 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTReasoner: Empowering LLMs for Spatio-Temporal Reasoning in Time Series via Spatial-Aware Reinforcement Learning
Jan 06, 2026Spatio-temporal reasoning in time series involves the explicit synthesis of temporal dynamics, spatial dependencies, and textual context. This capability is vital for high-stakes decision-making in systems such as traffic networks, power grids, and disease propagation. However, the field remains underdeveloped because most existing works prioritize predictive accuracy over reasoning. To address the gap, we introduce ST-Bench, a benchmark consisting of four core tasks, including etiological reasoning, entity identification, correlation reasoning, and in-context forecasting, developed via a network SDE-based multi-agent data synthesis pipeline. We then propose STReasoner, which empowers LLM to integrate time series, graph structure, and text for explicit reasoning. To promote spatially grounded logic, we introduce S-GRPO, a reinforcement learning algorithm that rewards performance gains specifically attributable to spatial information. Experiments show that STReasoner achieves average accuracy gains between 17% and 135% at only 0.004X the cost of proprietary models and generalizes robustly to real-world data.
Can Large Language Models Adequately Perform Symbolic Reasoning Over Time Series?
Aug 05, 2025Uncovering hidden symbolic laws from time series data, as an aspiration dating back to Kepler's discovery of planetary motion, remains a core challenge in scientific discovery and artificial intelligence. While Large Language Models show promise in structured reasoning tasks, their ability to infer interpretable, context-aligned symbolic structures from time series data is still underexplored. To systematically evaluate this capability, we introduce SymbolBench, a comprehensive benchmark designed to assess symbolic reasoning over real-world time series across three tasks: multivariate symbolic regression, Boolean network inference, and causal discovery. Unlike prior efforts limited to simple algebraic equations, SymbolBench spans a diverse set of symbolic forms with varying complexity. We further propose a unified framework that integrates LLMs with genetic programming to form a closed-loop symbolic reasoning system, where LLMs act both as predictors and evaluators. Our empirical results reveal key strengths and limitations of current models, highlighting the importance of combining domain knowledge, context alignment, and reasoning structure to improve LLMs in automated scientific discovery.
TimeRecipe: A Time-Series Forecasting Recipe via Benchmarking Module Level Effectiveness
Jun 06, 2025Time-series forecasting is an essential task with wide real-world applications across domains. While recent advances in deep learning have enabled time-series forecasting models with accurate predictions, there remains considerable debate over which architectures and design components, such as series decomposition or normalization, are most effective under varying conditions. Existing benchmarks primarily evaluate models at a high level, offering limited insight into why certain designs work better. To mitigate this gap, we propose TimeRecipe, a unified benchmarking framework that systematically evaluates time-series forecasting methods at the module level. TimeRecipe conducts over 10,000 experiments