 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinVBC: A Model-based Reinforcement Learning Approach to Vehicle Braking Controller
Apr 06, 2026Braking system, the key module to ensure the safety and steer-ability of current vehicles, relies on extensive manual calibration during production. Reducing labor and time consumption while maintaining the Vehicle Braking Controller (VBC) performance greatly benefits the vehicle industry. Model-based methods in offline reinforcement learning, which facilitate policy exploration within a data-driven dynamics model, offer a promising solution for addressing real-world control tasks. This work proposes ReinVBC, which applies an offline model-based reinforcement learning approach to deal with the vehicle braking control problem. We introduce useful engineering designs into the paradigm of model learning and utilization to obtain a reliable vehicle dynamics model and a capable braking policy. Several results demonstrate the capability of our method in real-world vehicle braking and its potential to replace the production-grade anti-lock braking system.
Speedup Patch: Learning a Plug-and-Play Policy to Accelerate Embodied Manipulation
Mar 21, 2026While current embodied policies exhibit remarkable manipulation skills, their execution remains unsatisfactorily slow as they inherit the tardy pacing of human demonstrations. Existing acceleration methods typically require policy retraining or costly online interactions, limiting their scalability for large-scale foundation models. In this paper, we propose Speedup Patch (SuP), a lightweight, policy-agnostic framework that enables plug-and-play acceleration using solely offline data. SuP introduces an external scheduler that adaptively downsamples action chunks provided by embodied policies to eliminate redundancies. Specifically, we formalize the optimization of our scheduler as a Constrained Markov Decision Process (CMDP) aimed at maximizing efficiency without compromising task performance. Since direct success evaluation is infeasible in offline settings, SuP introduces World Model based state deviation as a surrogate metric to enforce safety constraints. By leveraging a learned world model as a virtual evaluator to predict counterfactual trajectories, the scheduler can be optimized via offline reinforcement learning. Empirical results on simulation benchmarks (Libero, Bigym) and real-world tasks validate that SuP achieves an overall 1.8x execution speedup for diverse policies while maintaining their original success rates.
Towards Practical World Model-based Reinforcement Learning for Vision-Language-Action Models
Mar 21, 2026Vision-Language-Action (VLA) models show strong generalization for robotic control, but finetuning them with reinforcement learning (RL) is constrained by the high cost and safety risks of real-world interaction. Training VLA models in interactive world models avoids these issues but introduces several challenges, including pixel-level world modeling, multi-view consistency, and compounding errors under sparse rewards. Building on recent advances across large multimodal models and model-based RL, we propose VLA-MBPO, a practical framework to tackle these problems in VLA finetuning. Our approach has three key design choices: (i) adapting unified multimodal models (UMMs) for data-efficient world modeling; (ii) an interleaved view decoding mechanism to enforce multi-view consistency; and (iii) chunk-level branched rollout to mitigate error compounding. Theoretical analysis and experiments across simulation and real-world tasks demonstrate that VLA-MBPO significantly improves policy performance and sample efficiency, underscoring its robustness and scalability for real-world robotic deployment.
WHALE: Towards Generalizable and Scalable World Models for Embodied Decision-making
Nov 08, 2024



World models play a crucial role in decision-making within embodied environments, enabling cost-free explorations that would otherwise be expensive in the real world. To facilitate effective decision-making, world models must be equipped with strong generalizability to support faithful imagination in out-of-distribution (OOD) regions and provide reliable uncertainty estimation to assess the credibility of the simulated experiences, both of which present significant challenges for prior scalable approaches. This paper introduces WHALE, a framework for learning generalizable world models, consisting of two key techniques: behavior-conditioning and retracing-rollout. Behavior-conditioning addresses the policy distribution shift, one of the primary sources of the world model generalization error, while retracing-rollout enables efficient uncertainty estimation without the necessity of model ensembles. These techniques are universal and can be combined with any neural network architecture for world model learning. Incorporating these two techniques, we present Whale-ST, a scalable spatial-temporal transformer-based world model with enhanced generalizability. We demonstrate the superiority of Whale-ST in simulation tasks by evaluating both value estimation accuracy and video generation fidelity. Additionally, we examine the effectiveness of our uncertainty estimation technique, which enhances model-based policy optimization in fully offline scenarios. Furthermore, we propose Whale-X, a 414M parameter world model trained on 970K trajectories from Open X-Embodiment datasets. We show that Whale-X exhibits promising scalability and strong generalizability in real-world manipulation scenarios using minimal demonstrations.
Any-step Dynamics Model Improves Future Predictions for Online and Offline Reinforcement Learning
May 27, 2024



