based state deviation as a surrogate metric to enforce safety constraints. By leveraging a learned world model as a virtual evaluator to predict counterfactual trajectories, the scheduler can be optimized via offline reinforcement learning. Empirical results on simulation benchmarks (Libero, Bigym) and real-world tasks validate that SuP achieves an overall 1.8x execution speedup for diverse policies while maintaining their original success rates.
Towards Practical World Model-based Reinforcement Learning for Vision-Language-Action Models
Mar 21, 2026Vision-Language-Action (VLA) models show strong generalization for robotic control, but finetuning them with reinforcement learning (RL) is constrained by the high cost and safety risks of real-world interaction. Training VLA models in interactive world models avoids these issues but introduces several challenges, including pixel-level world modeling, multi-view consistency, and compounding errors under sparse rewards. Building on recent advances across large multimodal models and model-based RL, we propose VLA-MBPO, a practical framework to tackle these problems in VLA finetuning. Our approach has three key design choices: (i) adapting unified multimodal models (UMMs) for data-efficient world modeling; (ii) an interleaved view decoding mechanism to enforce multi-view consistency; and (iii) chunk-level branched rollout to mitigate error compounding. Theoretical analysis and experiments across simulation and real-world tasks demonstrate that VLA-MBPO significantly improves policy performance and sample efficiency, underscoring its robustness and scalability for real-world robotic deployment.
The Three Regimes of Offline-to-Online Reinforcement Learning
Oct 01, 2025



Offline-to-online reinforcement learning (RL) has emerged as a practical paradigm that leverages offline datasets for pretraining and online interactions for fine-tuning. However, its empirical behavior is highly inconsistent: design choices of online-fine tuning that work well in one setting can fail completely in another. We propose a stability--plasticity principle that can explain this inconsistency: we should preserve the knowledge of pretrained policy or offline dataset during online fine-tuning, whichever is better, while maintaining sufficient plasticity. This perspective identifies three regimes of online fine-tuning, each requiring distinct stability properties. We validate this framework through a large-scale empirical study, finding that the results strongly align with its predictions in 45 of 63 cases. This work provides a principled framework for guiding design choices in offline-to-online RL based on the relative performance of the offline dataset and the pretrained policy.
TeraSim: Uncovering Unknown Unsafe Events for Autonomous Vehicles through Generative Simulation
Mar 06, 2025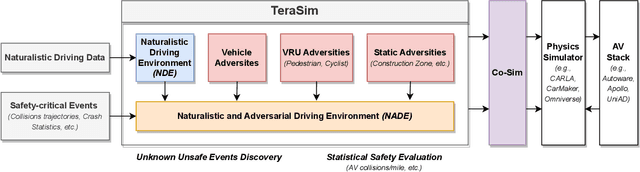

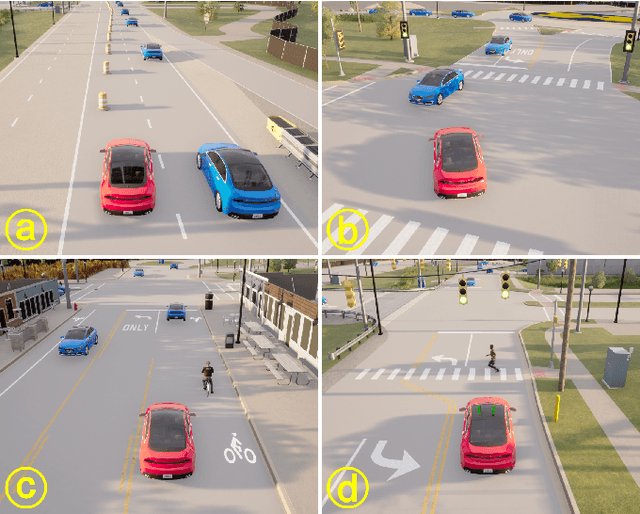
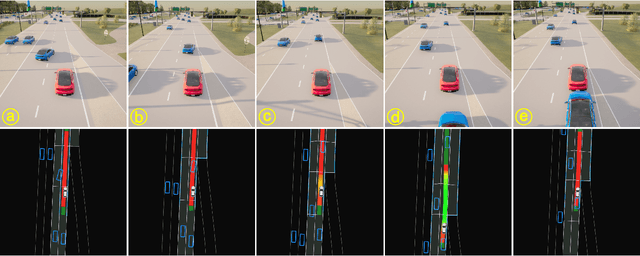
Traffic simulation is essential for autonomous vehicle (AV) development, enabling comprehensive safety evaluation across diverse driving conditions. However, traditional rule-based simulators struggle to capture complex human interactions, while data-driven approaches often fail to maintain long-term behavioral realism or generate diverse safety-critical events. To address these challenges, we propose TeraSim, an open-source, high-fidelity traffic simulation platform designed to uncover unknown unsafe events and efficiently estimate AV statistical performance metrics, such as crash rates. TeraSim is designed for seamless integration with third-party physics simulators and standalone AV stacks, to construct a complete AV simulation system. Experimental results demonstrate its effectiveness in generating diverse safety-critical events involving both static and dynamic agents, identifying hidden deficiencies in AV systems, and enabling statistical performance evaluation. These findings highlight TeraSim's potential as a practical tool for AV safety assessment, benefiting researchers, developers, and policymakers. The code is available at https://github.com/mcity/TeraSim.
WHALE: Towards Generalizable and Scalable World Models for Embodied Decision-making
Nov 08, 2024