to assess the effectiveness of individual components across a diverse range of datasets, forecasting horizons, and task settings. Our results reveal that exhaustive exploration of the design space can yield models that outperform existing state-of-the-art methods and uncover meaningful intuitions linking specific design choices to forecasting scenarios. Furthermore, we release a practical toolkit within TimeRecipe that recommends suitable model architectures based on these empirical insights. The benchmark is available at: https://github.com/AdityaLab/TimeRecipe.
Scalable Graph Condensation with Evolving Capabilities
Feb 24, 2025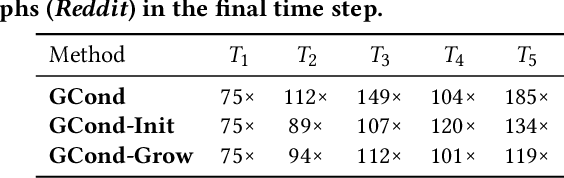
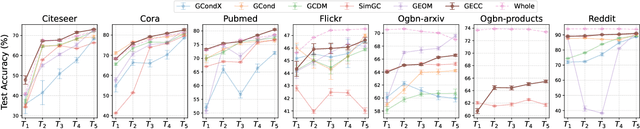
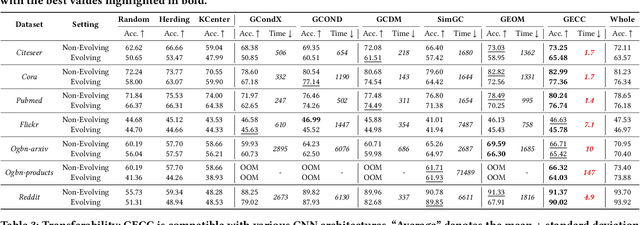
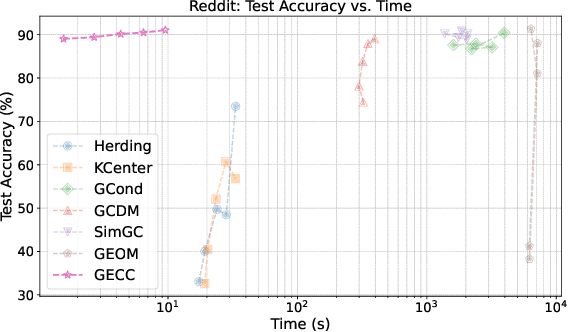
Graph data has become a pivotal modality due to its unique ability to model relational datasets. However, real-world graph data continues to grow exponentially, resulting in a quadratic increase in the complexity of most graph algorithms as graph sizes expand. Although graph condensation (GC) methods have been proposed to address these scalability issues, existing approaches often treat the training set as static, overlooking the evolving nature of real-world graph data. This limitation leads to inefficiencies when condensing growing training sets. In this paper, we introduce GECC (Graph Evolving Clustering Condensation), a scalable graph condensation method designed to handle large-scale and evolving graph data. GECC employs a traceable and efficient approach by performing class-wise clustering on aggregated features. Furthermore, it can inherits previous condensation results as clustering centroids when the condensed graph expands, thereby attaining an evolving capability. This methodology is supported by robust theoretical foundations and demonstrates superior empirical performance. Comprehensive experiments show that GECC achieves better performance than most state-of-the-art graph condensation methods while delivering an around 1,000x speedup on large datasets.
TimeDistill: Efficient Long-Term Time Series Forecasting with MLP via Cross-Architecture Distillation
Feb 20, 2025Transformer-based and CNN-based methods demonstrate strong performance in long-term time series forecasting. However, their high computational and storage requirements can hinder large-scale deployment. To address this limitation, we propose integrating lightweight MLP with advanced architectures using knowledge distillation (KD). Our preliminary study reveals different models can capture complementary patterns, particularly multi-scale and multi-period patterns in the temporal and frequency domains. Based on this observation, we introduce TimeDistill, a cross-architecture KD framework that transfers these patterns from teacher models (e.g., Transformers, CNNs) to MLP. Additionally, we provide a theoretical analysis, demonstrating that our KD approach can be interpreted as a specialized form of mixup data augmentation. TimeDistill improves MLP performance by up to 18.6%, surpassing teacher models on eight datasets. It also achieves up to 7X faster inference and requires 130X fewer parameters. Furthermore, we conduct extensive evaluations to highlight the versatility and effectiveness of TimeDistill.
CAPE: Covariate-Adjusted Pre-Training for Epidemic Time Series Forecasting
Feb 05, 2025



