 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFutureX-Pro: Extending Future Prediction to High-Value Vertical Domains
Jan 18, 2026Building upon FutureX, which established a live benchmark for general-purpose future prediction, this report introduces FutureX-Pro, including FutureX-Finance, FutureX-Retail, FutureX-PublicHealth, FutureX-NaturalDisaster, and FutureX-Search. These together form a specialized framework extending agentic future prediction to high-value vertical domains. While generalist agents demonstrate proficiency in open-domain search, their reliability in capital-intensive and safety-critical sectors remains under-explored. FutureX-Pro targets four economically and socially pivotal verticals: Finance, Retail, Public Health, and Natural Disaster. We benchmark agentic Large Language Models (LLMs) on entry-level yet foundational prediction tasks -- ranging from forecasting market indicators and supply chain demands to tracking epidemic trends and natural disasters. By adapting the contamination-free, live-evaluation pipeline of FutureX, we assess whether current State-of-the-Art (SOTA) agentic LLMs possess the domain grounding necessary for industrial deployment. Our findings reveal the performance gap between generalist reasoning and the precision required for high-value vertical applications.
TimeRecipe: A Time-Series Forecasting Recipe via Benchmarking Module Level Effectiveness
Jun 06, 2025Time-series forecasting is an essential task with wide real-world applications across domains. While recent advances in deep learning have enabled time-series forecasting models with accurate predictions, there remains considerable debate over which architectures and design components, such as series decomposition or normalization, are most effective under varying conditions. Existing benchmarks primarily evaluate models at a high level, offering limited insight into why certain designs work better. To mitigate this gap, we propose TimeRecipe, a unified benchmarking framework that systematically evaluates time-series forecasting methods at the module level. TimeRecipe conducts over 10,000 experiments to assess the effectiveness of individual components across a diverse range of datasets, forecasting horizons, and task settings. Our results reveal that exhaustive exploration of the design space can yield models that outperform existing state-of-the-art methods and uncover meaningful intuitions linking specific design choices to forecasting scenarios. Furthermore, we release a practical toolkit within TimeRecipe that recommends suitable model architectures based on these empirical insights. The benchmark is available at: https://github.com/AdityaLab/TimeRecipe.
How Can Time Series Analysis Benefit From Multiple Modalities? A Survey and Outlook
Mar 14, 2025Time series analysis (TSA) is a longstanding research topic in the data mining community and has wide real-world significance. Compared to "richer" modalities such as language and vision, which have recently experienced explosive development and are densely connected, the time-series modality remains relatively underexplored and isolated. We notice that many recent TSA works have formed a new research field, i.e., Multiple Modalities for TSA (MM4TSA). In general, these MM4TSA works follow a common motivation: how TSA can benefit from multiple modalities. This survey is the first to offer a comprehensive review and a detailed outlook for this emerging field. Specifically, we systematically discuss three benefits: (1) reusing foundation models of other modalities for efficient TSA, (2) multimodal extension for enhanced TSA, and (3) cross-modality interaction for advanced TSA. We further group the works by the introduced modality type, including text, images, audio, tables, and others, within each perspective. Finally, we identify the gaps with future opportunities, including the reused modalities selections, heterogeneous modality combinations, and unseen tasks generalizations, corresponding to the three benefits. We release an up-to-date GitHub repository that includes key papers and resources.
