 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-based Evaluation Policy Extraction for Ecological Modeling
May 20, 2025Evaluating ecological time series is critical for benchmarking model performance in many important applications, including predicting greenhouse gas fluxes, capturing carbon-nitrogen dynamics, and monitoring hydrological cycles. Traditional numerical metrics (e.g., R-squared, root mean square error) have been widely used to quantify the similarity between modeled and observed ecosystem variables, but they often fail to capture domain-specific temporal patterns critical to ecological processes. As a result, these methods are often accompanied by expert visual inspection, which requires substantial human labor and limits the applicability to large-scale evaluation. To address these challenges, we propose a novel framework that integrates metric learning with large language model (LLM)-based natural language policy extraction to develop interpretable evaluation criteria. The proposed method processes pairwise annotations and implements a policy optimization mechanism to generate and combine different assessment metrics. The results obtained on multiple datasets for evaluating the predictions of crop gross primary production and carbon dioxide flux have confirmed the effectiveness of the proposed method in capturing target assessment preferences, including both synthetically generated and expert-annotated model comparisons. The proposed framework bridges the gap between numerical metrics and expert knowledge while providing interpretable evaluation policies that accommodate the diverse needs of different ecosystem modeling studies.
Knowledge Guided Encoder-Decoder Framework: Integrating Multiple Physical Models for Agricultural Ecosystem Modeling
May 13, 2025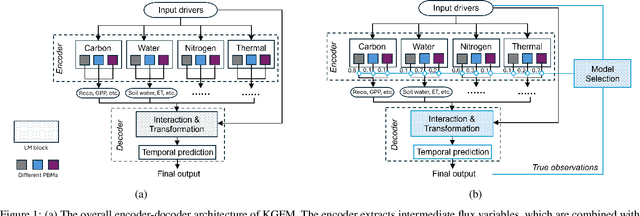
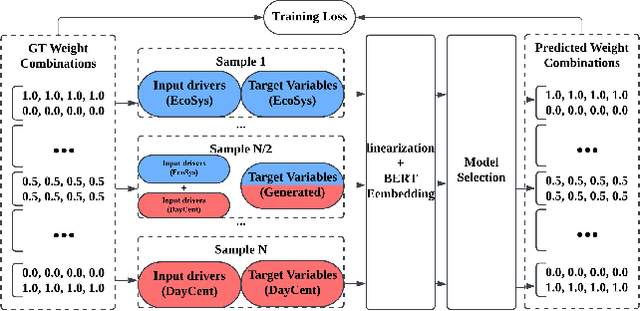
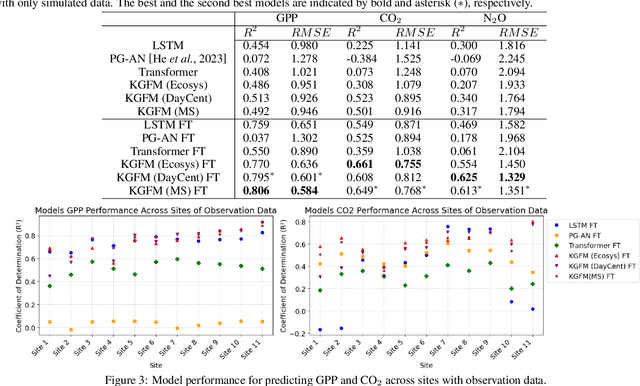
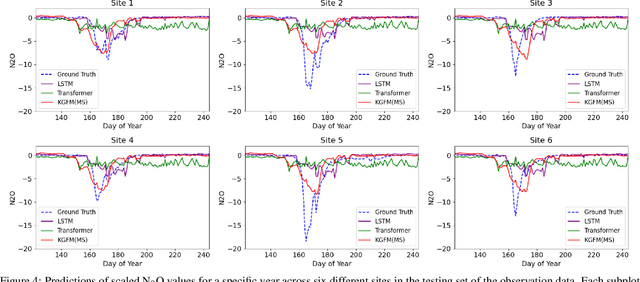
Agricultural monitoring is critical for ensuring food security, maintaining sustainable farming practices, informing policies on mitigating food shortage, and managing greenhouse gas emissions. Traditional process-based physical models are often designed and implemented for specific situations, and their parameters could also be highly uncertain. In contrast, data-driven models often use black-box structures and does not explicitly model the inter-dependence between different ecological variables. As a result, they require extensive training data and lack generalizability to different tasks with data distribution shifts and inconsistent observed variables. To address the need for more universal models, we propose a knowledge-guided encoder-decoder model, which can predict key crop variables by leveraging knowledge of underlying processes from multiple physical models. The proposed method also integrates a language model to process complex and inconsistent inputs and also utilizes it to implement a model selection mechanism for selectively combining the knowledge from different physical models. Our evaluations on predicting carbon and nitrogen fluxes for multiple sites demonstrate the effectiveness and robustness of the proposed model under various scenarios.