World models play a crucial role in decision-making within embodied environments, enabling cost-free explorations that would otherwise be expensive in the real world. To facilitate effective decision-making, world models must be equipped with strong generalizability to support faithful imagination in out-of-distribution (OOD) regions and provide reliable uncertainty estimation to assess the credibility of the simulated experiences, both of which present significant challenges for prior scalable approaches. This paper introduces WHALE, a framework for learning generalizable world models, consisting of two key techniques: behavior-conditioning and retracing-rollout. Behavior-conditioning addresses the policy distribution shift, one of the primary sources of the world model generalization error, while retracing-rollout enables efficient uncertainty estimation without the necessity of model ensembles. These techniques are universal and can be combined with any neural network architecture for world model learning. Incorporating these two techniques, we present Whale-ST, a scalable spatial-temporal transformer-based world model with enhanced generalizability. We demonstrate the superiority of Whale-ST in simulation tasks by evaluating both value estimation accuracy and video generation fidelity. Additionally, we examine the effectiveness of our uncertainty estimation technique, which enhances model-based policy optimization in fully offline scenarios. Furthermore, we propose Whale-X, a 414M parameter world model trained on 970K trajectories from Open X-Embodiment datasets. We show that Whale-X exhibits promising scalability and strong generalizability in real-world manipulation scenarios using minimal demonstrations.
Provably and Practically Efficient Adversarial Imitation Learning with General Function Approximation
Nov 01, 2024



As a prominent category of imitation learning methods, adversarial imitation learning (AIL) has garnered significant practical success powered by neural network approximation. However, existing theoretical studies on AIL are primarily limited to simplified scenarios such as tabular and linear function approximation and involve complex algorithmic designs that hinder practical implementation, highlighting a gap between theory and practice. In this paper, we explore the theoretical underpinnings of online AIL with general function approximation. We introduce a new method called optimization-based AIL (OPT-AIL), which centers on performing online optimization for reward functions and optimism-regularized Bellman error minimization for Q-value functions. Theoretically, we prove that OPT-AIL achieves polynomial expert sample complexity and interaction complexity for learning near-expert policies. To our best knowledge, OPT-AIL is the first provably efficient AIL method with general function approximation. Practically, OPT-AIL only requires the approximate optimization of two objectives, thereby facilitating practical implementation. Empirical studies demonstrate that OPT-AIL outperforms previous state-of-the-art deep AIL methods in several challenging tasks.
Any-step Dynamics Model Improves Future Predictions for Online and Offline Reinforcement Learning
May 27, 2024



Model-based methods in reinforcement learning offer a promising approach to enhance data efficiency by facilitating policy exploration within a dynamics model. However, accurately predicting sequential steps in the dynamics model remains a challenge due to the bootstrapping prediction, which attributes the next state to the prediction of the current state. This leads to accumulated errors during model roll-out. In this paper, we propose the Any-step Dynamics Model (ADM) to mitigate the compounding error by reducing bootstrapping prediction to direct prediction. ADM allows for the use of variable-length plans as inputs for predicting future states without frequent bootstrapping. We design two algorithms, ADMPO-ON and ADMPO-OFF, which apply ADM in online and offline model-based frameworks, respectively. In the online setting, ADMPO-ON demonstrates improved sample efficiency compared to previous state-of-the-art methods. In the offline setting, ADMPO-OFF not only demonstrates superior performance compared to recent state-of-the-art offline approaches but also offers better quantification of model uncertainty using only a single ADM.
Assemblage: Automatic Binary Dataset Construction for Machine Learning
May 07, 2024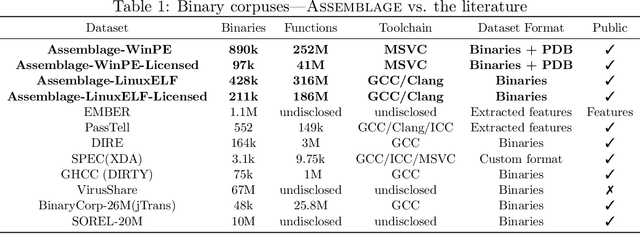
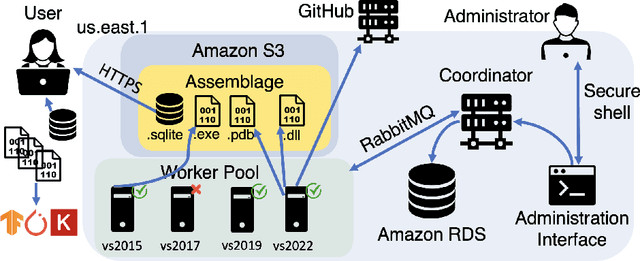

