 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLimiX: Unleashing Structured-Data Modeling Capability for Generalist Intelligence
Sep 03, 2025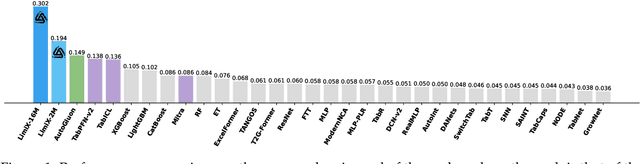
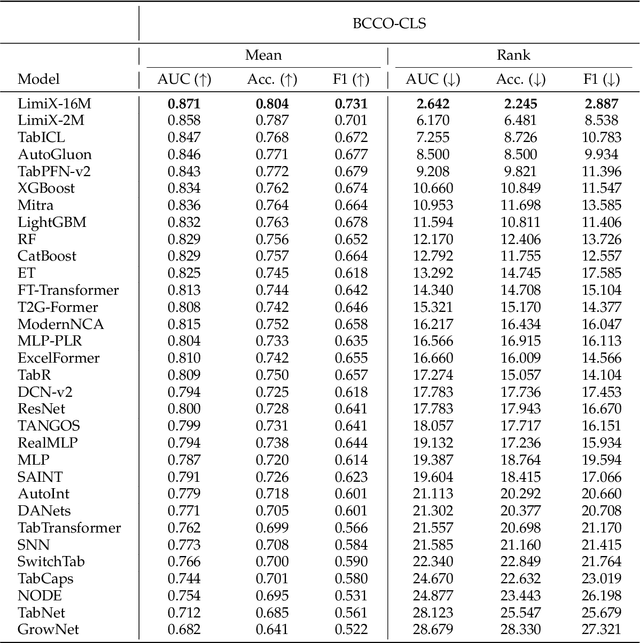
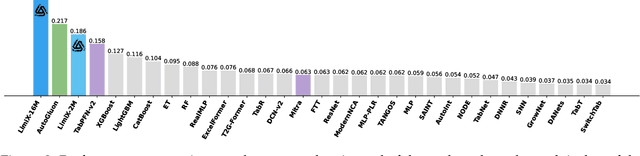
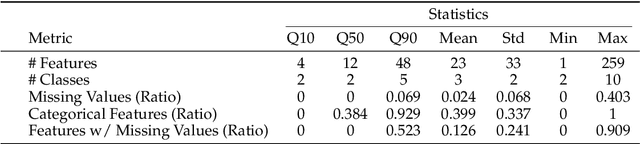
We argue that progress toward general intelligence requires complementary foundation models grounded in language, the physical world, and structured data. This report presents LimiX, the first installment of our large structured-data models (LDMs). LimiX treats structured data as a joint distribution over variables and missingness, thus capable of addressing a wide range of tabular tasks through query-based conditional prediction via a single model. LimiX is pretrained using masked joint-distribution modeling with an episodic, context-conditional objective, where the model predicts for query subsets conditioned on dataset-specific contexts, supporting rapid, training-free adaptation at inference. We evaluate LimiX across 10 large structured-data benchmarks with broad regimes of sample size, feature dimensionality, class number, categorical-to-numerical feature ratio, missingness, and sample-to-feature ratios. With a single model and a unified interface, LimiX consistently surpasses strong baselines including gradient-boosting trees, deep tabular networks, recent tabular foundation models, and automated ensembles, as shown in Figure 1 and Figure 2. The superiority holds across a wide range of tasks, such as classification, regression, missing value imputation, and data generation, often by substantial margins, while avoiding task-specific architectures or bespoke training per task. All LimiX models are publicly accessible under Apache 2.0.
