 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLGOR: Visual-Language Knowledge Guided Offline Reinforcement Learning for Generalizable Agents
Mar 24, 2026Combining Large Language Models (LLMs) with Reinforcement Learning (RL) enables agents to interpret language instructions more effectively for task execution. However, LLMs typically lack direct perception of the physical environment, which limits their understanding of environmental dynamics and their ability to generalize to unseen tasks. To address this limitation, we propose Visual-Language Knowledge-Guided Offline Reinforcement Learning (VLGOR), a framework that integrates visual and language knowledge to generate imaginary rollouts, thereby enriching the interaction data. The core premise of VLGOR is to fine-tune a vision-language model to predict future states and actions conditioned on an initial visual observation and high-level instructions, ensuring that the generated rollouts remain temporally coherent and spatially plausible. Furthermore, we employ counterfactual prompts to produce more diverse rollouts for offline RL training, enabling the agent to acquire knowledge that facilitates following language instructions while grounding in environments based on visual cues. Experiments on robotic manipulation benchmarks demonstrate that VLGOR significantly improves performance on unseen tasks requiring novel optimal policies, achieving a success rate over 24% higher than the baseline methods.
RLVR Training of LLMs Does Not Improve Thinking Ability for General QA: Evaluation Method and a Simple Solution
Mar 21, 2026Reinforcement learning from verifiable rewards (RLVR) stimulates the thinking processes of large language models (LLMs), substantially enhancing their reasoning abilities on verifiable tasks. It is often assumed that similar gains should transfer to general question answering (GQA), but this assumption has not been thoroughly validated. To assess whether RLVR automatically improves LLM performance on GQA, we propose a Cross-Generation evaluation framework that measures the quality of intermediate reasoning by feeding the generated thinking context into LLMs of varying capabilities. Our evaluation leads to a discouraging finding: the efficacy of the thinking process on GQA tasks is markedly lower than on verifiable tasks, suggesting that explicit training on GQA remains necessary in addition to training on verifiable tasks. We further observe that direct RL training on GQA is less effective than RLVR. Our hypothesis is that, whereas verifiable tasks demand robust logical chains to obtain high rewards, GQA tasks often admit shortcuts to high rewards without cultivating high-quality thinking. To avoid possible shortcuts, we introduce a simple method, Separated Thinking And Response Training (START), which first trains only the thinking process, using rewards defined on the final answer. We show that START improves both the quality of thinking and the final answer across several GQA benchmarks and RL algorithms.
MALLOC: Benchmarking the Memory-aware Long Sequence Compression for Large Sequential Recommendation
Jan 29, 2026The scaling law, which indicates that model performance improves with increasing dataset and model capacity, has fueled a growing trend in expanding recommendation models in both industry and academia. However, the advent of large-scale recommenders also brings significantly higher computational costs, particularly under the long-sequence dependencies inherent in the user intent of recommendation systems. Current approaches often rely on pre-storing the intermediate states of the past behavior for each user, thereby reducing the quadratic re-computation cost for the following requests. Despite their effectiveness, these methods often treat memory merely as a medium for acceleration, without adequately considering the space overhead it introduces. This presents a critical challenge in real-world recommendation systems with billions of users, each of whom might initiate thousands of interactions and require massive memory for state storage. Fortunately, there have been several memory management strategies examined for compression in LLM, while most have not been evaluated on the recommendation task. To mitigate this gap, we introduce MALLOC, a comprehensive benchmark for memory-aware long sequence compression. MALLOC presents a comprehensive investigation and systematic classification of memory management techniques applicable to large sequential recommendations. These techniques are integrated into state-of-the-art recommenders, enabling a reproducible and accessible evaluation platform. Through extensive experiments across accuracy, efficiency, and complexity, we demonstrate the holistic reliability of MALLOC in advancing large-scale recommendation. Code is available at https://anonymous.4open.science/r/MALLOC.