Accurate forecasting of epidemic infection trajectories is crucial for safeguarding public health. However, limited data availability during emerging outbreaks and the complex interaction between environmental factors and disease dynamics present significant challenges for effective forecasting. In response, we introduce CAPE, a novel epidemic pre-training framework designed to harness extensive disease datasets from diverse regions and integrate environmental factors directly into the modeling process for more informed decision-making on downstream diseases. Based on a covariate adjustment framework, CAPE utilizes pre-training combined with hierarchical environment contrasting to identify universal patterns across diseases while estimating latent environmental influences. We have compiled a diverse collection of epidemic time series datasets and validated the effectiveness of CAPE under various evaluation scenarios, including full-shot, few-shot, zero-shot, cross-location, and cross-disease settings, where it outperforms the leading baseline by an average of 9.9% in full-shot and 14.3% in zero-shot settings. The code will be released upon acceptance.
GC-Bench: A Benchmark Framework for Graph Condensation with New Insights
Jun 24, 2024



Graph condensation (GC) is an emerging technique designed to learn a significantly smaller graph that retains the essential information of the original graph. This condensed graph has shown promise in accelerating graph neural networks while preserving performance comparable to those achieved with the original, larger graphs. Additionally, this technique facilitates downstream applications such as neural architecture search and enhances our understanding of redundancy in large graphs. Despite the rapid development of GC methods, a systematic evaluation framework remains absent, which is necessary to clarify the critical designs for particular evaluative aspects. Furthermore, several meaningful questions have not been investigated, such as whether GC inherently preserves certain graph properties and offers robustness even without targeted design efforts. In this paper, we introduce GC-Bench, a comprehensive framework to evaluate recent GC methods across multiple dimensions and to generate new insights. Our experimental findings provide a deeper insights into the GC process and the characteristics of condensed graphs, guiding future efforts in enhancing performance and exploring new applications. Our code is available at \url{https://github.com/Emory-Melody/GraphSlim/tree/main/benchmark}.
A Comprehensive Survey on Graph Reduction: Sparsification, Coarsening, and Condensation
Feb 07, 2024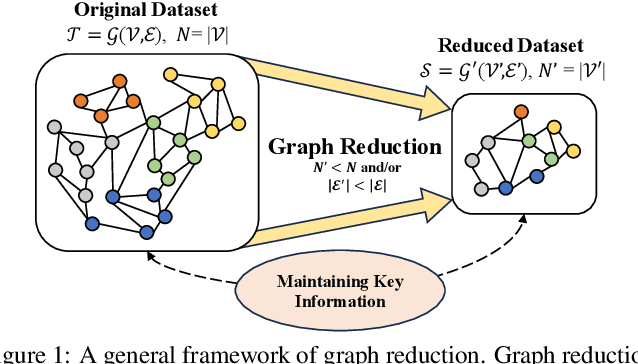

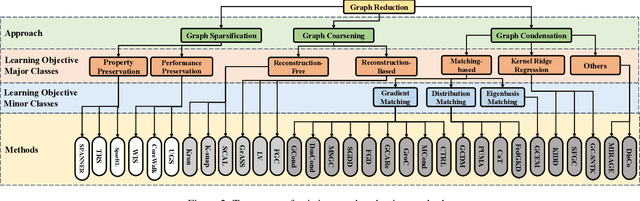

Many real-world datasets can be naturally represented as graphs, spanning a wide range of domains. However, the increasing complexity and size of graph datasets present significant challenges for analysis and computation. In response, graph reduction techniques have gained prominence for simplifying large graphs while preserving essential properties. In this survey, we aim to provide a comprehensive understanding of graph reduction methods, including graph sparsification, graph coarsening, and graph condensation. Specifically, we establish a unified definition for these methods and introduce a hierarchical taxonomy to categorize the challenges they address. Our survey then systematically reviews the technical details of these methods and emphasizes their practical applications across diverse scenarios. Furthermore, we outline critical research directions to ensure the continued effectiveness of graph reduction techniques, as well as provide a comprehensive paper list at https://github.com/ChandlerBang/awesome-graph-reduction. We hope this survey will bridge literature gaps and propel the advancement of this promising field.
FREE: The Foundational Semantic Recognition for Modeling Environmental Ecosystems
Nov 17, 2023Modeling environmental ecosystems is critical for the sustainability of our planet, but is extremely challenging due to the complex underlying processes driven by interactions amongst a large number of physical variables. As many variables are difficult to measure at large scales, existing works often utilize a combination of observable features and locally available measurements or modeled values as input to build models for a specific study region and time period. This raises a fundamental question in advancing the modeling of environmental ecosystems: how to build a general framework for modeling the complex relationships amongst various environmental data over space and time? In this paper, we introduce a new framework, FREE, which maps available environmental data into a text space and then converts the traditional predictive modeling task in environmental science to the semantic recognition problem. The proposed FREE framework leverages recent advances in Large Language Models (LLMs) to supplement the original input features with natural language descriptions. This facilitates capturing the data semantics and also allows harnessing the irregularities of input features. When used for long-term prediction, FREE has the flexibility to incorporate newly collected observations to enhance future prediction. The efficacy of FREE is evaluated in the context of two societally important real-world applications, predicting stream water temperature in the Delaware River Basin and predicting annual corn yield in Illinois and Iowa. Beyond the superior predictive performance over multiple baseline methods, FREE is shown to be more data- and computation-efficient as it can be pre-trained on simulated data generated by physics-based models.
Ever: Mitigating Hallucination in Large Language Models through Real-Time Verification and Rectification
Nov 15, 2023



Large Language Models (LLMs) have demonstrated remarkable proficiency in generating fluent text. However, they often encounter the challenge of generating inaccurate or hallucinated content. This issue is common in both non-retrieval-based generation and retrieval-augmented generation approaches, and existing post-hoc rectification methods may not address the accumulated hallucination errors that may be caused by the "snowballing" issue, especially in reasoning tasks. To tackle these challenges, we introduce a novel approach called Real-time Verification and Rectification (Ever). Instead of waiting until the end of the generation process to rectify hallucinations, Ever employs a real-time, step-wise generation and hallucination rectification strategy. The primary objective is to detect and rectify hallucinations as they occur during the text generation process. When compared to both retrieval-based and non-retrieval-based baselines, Ever demonstrates a significant improvement in generating trustworthy and factually accurate text across a diverse range of tasks, including short-form QA, biography generation, and multi-hop reasoning.