A Picture is Worth A Thousand Numbers: Enabling LLMs Reason about Time Series via Visualization
Nov 09, 2024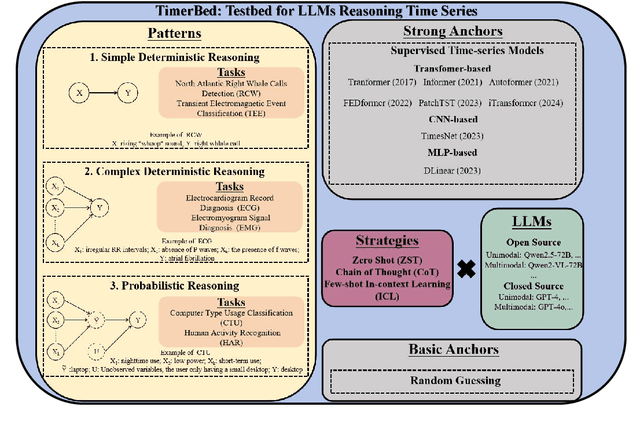
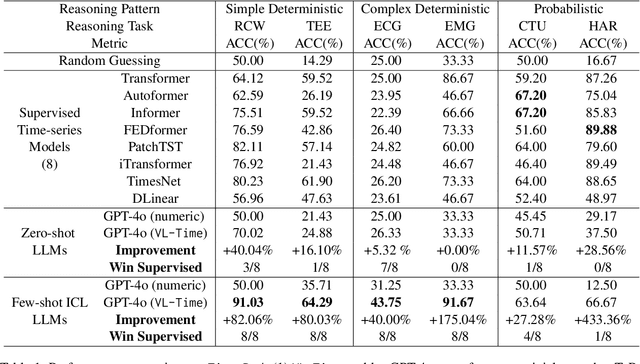
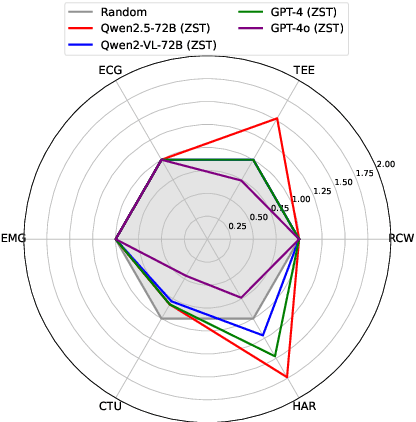

Large language models (LLMs), with demonstrated reasoning abilities across multiple domains, are largely underexplored for time-series reasoning (TsR), which is ubiquitous in the real world. In this work, we propose TimerBed, the first comprehensive testbed for evaluating LLMs' TsR performance. Specifically, TimerBed includes stratified reasoning patterns with real-world tasks, comprehensive combinations of LLMs and reasoning strategies, and various supervised models as comparison anchors. We perform extensive experiments with TimerBed, test multiple current beliefs, and verify the initial failures of LLMs in TsR, evidenced by the ineffectiveness of zero shot (ZST) and performance degradation of few shot in-context learning (ICL). Further, we identify one possible root cause: the numerical modeling of data. To address this, we propose a prompt-based solution VL-Time, using visualization-modeled data and language-guided reasoning. Experimental results demonstrate that Vl-Time enables multimodal LLMs to be non-trivial ZST and powerful ICL reasoners for time series, achieving about 140% average performance improvement and 99% average token costs reduction.
Just Propagate: Unifying Matrix Factorization, Network Embedding, and LightGCN for Link Prediction
Oct 26, 2024Link prediction is a fundamental task in graph analysis. Despite the success of various graph-based machine learning models for link prediction, there lacks a general understanding of different models. In this paper, we propose a unified framework for link prediction that covers matrix factorization and representative network embedding and graph neural network methods. Our preliminary methodological and empirical analyses further reveal several key design factors based on our unified framework. We believe our results could deepen our understanding and inspire novel designs for link prediction methods.
TSI-Bench: Benchmarking Time Series Imputation
Jun 18, 2024Effective imputation is a crucial preprocessing step for time series analysis. Despite the development of numerous deep learning algorithms for time series imputation, the community lacks standardized and comprehensive benchmark platforms to effectively evaluate imputation performance across different settings. Moreover, although many deep learning forecasting algorithms have demonstrated excellent performance, whether their modeling achievements can be transferred to time series imputation tasks remains unexplored. To bridge these gaps, we develop TSI-Bench, the first (to our knowledge) comprehensive benchmark suite for time series imputation utilizing deep learning techniques. The TSI-Bench pipeline standardizes experimental settings to enable fair evaluation of imputation algorithms and identification of meaningful insights into the influence of domain-appropriate missingness ratios and patterns on model performance. Furthermore, TSI-Bench innovatively provides a systematic paradigm to tailor time series forecasting algorithms for imputation purposes. Our extensive study across 34,804 experiments, 28 algorithms, and 8 datasets with diverse missingness scenarios demonstrates TSI-Bench's effectiveness in diverse downstream tasks and potential to unlock future directions in time series imputation research and analysis. The source code and experiment logs are available at https://github.com/WenjieDu/AwesomeImputation.