CropCraft: Inverse Procedural Modeling for 3D Reconstruction of Crop Plants
Nov 14, 2024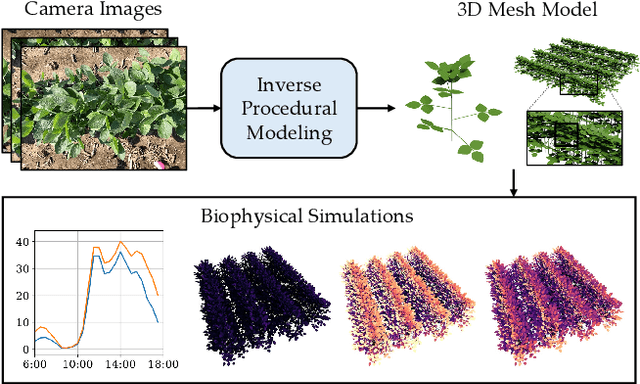
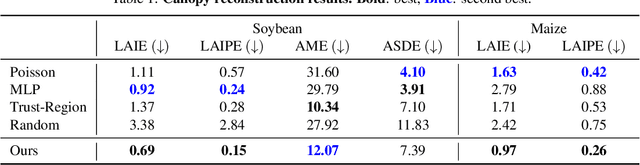
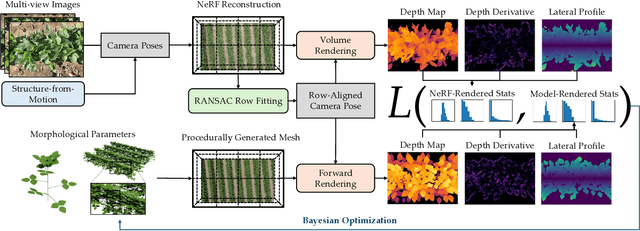
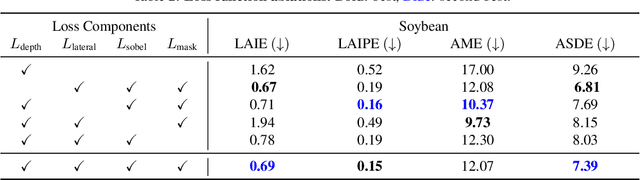
The ability to automatically build 3D digital twins of plants from images has countless applications in agriculture, environmental science, robotics, and other fields. However, current 3D reconstruction methods fail to recover complete shapes of plants due to heavy occlusion and complex geometries. In this work, we present a novel method for 3D reconstruction of agricultural crops based on optimizing a parametric model of plant morphology via inverse procedural modeling. Our method first estimates depth maps by fitting a neural radiance field and then employs Bayesian optimization to estimate plant morphological parameters that result in consistent depth renderings. The resulting 3D model is complete and biologically plausible. We validate our method on a dataset of real images of agricultural fields, and demonstrate that the reconstructions can be used for a variety of monitoring and simulation applications.
Hierarchical Conditional Multi-Task Learning for Streamflow Modeling
Oct 18, 2024Streamflow, vital for water resource management, is governed by complex hydrological systems involving intermediate processes driven by meteorological forces. While deep learning models have achieved state-of-the-art results of streamflow prediction, their end-to-end single-task learning approach often fails to capture the causal relationships within these systems. To address this, we propose Hierarchical Conditional Multi-Task Learning (HCMTL), a hierarchical approach that jointly models soil water and snowpack processes based on their causal connections to streamflow. HCMTL utilizes task embeddings to connect network modules, enhancing flexibility and expressiveness while capturing unobserved processes beyond soil water and snowpack. It also incorporates the Conditional Mini-Batch strategy to improve long time series modeling. We compare HCMTL with five baselines on a global dataset. HCMTL's superior performance across hundreds of drainage basins over extended periods shows that integrating domain-specific causal knowledge into deep learning enhances both prediction accuracy and interpretability. This is essential for advancing our understanding of complex hydrological systems and supporting efficient water resource management to mitigate natural disasters like droughts and floods.