Model-based methods in reinforcement learning offer a promising approach to enhance data efficiency by facilitating policy exploration within a dynamics model. However, accurately predicting sequential steps in the dynamics model remains a challenge due to the bootstrapping prediction, which attributes the next state to the prediction of the current state. This leads to accumulated errors during model roll-out. In this paper, we propose the Any-step Dynamics Model (ADM) to mitigate the compounding error by reducing bootstrapping prediction to direct prediction. ADM allows for the use of variable-length plans as inputs for predicting future states without frequent bootstrapping. We design two algorithms, ADMPO-ON and ADMPO-OFF, which apply ADM in online and offline model-based frameworks, respectively. In the online setting, ADMPO-ON demonstrates improved sample efficiency compared to previous state-of-the-art methods. In the offline setting, ADMPO-OFF not only demonstrates superior performance compared to recent state-of-the-art offline approaches but also offers better quantification of model uncertainty using only a single ADM.
Episodic Return Decomposition by Difference of Implicitly Assigned Sub-Trajectory Reward
Dec 17, 2023



Real-world decision-making problems are usually accompanied by delayed rewards, which affects the sample efficiency of Reinforcement Learning, especially in the extremely delayed case where the only feedback is the episodic reward obtained at the end of an episode. Episodic return decomposition is a promising way to deal with the episodic-reward setting. Several corresponding algorithms have shown remarkable effectiveness of the learned step-wise proxy rewards from return decomposition. However, these existing methods lack either attribution or representation capacity, leading to inefficient decomposition in the case of long-term episodes. In this paper, we propose a novel episodic return decomposition method called Diaster (Difference of implicitly assigned sub-trajectory reward). Diaster decomposes any episodic reward into credits of two divided sub-trajectories at any cut point, and the step-wise proxy rewards come from differences in expectation. We theoretically and empirically verify that the decomposed proxy reward function can guide the policy to be nearly optimal. Experimental results show that our method outperforms previous state-of-the-art methods in terms of both sample efficiency and performance.
Model-based Reinforcement Learning with Multi-step Plan Value Estimation
Sep 12, 2022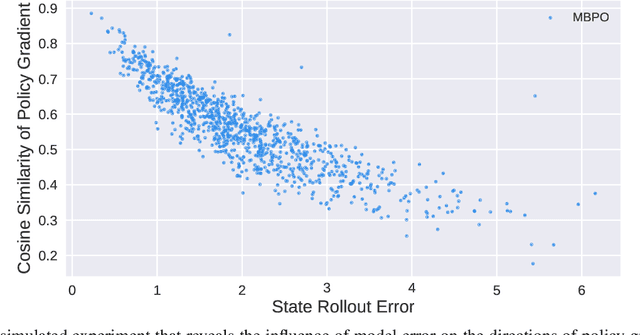
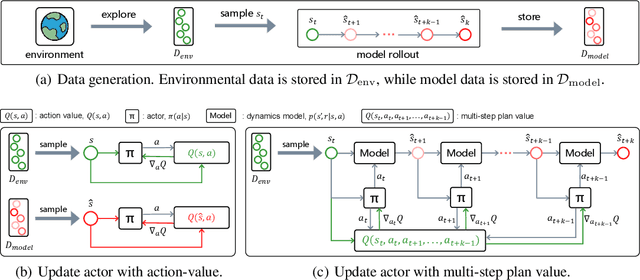
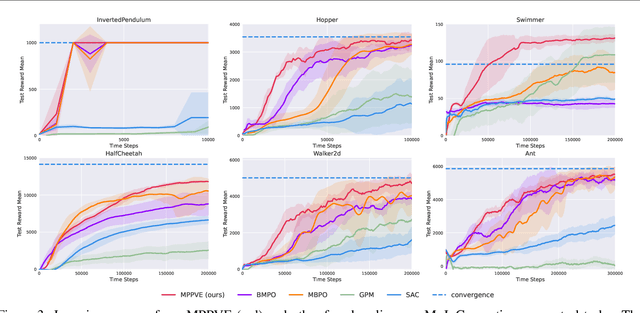
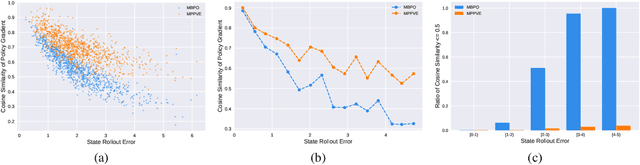
A promising way to improve the sample efficiency of reinforcement learning is model-based methods, in which many explorations and evaluations can happen in the learned models to save real-world samples. However, when the learned model has a non-negligible model error, sequential steps in the model are hard to be accurately evaluated, limiting the model's utilization. This paper proposes to alleviate this issue by introducing multi-step plans to replace multi-step actions for model-based RL. We employ the multi-step plan value estimation, which evaluates the expected discounted return after executing a sequence of action plans at a given state, and updates the policy by directly computing the multi-step policy gradient via plan value estimation. The new model-based reinforcement learning algorithm MPPVE (Model-based Planning Policy Learning with Multi-step Plan Value Estimation) shows a better utilization of the learned model and achieves a better sample efficiency than state-of-the-art model-based RL approaches.