Meta Adaptive Task Sampling for Few-Domain Generalization
May 25, 2023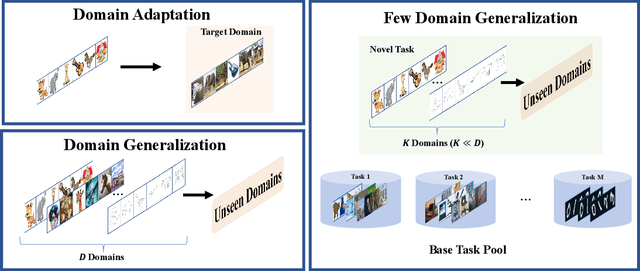


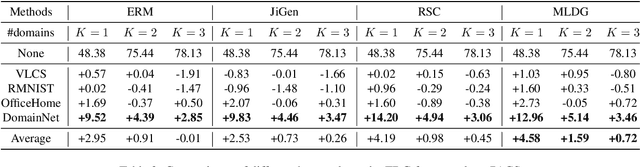
To ensure the out-of-distribution (OOD) generalization performance, traditional domain generalization (DG) methods resort to training on data from multiple sources with different underlying distributions. And the success of those DG methods largely depends on the fact that there are diverse training distributions. However, it usually needs great efforts to obtain enough heterogeneous data due to the high expenses, privacy issues or the scarcity of data. Thus an interesting yet seldom investigated problem arises: how to improve the OOD generalization performance when the perceived heterogeneity is limited. In this paper, we instantiate a new framework called few-domain generalization (FDG), which aims to learn a generalizable model from very few domains of novel tasks with the knowledge acquired from previous learning experiences on base tasks. Moreover, we propose a Meta Adaptive Task Sampling (MATS) procedure to differentiate base tasks according to their semantic and domain-shift similarity to the novel task. Empirically, we show that the newly introduced FDG framework can substantially improve the OOD generalization performance on the novel task and further combining MATS with episodic training could outperform several state-of-the-art DG baselines on widely used benchmarks like PACS and DomainNet.
A Framework for Multi-stage Bonus Allocation in meal delivery Platform
Feb 22, 2022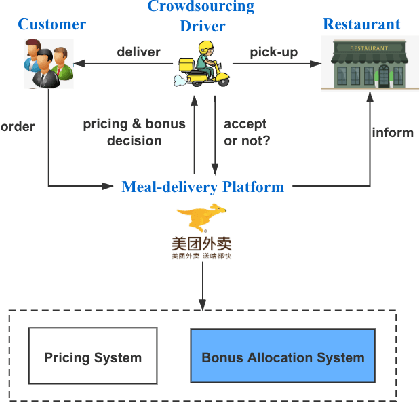

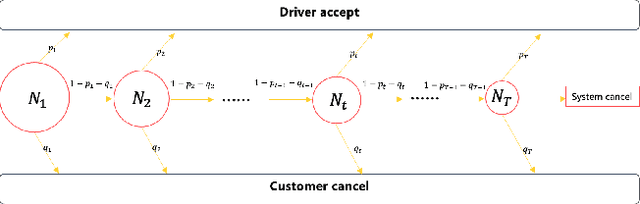
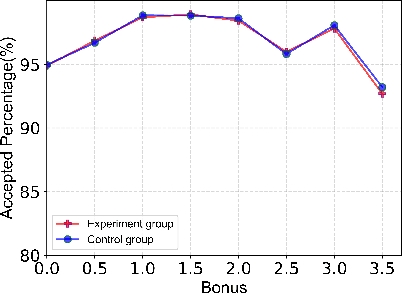
Online meal delivery is undergoing explosive growth, as this service is becoming increasingly popular. A meal delivery platform aims to provide excellent and stable services for customers and restaurants. However, in reality, several hundred thousand orders are canceled per day in the Meituan meal delivery platform since they are not accepted by the crowd soucing drivers. The cancellation of the orders is incredibly detrimental to the customer's repurchase rate and the reputation of the Meituan meal delivery platform. To solve this problem, a certain amount of specific funds is provided by Meituan's business managers to encourage the crowdsourcing drivers to accept more orders. To make better use of the funds, in this work, we propose a framework to deal with the multi-stage bonus allocation problem for a meal delivery platform. The objective of this framework is to maximize the number of accepted orders within a limited bonus budget. This framework consists of a semi-black-box acceptance probability model, a Lagrangian dual-based dynamic programming algorithm, and an online allocation algorithm. The semi-black-box acceptance probability model is employed to forecast the relationship between the bonus allocated to order and its acceptance probability, the Lagrangian dual-based dynamic programming algorithm aims to calculate the empirical Lagrangian multiplier for each allocation stage offline based on the historical data set, and the online allocation algorithm uses the results attained in the offline part to calculate a proper delivery bonus for each order. To verify the effectiveness and efficiency of our framework, both offline experiments on a real-world data set and online A/B tests on the Meituan meal delivery platform are conducted. Our results show that using the proposed framework, the total order cancellations can be decreased by more than 25\% in reality.