VQL: An End-to-End Context-Aware Vector Quantization Attention for Ultra-Long User Behavior Modeling
Aug 23, 2025In large-scale recommender systems, ultra-long user behavior sequences encode rich signals of evolving interests. Extending sequence length generally improves accuracy, but directly modeling such sequences in production is infeasible due to latency and memory constraints. Existing solutions fall into two categories: (1) top-k retrieval, which truncates the sequence and may discard most attention mass when L >> k; and (2) encoder-based compression, which preserves coverage but often over-compresses and fails to incorporate key context such as temporal gaps or target-aware signals. Neither class achieves a good balance of low-loss compression, context awareness, and efficiency. We propose VQL, a context-aware Vector Quantization Attention framework for ultra-long behavior modeling, with three innovations. (1) Key-only quantization: only attention keys are quantized, while values remain intact; we prove that softmax normalization yields an error bound independent of sequence length, and a codebook loss directly supervises quantization quality. This also enables L-free inference via offline caches. (2) Multi-scale quantization: attention heads are partitioned into groups, each with its own small codebook, which reduces quantization error while keeping cache size fixed. (3) Efficient context injection: static features (e.g., item category, modality) are directly integrated, and relative position is modeled via a separable temporal kernel. All context is injected without enlarging the codebook, so cached representations remain query-independent. Experiments on three large-scale datasets (KuaiRand-1K, KuaiRec, TMALL) show that VQL consistently outperforms strong baselines, achieving higher accuracy while reducing inference latency, establishing a new state of the art in balancing accuracy and efficiency for ultra-long sequence recommendation.
Balanced Token Pruning: Accelerating Vision Language Models Beyond Local Optimization
May 28, 2025Large Vision-Language Models (LVLMs) have shown impressive performance across multi-modal tasks by encoding images into thousands of tokens. However, the large number of image tokens results in significant computational overhead, and the use of dynamic high-resolution inputs further increases this burden. Previous approaches have attempted to reduce the number of image tokens through token pruning, typically by selecting tokens based on attention scores or image token diversity. Through empirical studies, we observe that existing methods often overlook the joint impact of pruning on both the current layer's output (local) and the outputs of subsequent layers (global), leading to suboptimal pruning decisions. To address this challenge, we propose Balanced Token Pruning (BTP), a plug-and-play method for pruning vision tokens. Specifically, our method utilizes a small calibration set to divide the pruning process into multiple stages. In the early stages, our method emphasizes the impact of pruning on subsequent layers, whereas in the deeper stages, the focus shifts toward preserving the consistency of local outputs. Extensive experiments across various LVLMs demonstrate the broad effectiveness of our approach on multiple benchmarks. Our method achieves a 78% compression rate while preserving 96.7% of the original models' performance on average.
ImagineBench: Evaluating Reinforcement Learning with Large Language Model Rollouts
May 15, 2025A central challenge in reinforcement learning (RL) is its dependence on extensive real-world interaction data to learn task-specific policies. While recent work demonstrates that large language models (LLMs) can mitigate this limitation by generating synthetic experience (noted as imaginary rollouts) for mastering novel tasks, progress in this emerging field is hindered due to the lack of a standard benchmark. To bridge this gap, we introduce ImagineBench, the first comprehensive benchmark for evaluating offline RL algorithms that leverage both real rollouts and LLM-imaginary rollouts. The key features of ImagineBench include: (1) datasets comprising environment-collected and LLM-imaginary rollouts; (2) diverse domains of environments covering locomotion, robotic manipulation, and navigation tasks; and (3) natural language task instructions with varying complexity levels to facilitate language-conditioned policy learning. Through systematic evaluation of state-of-the-art offline RL algorithms, we observe that simply applying existing offline RL algorithms leads to suboptimal performance on unseen tasks, achieving 35.44% success rate in hard tasks in contrast to 64.37% of method training on real rollouts for hard tasks. This result highlights the need for algorithm advancements to better leverage LLM-imaginary rollouts. Additionally, we identify key opportunities for future research: including better utilization of imaginary rollouts, fast online adaptation and continual learning, and extension to multi-modal tasks. Our code is publicly available at https://github.com/LAMDA-RL/ImagineBench.