FREE: The Foundational Semantic Recognition for Modeling Environmental Ecosystems
Nov 17, 2023Modeling environmental ecosystems is critical for the sustainability of our planet, but is extremely challenging due to the complex underlying processes driven by interactions amongst a large number of physical variables. As many variables are difficult to measure at large scales, existing works often utilize a combination of observable features and locally available measurements or modeled values as input to build models for a specific study region and time period. This raises a fundamental question in advancing the modeling of environmental ecosystems: how to build a general framework for modeling the complex relationships amongst various environmental data over space and time? In this paper, we introduce a new framework, FREE, which maps available environmental data into a text space and then converts the traditional predictive modeling task in environmental science to the semantic recognition problem. The proposed FREE framework leverages recent advances in Large Language Models (LLMs) to supplement the original input features with natural language descriptions. This facilitates capturing the data semantics and also allows harnessing the irregularities of input features. When used for long-term prediction, FREE has the flexibility to incorporate newly collected observations to enhance future prediction. The efficacy of FREE is evaluated in the context of two societally important real-world applications, predicting stream water temperature in the Delaware River Basin and predicting annual corn yield in Illinois and Iowa. Beyond the superior predictive performance over multiple baseline methods, FREE is shown to be more data- and computation-efficient as it can be pre-trained on simulated data generated by physics-based models.
Mapping smallholder cashew plantations to inform sustainable tree crop expansion in Benin
Jan 01, 2023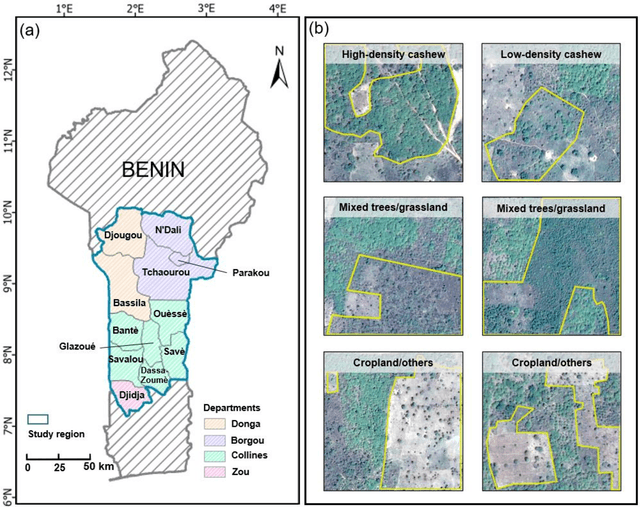

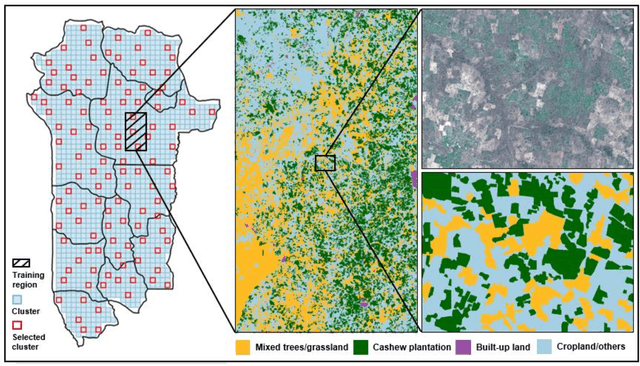
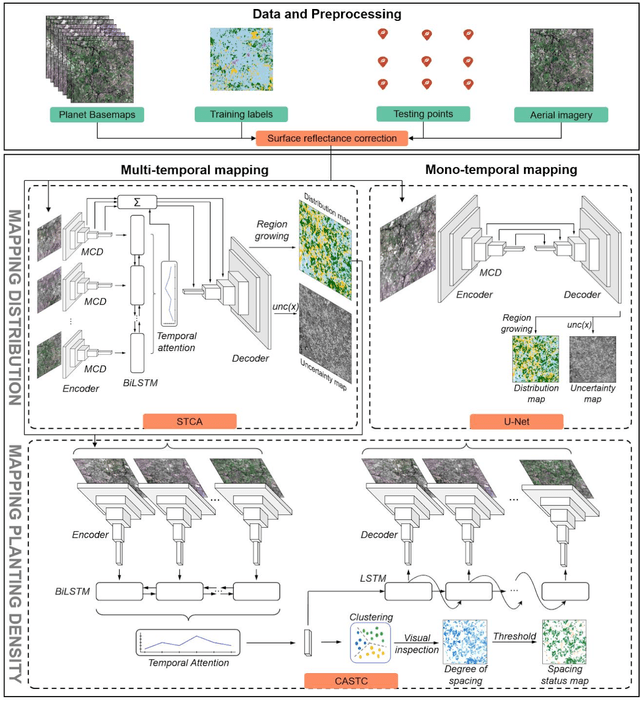
Cashews are grown by over 3 million smallholders in more than 40 countries worldwide as a principal source of income. As the third largest cashew producer in Africa, Benin has nearly 200,000 smallholder cashew growers contributing 15% of the country's national export earnings. However, a lack of information on where and how cashew trees grow across the country hinders decision-making that could support increased cashew production and poverty alleviation. By leveraging 2.4-m Planet Basemaps and 0.5-m aerial imagery, newly developed deep learning algorithms, and large-scale ground truth datasets, we successfully produced the first national map of cashew in Benin and characterized the expansion of cashew plantations between 2015 and 2021. In particular, we developed a SpatioTemporal Classification with Attention (STCA) model to map the distribution of cashew plantations, which