Domain-Irrelevant Representation Learning for Unsupervised Domain Generalization
Jul 13, 2021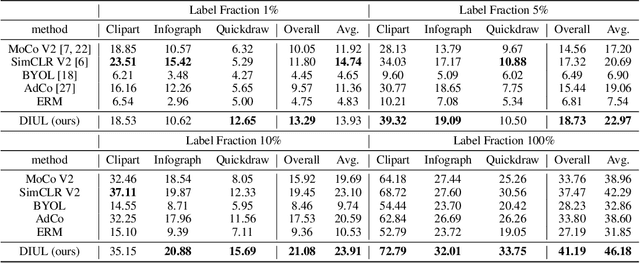
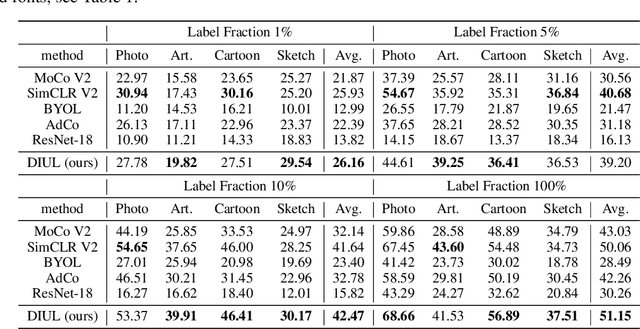
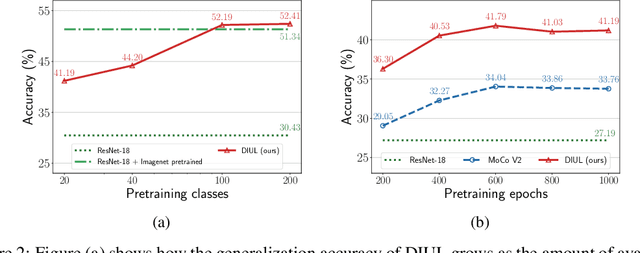
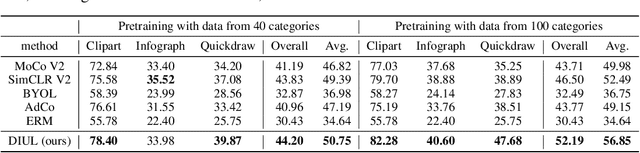
Domain generalization (DG) aims to help models trained on a set of source domains generalize better on unseen target domains. The performances of current DG methods largely rely on sufficient labeled data, which however are usually costly or unavailable. While unlabeled data are far more accessible, we seek to explore how unsupervised learning can help deep models generalizes across domains. Specifically, we study a novel generalization problem called unsupervised domain generalization, which aims to learn generalizable models with unlabeled data. Furthermore, we propose a Domain-Irrelevant Unsupervised Learning (DIUL) method to cope with the significant and misleading heterogeneity within unlabeled data and severe distribution shifts between source and target data. Surprisingly we observe that DIUL can not only counterbalance the scarcity of labeled data but also further strengthen the generalization ability of models when the labeled data are sufficient. As a pretraining approach, DIUL shows superior to ImageNet pretraining protocol even when the available data are unlabeled and of a greatly smaller amount compared to ImageNet. Extensive experiments clearly demonstrate the effectiveness of our method compared with state-of-the-art unsupervised learning counterparts.