BBQRec: Behavior-Bind Quantization for Multi-Modal Sequential Recommendation
Apr 09, 2025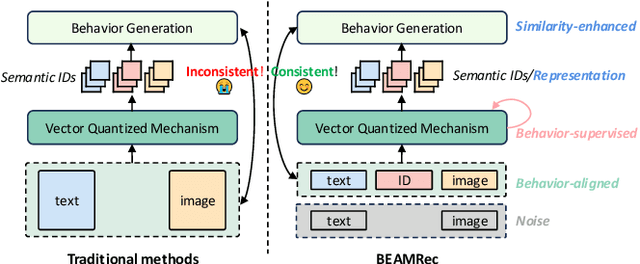
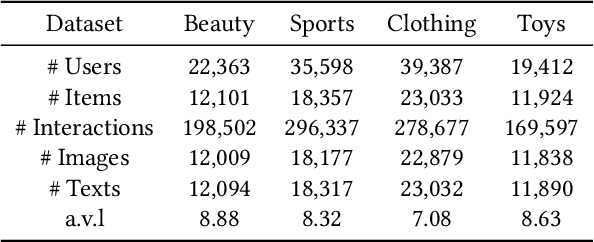
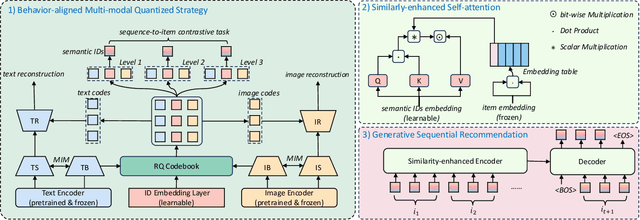
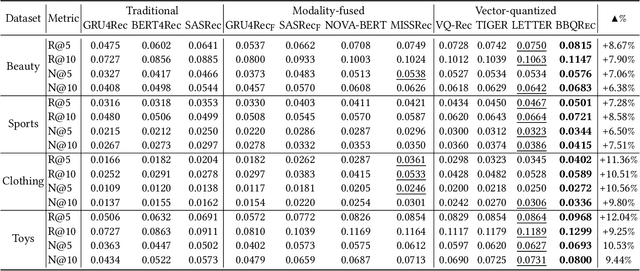
Multi-modal sequential recommendation systems leverage auxiliary signals (e.g., text, images) to alleviate data sparsity in user-item interactions. While recent methods exploit large language models to encode modalities into discrete semantic IDs for autoregressive prediction, we identify two critical limitations: (1) Existing approaches adopt fragmented quantization, where modalities are independently mapped to semantic spaces misaligned with behavioral objectives, and (2) Over-reliance on semantic IDs disrupts inter-modal semantic coherence, thereby weakening the expressive power of multi-modal representations for modeling diverse user preferences. To address these challenges, we propose a Behavior-Bind multi-modal Quantization for Sequential Recommendation (BBQRec for short) featuring dual-aligned quantization and semantics-aware sequence modeling. First, our behavior-semantic alignment module disentangles modality-agnostic behavioral patterns from noisy modality-specific features through contrastive codebook learning, ensuring semantic IDs are inherently tied to recommendation tasks. Second, we design a discretized similarity reweighting mechanism that dynamically adjusts self-attention scores using quantized semantic relationships, preserving multi-modal synergies while avoiding invasive modifications to the sequence modeling architecture. Extensive evaluations across four real-world benchmarks demonstrate BBQRec's superiority over the state-of-the-art baselines.
CHIME: A Compressive Framework for Holistic Interest Modeling
Apr 09, 2025Modeling holistic user interests is important for improving recommendation systems but is challenged by high computational cost and difficulty in handling diverse information with full behavior context. Existing search-based methods might lose critical signals during behavior selection. To overcome these limitations, we propose CHIME: A Compressive Framework for Holistic Interest Modeling. It uses adapted large language models to encode complete user behaviors with heterogeneous inputs. We introduce multi-granular contrastive learning objectives to capture both persistent and transient interest patterns and apply residual vector quantization to generate compact embeddings. CHIME demonstrates superior ranking performance across diverse datasets, establishing a robust solution for scalable holistic interest modeling in recommendation systems.
The Point, the Vision and the Text: Does Point Cloud Boost Spatial Reasoning of Large Language Models?
Apr 06, 20253D Large Language Models (LLMs) leveraging spatial information in point clouds for 3D spatial reasoning attract great attention. Despite some promising results, the role of point clouds in 3D spatial reasoning remains under-explored. In this work, we comprehensively evaluate and analyze these models to answer the research question: \textit{Does point cloud truly boost the spatial reasoning capacities of 3D LLMs?} We first evaluate the spatial reasoning capacity of LLMs with different input modalities by replacing the point cloud with the visual and text counterparts. We then propose a novel 3D QA (Question-answering) benchmark, ScanReQA, that comprehensively evaluates models' understanding of binary spatial relationships. Our findings reveal several critical insights: 1) LLMs without point input could even achieve competitive performance even in a zero-shot manner; 2) existing 3D LLMs struggle to comprehend the binary spatial relationships; 3) 3D LLMs exhibit limitations in exploiting the structural coordinates in point clouds for fine-grained spatial reasoning. We think these conclusions can help the next step of 3D LLMs and also offer insights for foundation models in other modalities. We release datasets and reproducible codes in the anonymous project page: https://3d-llm.xyz.