can fully capture texture information from discriminative time steps during a growing season. We further developed a Clustering Augmented Self-supervised Temporal Classification (CASTC) model to distinguish high-density versus low-density cashew plantations by automatic feature extraction and optimized clustering. Results show that the STCA model has an overall accuracy of 80% and the CASTC model achieved an overall accuracy of 77.9%. We found that the cashew area in Benin has doubled from 2015 to 2021 with 60% of new plantation development coming from cropland or fallow land, while encroachment of cashew plantations into protected areas has increased by 70%. Only half of cashew plantations were high-density in 2021, suggesting high potential for intensification. Our study illustrates the power of combining high-resolution remote sensing imagery and state-of-the-art deep learning algorithms to better understand tree crops in the heterogeneous smallholder landscape.
Task-Adaptive Meta-Learning Framework for Advancing Spatial Generalizability
Dec 10, 2022

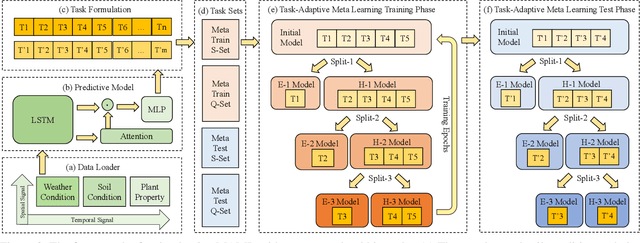

Spatio-temporal machine learning is critically needed for a variety of societal applications, such as agricultural monitoring, hydrological forecast, and traffic management. These applications greatly rely on regional features that characterize spatial and temporal differences. However, spatio-temporal data are often complex and pose several unique challenges for machine learning models: 1) multiple models are needed to handle region-based data patterns that have significant spatial heterogeneity across different locations; 2) local models trained on region-specific data have limited ability to adapt to other regions that have large diversity and abnormality; 3) spatial and temporal variations entangle data complexity that requires more robust and adaptive models; 4) limited spatial-temporal data in real scenarios (e.g., crop yield data is collected only once a year) makes the problems intrinsically challenging. To bridge these gaps, we propose task-adaptive formulations and a model-agnostic meta-learning framework that ensembles regionally heterogeneous data into location-sensitive meta tasks. We conduct task adaptation following an easy-to-hard task hierarchy in which different meta models are adapted to tasks of different difficulty levels. One major advantage of our proposed method is that it improves the model adaptation to a large number of heterogeneous tasks. It also enhances the model generalization by automatically adapting the meta model of the corresponding difficulty level to any new tasks. We demonstrate the superiority of our proposed framework over a diverse set of baselines and state-of-the-art meta-learning frameworks. Our extensive experiments on real crop yield data show the effectiveness of the proposed method in handling spatial-related heterogeneous tasks in real societal applications.