Distributionally Robust Learning with Stable Adversarial Training
Jun 30, 2021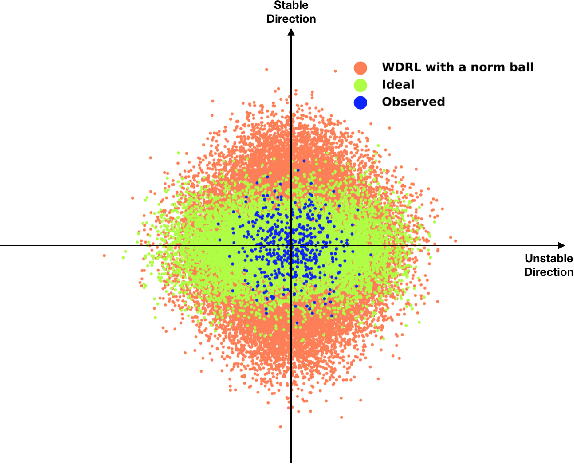
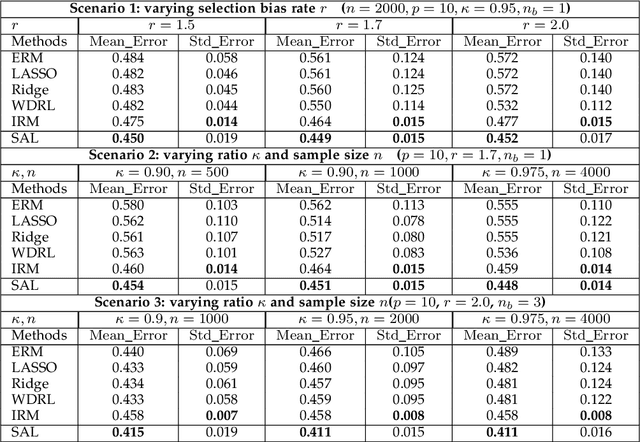
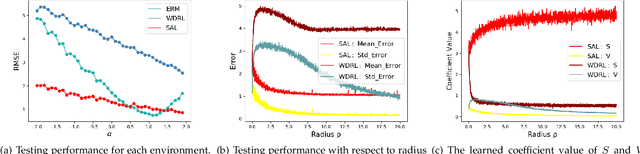
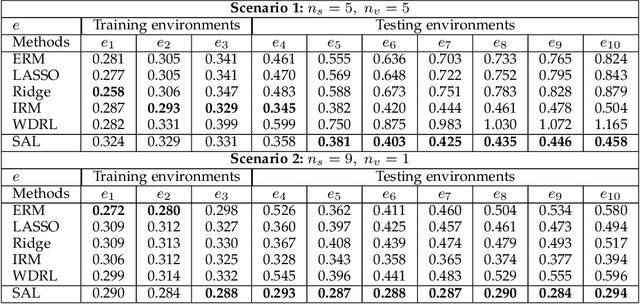
Machine learning algorithms with empirical risk minimization are vulnerable under distributional shifts due to the greedy adoption of all the correlations found in training data. There is an emerging literature on tackling this problem by minimizing the worst-case risk over an uncertainty set. However, existing methods mostly construct ambiguity sets by treating all variables equally regardless of the stability of their correlations with the target, resulting in the overwhelmingly-large uncertainty set and low confidence of the learner. In this paper, we propose a novel Stable Adversarial Learning (SAL) algorithm that leverages heterogeneous data sources to construct a more practical uncertainty set and conduct differentiated robustness optimization, where covariates are differentiated according to the stability of their correlations with the target. We theoretically show that our method is tractable for stochastic gradient-based optimization and provide the performance guarantees for our method. Empirical studies on both simulation and real datasets validate the effectiveness of our method in terms of uniformly good performance across unknown distributional shifts.
Deep Stable Learning for Out-Of-Distribution Generalization
Apr 16, 2021



Approaches based on deep neural networks have achieved striking performance when testing data and training data share similar distribution, but can significantly fail otherwise. Therefore, eliminating the impact of distribution shifts between training and testing data is crucial for building performance-promising deep models. Conventional methods assume either the known heterogeneity of training data (e.g. domain labels) or the approximately equal capacities of different domains. In this paper, we consider a more challenging case where neither of the above assumptions holds. We propose to address this problem by removing the dependencies between features via learning weights for training samples, which helps deep models get rid of spurious correlations and, in turn, concentrate more on the true connection between discriminative features and labels. Extensive experiments clearly demonstrate the effectiveness of our method on multiple distribution generalization benchmarks compared with state-of-the-art counterparts. Through extensive experiments on distribution generalization benchmarks including PACS, VLCS, MNIST-M, and NICO, we show the effectiveness of our method compared with state-of-the-art counterparts.