PLPHP: Per-Layer Per-Head Vision Token Pruning for Efficient Large Vision-Language Models
Feb 20, 2025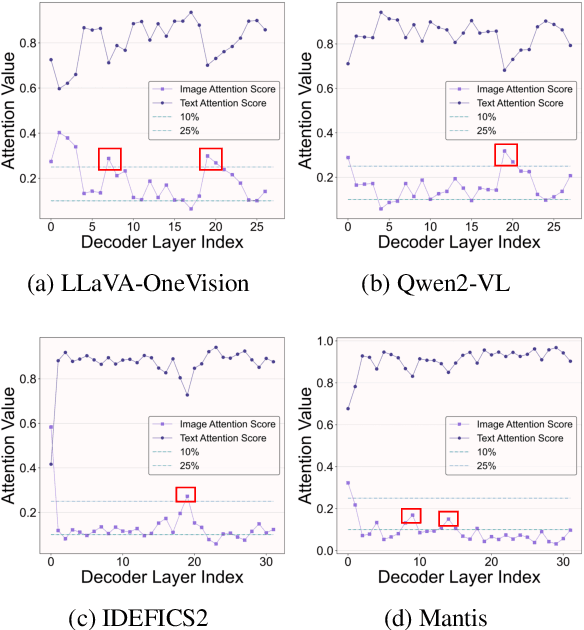
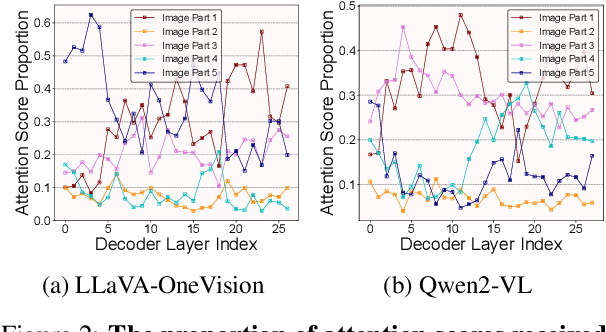
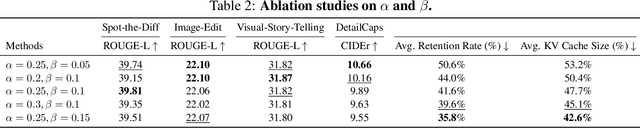
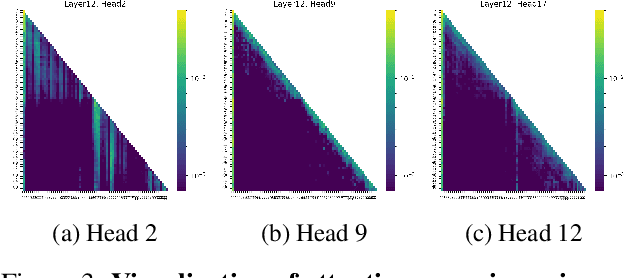
Large Vision-Language Models (LVLMs) have demonstrated remarkable capabilities across a range of multimodal tasks. However, their inference efficiency is constrained by the large number of visual tokens processed during decoding. To address this challenge, we propose Per-Layer Per-Head Vision Token Pruning (PLPHP), a two-level fine-grained pruning method including Layer-Level Retention Rate Allocation and Head-Level Vision Token Pruning. Motivated by the Vision Token Re-attention phenomenon across decoder layers, we dynamically adjust token retention rates layer by layer. Layers that exhibit stronger attention to visual information preserve more vision tokens, while layers with lower vision attention are aggressively pruned. Furthermore, PLPHP applies pruning at the attention head level, enabling different heads within the same layer to independently retain critical context. Experiments on multiple benchmarks demonstrate that PLPHP delivers an 18% faster decoding speed and reduces the Key-Value Cache (KV Cache) size by over 50%, all at the cost of 0.46% average performance drop, while also achieving notable performance improvements in multi-image tasks. These results highlight the effectiveness of fine-grained token pruning and contribute to advancing the efficiency and scalability of LVLMs. Our source code will be made publicly available.