Early- and in-season crop type mapping without current-year ground truth: generating labels from historical information via a topology-based approach
Oct 19, 2021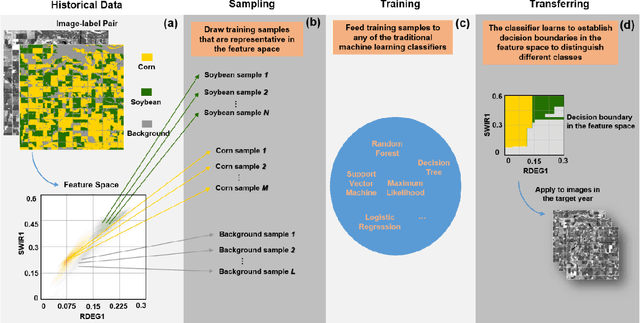

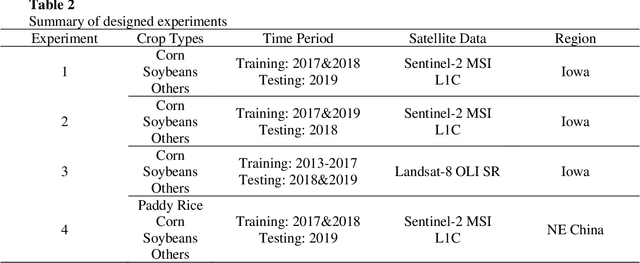
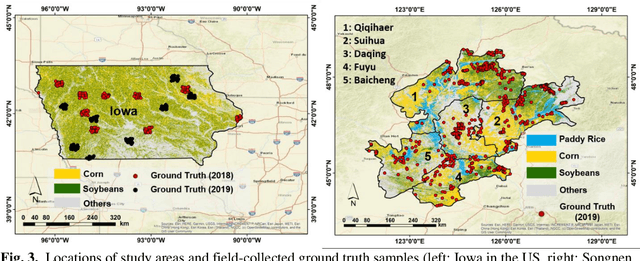
Land cover classification in remote sensing is often faced with the challenge of limited ground truth. Incorporating historical information has the potential to significantly lower the expensive cost associated with collecting ground truth and, more importantly, enable early- and in-season mapping that is helpful to many pre-harvest decisions. In this study, we propose a new approach that can effectively transfer knowledge about the topology (i.e. relative position) of different crop types in the spectral feature space (e.g. the histogram of SWIR1 vs RDEG1 bands) to generate labels, thereby support crop classification in a different year. Importantly, our approach does not attempt to transfer classification decision boundaries that are susceptible to inter-annual variations of weather and management, but relies on the more robust and shift-invariant topology information. We tested this approach for mapping corn/soybeans in the US Midwest and paddy rice/corn/soybeans in Northeast China using Landsat-8 and Sentinel-2 data. Results show that our approach automatically generates high-quality labels for crops in the target year immediately after each image becomes available. Based on these generated labels from our approach, the subsequent crop type mapping using a random forest classifier reach the F1 score as high as 0.887 for corn as early as the silking stage and 0.851 for soybean as early as the flowering stage and the overall accuracy of 0.873 in Iowa. In Northeast China, F1 scores of paddy rice, corn and soybeans and the overall accuracy can exceed 0.85 two and half months ahead of harvest. Overall, these results highlight unique advantages of our approach in transferring historical knowledge and maximizing the timeliness of crop maps. Our approach supports a general paradigm shift towards learning transferrable and generalizable knowledge to facilitate land cover classification.
Clustering augmented Self-Supervised Learning: Anapplication to Land Cover Mapping
Aug 16, 2021
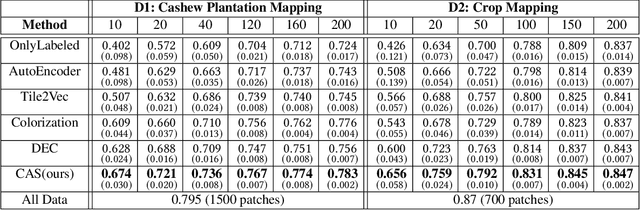
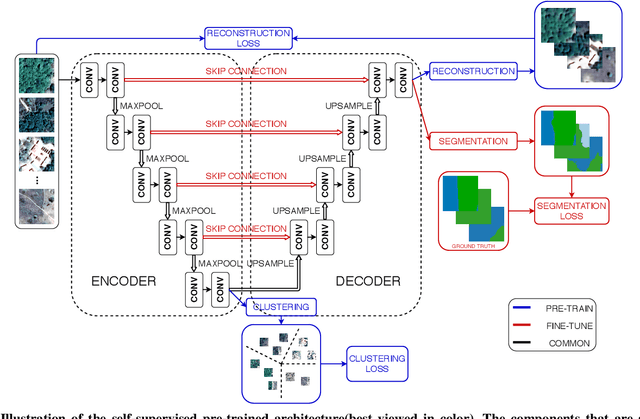

Collecting large annotated datasets in Remote Sensing is often expensive and thus can become a major obstacle for training advanced machine learning models. Common techniques of addressing this issue, based on the underlying idea of pre-training the Deep Neural Networks (DNN) on freely available large datasets, cannot be used for Remote Sensing due to the unavailability of such large-scale labeled datasets and the heterogeneity of data sources caused by the varying spatial and spectral resolution of different sensors. Self-supervised learning is an alternative approach that learns feature representation from unlabeled images without using any human annotations. In this paper, we introduce a new method for land cover mapping by using a clustering based pretext task for self-supervised learning. We demonstrate the effectiveness of the method on two societally relevant applications from the aspect of segmentation performance, discriminative feature representation learning and the underlying cluster structure. We also show the effectiveness of the active sampling using the clusters obtained from our method in improving the mapping accuracy given a limited budget of annotating.
