 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvariant Adversarial Learning for Distributional Robustness
Jun 08, 2020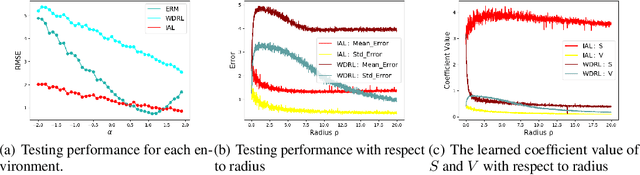
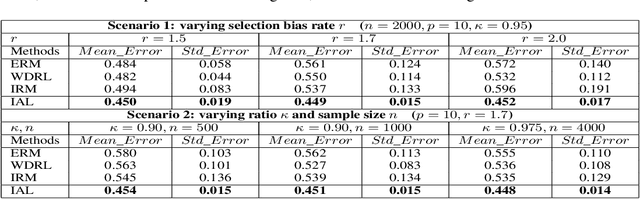
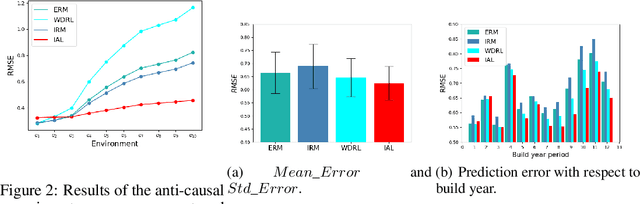
Machine learning algorithms with empirical risk minimization are vulnerable to distributional shifts due to the greedy adoption of all the correlations found in training data. Recently, there are robust learning methods aiming at this problem by minimizing the worst-case risk over an uncertainty set. However, they equally treat all covariates to form the uncertainty sets regardless of the stability of their correlations with the target, resulting in the overwhelmingly large set and low confidence of the learner. In this paper, we propose the Invariant Adversarial Learning (IAL) algorithm that leverages heterogeneous data sources to construct a more practical uncertainty set and conduct robustness optimization, where covariates are differentiated according to the stability of their correlations with the target. We theoretically show that our method is tractable for stochastic gradient-based optimization and provide the performance guarantees for our method. Empirical studies on both simulation and real datasets validate the effectiveness of our method in terms of robust performance across unknown distributional shifts.
SocialTrans: A Deep Sequential Model with Social Information for Web-Scale Recommendation Systems
May 09, 2020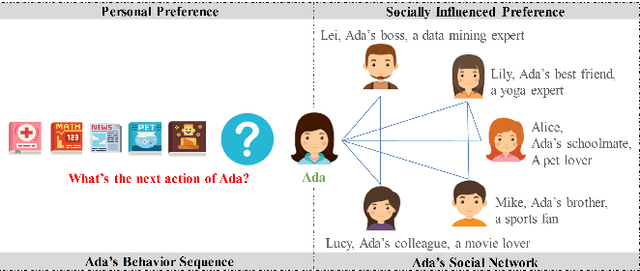
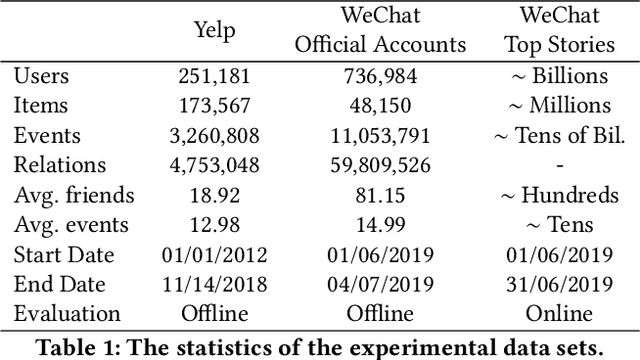
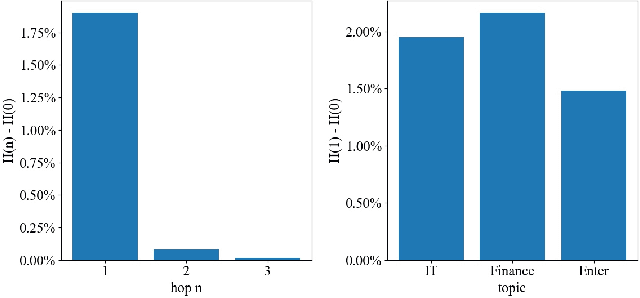
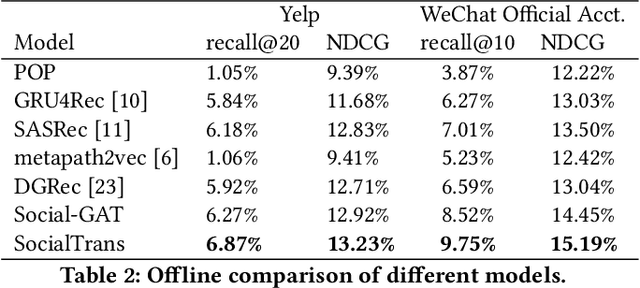
On social network platforms, a user's behavior is based on his/her personal interests, or influenced by his/her friends. In the literature, it is common to model either users' personal preference or their socially influenced preference. In this paper, we present a novel deep learning model SocialTrans for social recommendations to integrate these two types of preferences. SocialTrans is composed of three modules. The first module is based on a multi-layer Transformer to model users' personal preference. The second module is a multi-layer graph attention neural network (GAT), which is used to model the social influence strengths between friends in social networks. The last module merges users' personal preference and socially influenced preference to produce recommendations. Our model can efficiently fit large-scale data and we deployed SocialTrans to a major article recommendation system in China. Experiments on three data sets verify the effectiveness of our model and show that it outperforms state-of-the-art social recommendation methods.
Combining Offline Causal Inference and Online Bandit Learning for Data Driven Decisions
Jan 16, 2020

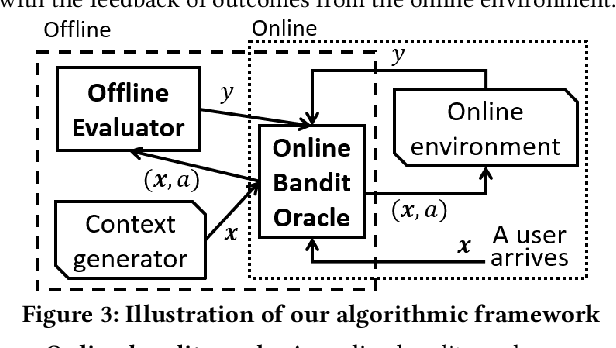
A fundamental question for companies is: How to make good decisions with the increasing amount of logged data?. Currently, companies are doing online tests (e.g. A/B tests) before making decisions. However, online tests can be expensive because testing inferior decisions hurt users' experiences. On the other hand, offline causal inference analyzes logged data alone to make decisions, but once a wrong decision is made by the offline causal inference, this wrong decision will continuously to hurt all users' experience. In this paper, we unify offline causal inference and online bandit learning to make the right decision. Our framework is flexible to incorporate various causal inference methods (e.g. matching, weighting) and online bandit methods (e.g. UCB, LinUCB). For these novel combination of algorithms, we derive theoretical bounds on the decision maker's "regret" compared to its optimal decision. We also derive the first regret bound for forest-based online bandit algorithms. Experiments on synthetic data show that our algorithms outperform methods that use only the logged data or only the online feedbacks.