Time-Series Forecasting for Out-of-Distribution Generalization Using Invariant Learning
Jun 13, 2024Time-series forecasting (TSF) finds broad applications in real-world scenarios. Due to the dynamic nature of time-series data, it is crucial to equip TSF models with out-of-distribution (OOD) generalization abilities, as historical training data and future test data can have different distributions. In this paper, we aim to alleviate the inherent OOD problem in TSF via invariant learning. We identify fundamental challenges of invariant learning for TSF. First, the target variables in TSF may not be sufficiently determined by the input due to unobserved core variables in TSF, breaking the conventional assumption of invariant learning. Second, time-series datasets lack adequate environment labels, while existing environmental inference methods are not suitable for TSF. To address these challenges, we propose FOIL, a model-agnostic framework that enables timeseries Forecasting for Out-of-distribution generalization via Invariant Learning. FOIL employs a novel surrogate loss to mitigate the impact of unobserved variables. Further, FOIL implements a joint optimization by alternately inferring environments effectively with a multi-head network while preserving the temporal adjacency structure, and learning invariant representations across inferred environments for OOD generalized TSF. We demonstrate that the proposed FOIL significantly improves the performance of various TSF models, achieving gains of up to 85%.
Time-MMD: A New Multi-Domain Multimodal Dataset for Time Series Analysis
Jun 12, 2024



Time series data are ubiquitous across a wide range of real-world domains. While real-world time series analysis (TSA) requires human experts to integrate numerical series data with multimodal domain-specific knowledge, most existing TSA models rely solely on numerical data, overlooking the significance of information beyond numerical series. This oversight is due to the untapped potential of textual series data and the absence of a comprehensive, high-quality multimodal dataset. To overcome this obstacle, we introduce Time-MMD, the first multi-domain, multimodal time series dataset covering 9 primary data domains. Time-MMD ensures fine-grained modality alignment, eliminates data contamination, and provides high usability. Additionally, we develop MM-TSFlib, the first multimodal time-series forecasting (TSF) library, seamlessly pipelining multimodal TSF evaluations based on Time-MMD for in-depth analyses. Extensive experiments conducted on Time-MMD through MM-TSFlib demonstrate significant performance enhancements by extending unimodal TSF to multimodality, evidenced by over 15% mean squared error reduction in general, and up to 40% in domains with rich textual data. More importantly, our datasets and library revolutionize broader applications, impacts, research topics to advance TSA. The dataset and library are available at https://github.com/AdityaLab/Time-MMD and https://github.com/AdityaLab/MM-TSFlib.
LSTPrompt: Large Language Models as Zero-Shot Time Series Forecasters by Long-Short-Term Prompting
Feb 25, 2024



Time-series forecasting (TSF) finds broad applications in real-world scenarios. Prompting off-the-shelf Large Language Models (LLMs) demonstrates strong zero-shot TSF capabilities while preserving computational efficiency. However, existing prompting methods oversimplify TSF as language next-token predictions, overlooking its dynamic nature and lack of integration with state-of-the-art prompt strategies such as Chain-of-Thought. Thus, we propose LSTPrompt, a novel approach for prompting LLMs in zero-shot TSF tasks. LSTPrompt decomposes TSF into short-term and long-term forecasting sub-tasks, tailoring prompts to each. LSTPrompt guides LLMs to regularly reassess forecasting mechanisms to enhance adaptability. Extensive evaluations demonstrate consistently better performance of LSTPrompt than existing prompting methods, and competitive results compared to foundation TSF models.
Few-Shot Learning for Chronic Disease Management: Leveraging Large Language Models and Multi-Prompt Engineering with Medical Knowledge Injection
Jan 16, 2024This study harnesses state-of-the-art AI technology for chronic disease management, specifically in detecting various mental disorders through user-generated textual content. Existing studies typically rely on fully supervised machine learning, which presents challenges such as the labor-intensive manual process of annotating extensive training data for each disease and the need to design specialized deep learning architectures for each problem. To address such challenges, we propose a novel framework that leverages advanced AI techniques, including large language models and multi-prompt engineering. Specifically, we address two key technical challenges in data-driven chronic disease management: (1) developing personalized prompts to represent each user's uniqueness and (2) incorporating medical knowledge into prompts to provide context for chronic disease detection, instruct learning objectives, and operationalize prediction goals. We evaluate our method using four mental disorders, which are prevalent chronic diseases worldwide, as research cases. On the depression detection task, our method (F1 = 0.975~0.978) significantly outperforms traditional supervised learning paradigms, including feature engineering (F1 = 0.760) and architecture engineering (F1 = 0.756). Meanwhile, our approach demonstrates success in few-shot learning, i.e., requiring only a minimal number of training examples to detect chronic diseases based on user-generated textual content (i.e., only 2, 10, or 100 subjects). Moreover, our method can be generalized to other mental disorder detection tasks, including anorexia, pathological gambling, and self-harm (F1 = 0.919~0.978).