Attention-augmented Spatio-Temporal Segmentation for Land Cover Mapping
May 02, 2021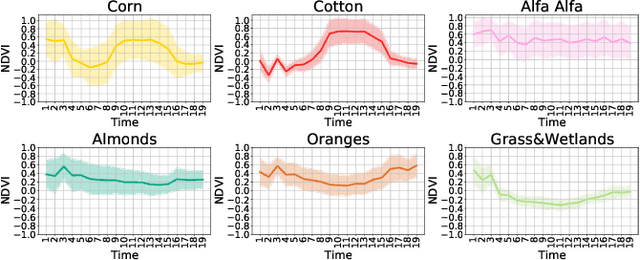
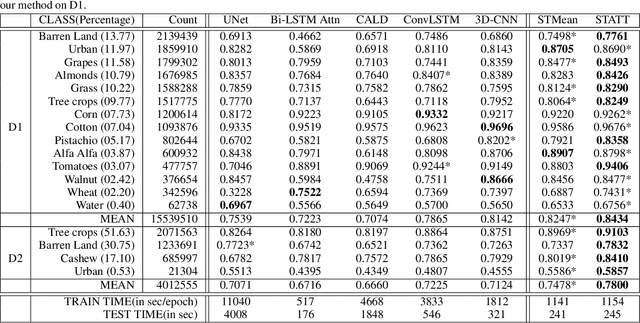
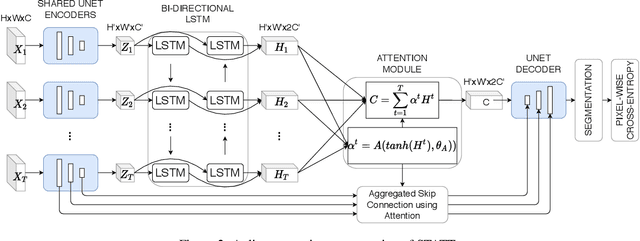
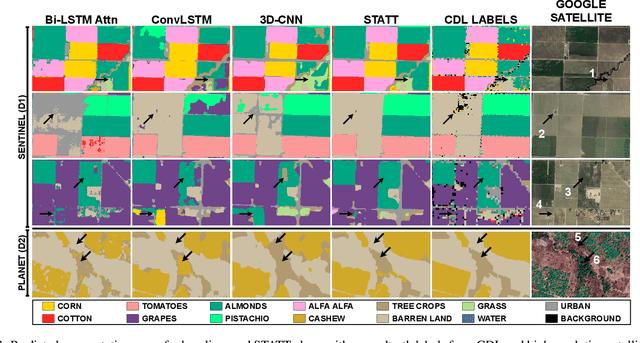
The availability of massive earth observing satellite data provide huge opportunities for land use and land cover mapping. However, such mapping effort is challenging due to the existence of various land cover classes, noisy data, and the lack of proper labels. Also, each land cover class typically has its own unique temporal pattern and can be identified only during certain periods. In this article, we introduce a novel architecture that incorporates the UNet structure with Bidirectional LSTM and Attention mechanism to jointly exploit the spatial and temporal nature of satellite data and to better identify the unique temporal patterns of each land cover. We evaluate this method for mapping crops in multiple regions over the world. We compare our method with other state-of-the-art methods both quantitatively and qualitatively on two real-world datasets which involve multiple land cover classes. We also visualise the attention weights to study its effectiveness in mitigating noise and identifying discriminative time period.