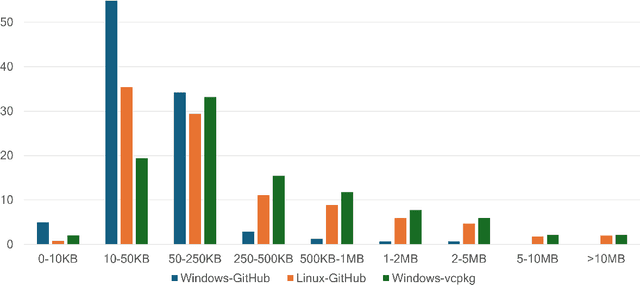
Binary code is pervasive, and binary analysis is a key task in reverse engineering, malware classification, and vulnerability discovery. Unfortunately, while there exist large corpuses of malicious binaries, obtaining high-quality corpuses of benign binaries for modern systems has proven challenging (e.g., due to licensing issues). Consequently, machine learning based pipelines for binary analysis utilize either costly commercial corpuses (e.g., VirusTotal) or open-source binaries (e.g., coreutils) available in limited quantities. To address these issues, we present Assemblage: an extensible cloud-based distributed system that crawls, configures, and builds Windows PE binaries to obtain high-quality binary corpuses suitable for training state-of-the-art models in binary analysis. We have run Assemblage on AWS over the past year, producing 890k Windows PE and 428k Linux ELF binaries across 29 configurations. Assemblage is designed to be both reproducible and extensible, enabling users to publish "recipes" for their datasets, and facilitating the extraction of a wide array of features. We evaluated Assemblage by using its data to train modern learning-based pipelines for compiler provenance and binary function similarity. Our results illustrate the practical need for robust corpuses of high-quality Windows PE binaries in training modern learning-based binary analyses. Assemblage can be downloaded from https://assemblage-dataset.net
Episodic Return Decomposition by Difference of Implicitly Assigned Sub-Trajectory Reward
Dec 17, 2023



Real-world decision-making problems are usually accompanied by delayed rewards, which affects the sample efficiency of Reinforcement Learning, especially in the extremely delayed case where the only feedback is the episodic reward obtained at the end of an episode. Episodic return decomposition is a promising way to deal with the episodic-reward setting. Several corresponding algorithms have shown remarkable effectiveness of the learned step-wise proxy rewards from return decomposition. However, these existing methods lack either attribution or representation capacity, leading to inefficient decomposition in the case of long-term episodes. In this paper, we propose a novel episodic return decomposition method called Diaster (Difference of implicitly assigned sub-trajectory reward). Diaster decomposes any episodic reward into credits of two divided sub-trajectories at any cut point, and the step-wise proxy rewards come from differences in expectation. We theoretically and empirically verify that the decomposed proxy reward function can guide the policy to be nearly optimal. Experimental results show that our method outperforms previous state-of-the-art methods in terms of both sample efficiency and performance.
AATCT-IDS: A Benchmark Abdominal Adipose Tissue CT Image Dataset for Image Denoising, Semantic Segmentation, and Radiomics Evaluation
Aug 16, 2023Methods: In this study, a benchmark \emph{Abdominal Adipose Tissue CT Image Dataset} (AATTCT-IDS) containing 300 subjects is prepared and published. AATTCT-IDS publics 13,732 raw CT slices, and the researchers individually annotate the subcutaneous and visceral adipose tissue regions of 3,213 of those slices that have the same slice distance to validate denoising methods, train semantic segmentation models, and study radiomics. For different tasks, this paper compares and analyzes the performance of various methods on AATTCT-IDS by combining the visualization results and evaluation data. Thus, verify the research potential of this data set in the above three types of tasks. Results: In the comparative study of image denoising, algorithms using a smoothing strategy suppress mixed noise at the expense of image details and obtain better evaluation data. Methods such as BM3D preserve the original image structure better, although the evaluation data are slightly lower. The results show significant differences among them. In the comparative study of semantic segmentation of abdominal adipose tissue, the segmentation results of adipose tissue by each model show different structural characteristics. Among them, BiSeNet obtains segmentation results only slightly inferior to U-Net with the shortest training time and effectively separates small and isolated adipose tissue. In addition, the radiomics study based on AATTCT-IDS reveals three adipose distributions in the subject population. Conclusion: AATTCT-IDS contains the ground truth of adipose tissue regions in abdominal CT slices. This open-source dataset can attract researchers to explore the multi-dimensional characteristics of abdominal adipose tissue and thus help physicians and patients in clinical practice. AATCT-IDS is freely published for non-commercial purpose at: \url{https://figshare.com/articles/dataset/AATTCT-IDS/23807256}.