Adversarial Eigen Attack on Black-Box Models
Aug 27, 2020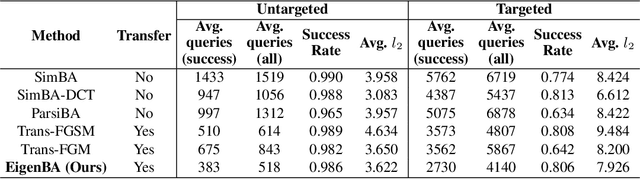



Black-box adversarial attack has attracted a lot of research interests for its practical use in AI safety. Compared with the white-box attack, a black-box setting is more difficult for less available information related to the attacked model and the additional constraint on the query budget. A general way to improve the attack efficiency is to draw support from a pre-trained transferable white-box model. In this paper, we propose a novel setting of transferable black-box attack: attackers may use external information from a pre-trained model with available network parameters, however, different from previous studies, no additional training data is permitted to further change or tune the pre-trained model. To this end, we further propose a new algorithm, EigenBA to tackle this problem. Our method aims to explore more gradient information of the black-box model, and promote the attack efficiency, while keeping the perturbation to the original attacked image small, by leveraging the Jacobian matrix of the pre-trained white-box model. We show the optimal perturbations are closely related to the right singular vectors of the Jacobian matrix. Further experiments on ImageNet and CIFAR-10 show that even the unlearnable pre-trained white-box model could also significantly boost the efficiency of the black-box attack and our proposed method could further improve the attack efficiency.
Algorithmic Decision Making with Conditional Fairness
Jul 14, 2020

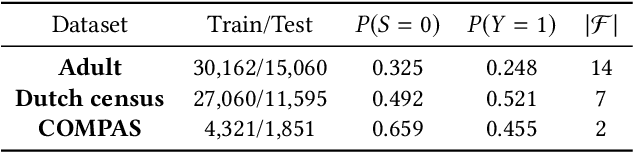
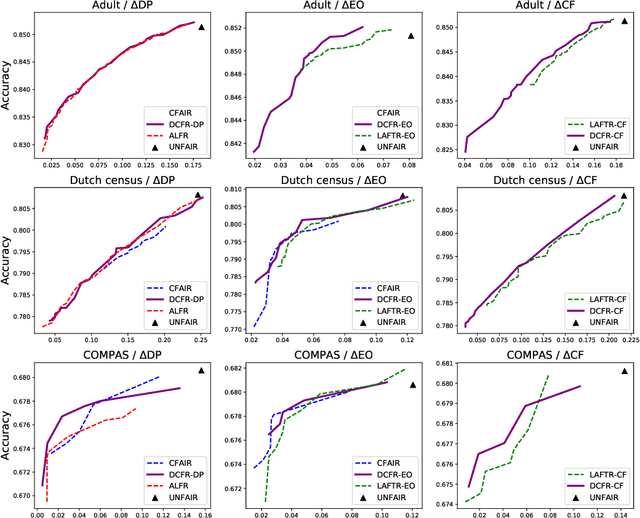
Nowadays fairness issues have raised great concerns in decision-making systems. Various fairness notions have been proposed to measure the degree to which an algorithm is unfair. In practice, there frequently exist a certain set of variables we term as fair variables, which are pre-decision covariates such as users' choices. The effects of fair variables are irrelevant in assessing the fairness of the decision support algorithm. We thus define conditional fairness as a more sound fairness metric by conditioning on the fairness variables. Given different prior knowledge of fair variables, we demonstrate that traditional fairness notations, such as demographic parity and equalized odds, are special cases of our conditional fairness notations. Moreover, we propose a Derivable Conditional Fairness Regularizer (DCFR), which can be integrated into any decision-making model, to track the trade-off between precision and fairness of algorithmic decision making. Specifically, an adversarial representation based conditional independence loss is proposed in our DCFR to measure the degree of unfairness. With extensive experiments on three real-world datasets, we demonstrate the advantages of our conditional fairness notation and DCFR.
Invariant Adversarial Learning for Distributional Robustness
Jun 08, 2020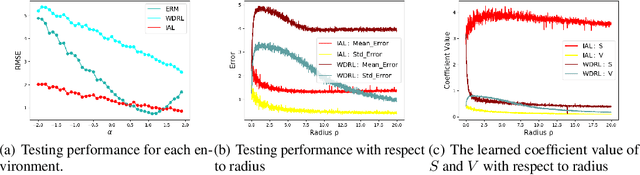
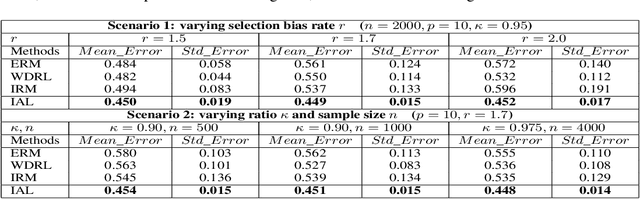
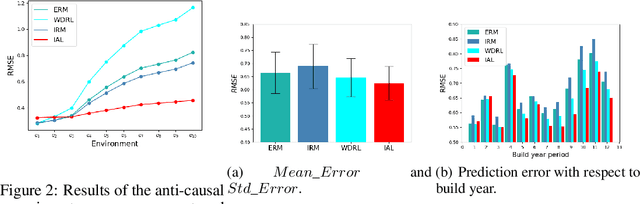
Machine learning algorithms with empirical risk minimization are vulnerable to distributional shifts due to the greedy adoption of all the correlations found in training data. Recently, there are robust learning methods aiming at this problem by minimizing the worst-case risk over an uncertainty set. However, they equally treat all covariates to form the uncertainty sets regardless of the stability of their correlations with the target, resulting in the overwhelmingly large set and low confidence of the learner. In this paper, we propose the Invariant Adversarial Learning (IAL) algorithm that leverages heterogeneous data sources to construct a more practical uncertainty set and conduct robustness optimization, where covariates are differentiated according to the stability of their correlations with the target. We theoretically show that our method is tractable for stochastic gradient-based optimization and provide the performance guarantees for our method. Empirical studies on both simulation and real datasets validate the effectiveness of our method in terms of robust performance across unknown distributional shifts.
Learning to Select Base Classes for Few-shot Classification
Apr 01, 2020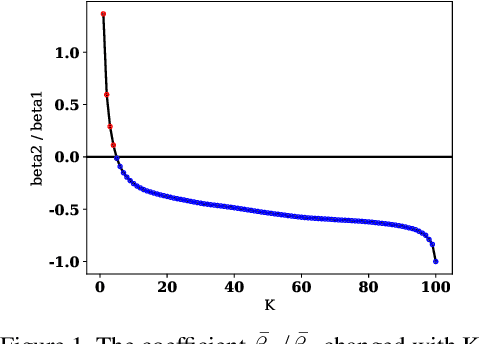

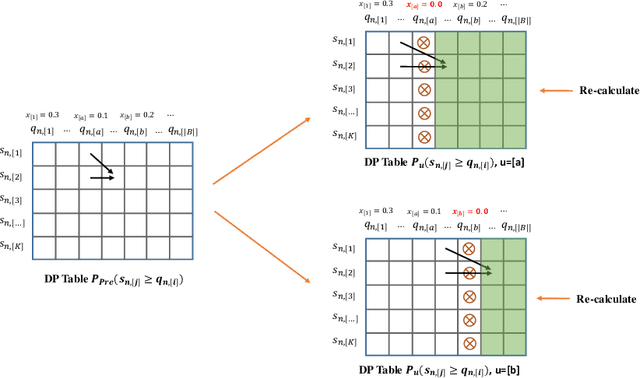
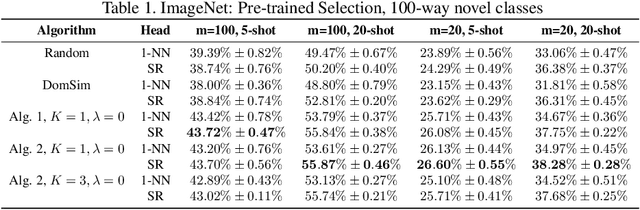
Few-shot learning has attracted intensive research attention in recent years. Many methods have been proposed to generalize a model learned from provided base classes to novel classes, but no previous work studies how to select base classes, or even whether different base classes will result in different generalization performance of the learned model. In this paper, we utilize a simple yet effective measure, the Similarity Ratio, as an indicator for the generalization performance of a few-shot model. We then formulate the base class selection problem as a submodular optimization problem over Similarity Ratio. We further provide theoretical analysis on the optimization lower bound of different optimization methods, which could be used to identify the most appropriate algorithm for different experimental settings. The extensive experiments on ImageNet, Caltech256 and CUB-200-2011 demonstrate that our proposed method is effective in selecting a better base dataset.