 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRECISE: Pre-training Sequential Recommenders with Collaborative and Semantic Information
Dec 09, 2024Real-world recommendation systems commonly offer diverse content scenarios for users to interact with. Considering the enormous number of users in industrial platforms, it is infeasible to utilize a single unified recommendation model to meet the requirements of all scenarios. Usually, separate recommendation pipelines are established for each distinct scenario. This practice leads to challenges in comprehensively grasping users' interests. Recent research endeavors have been made to tackle this problem by pre-training models to encapsulate the overall interests of users. Traditional pre-trained recommendation models mainly capture user interests by leveraging collaborative signals. Nevertheless, a prevalent drawback of these systems is their incapacity to handle long-tail items and cold-start scenarios. With the recent advent of large language models, there has been a significant increase in research efforts focused on exploiting LLMs to extract semantic information for users and items. However, text-based recommendations highly rely on elaborate feature engineering and frequently fail to capture collaborative similarities. To overcome these limitations, we propose a novel pre-training framework for sequential recommendation, termed PRECISE. This framework combines collaborative signals with semantic information. Moreover, PRECISE employs a learning framework that initially models users' comprehensive interests across all recommendation scenarios and subsequently concentrates on the specific interests of target-scene behaviors. We demonstrate that PRECISE precisely captures the entire range of user interests and effectively transfers them to the target interests. Empirical findings reveal that the PRECISE framework attains outstanding performance on both public and industrial datasets.
Adaptive Coordinators and Prompts on Heterogeneous Graphs for Cross-Domain Recommendations
Oct 15, 2024


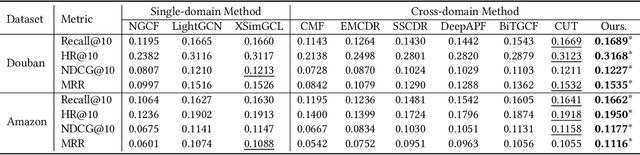
In the online digital world, users frequently engage with diverse items across multiple domains (e.g., e-commerce platforms, streaming services, and social media networks), forming complex heterogeneous interaction graphs. Leveraging this multi-domain information can undoubtedly enhance the performance of recommendation systems by providing more comprehensive user insights and alleviating data sparsity in individual domains. However, integrating multi-domain knowledge for the cross-domain recommendation is very hard due to inherent disparities in user behavior and item characteristics and the risk of negative transfer, where irrelevant or conflicting information from the source domains adversely impacts the target domain's performance. To address these challenges, we offer HAGO, a novel framework with $\textbf{H}$eterogeneous $\textbf{A}$daptive $\textbf{G}$raph co$\textbf{O}$rdinators, which dynamically integrate multi-domain graphs into a cohesive structure by adaptively adjusting the connections between coordinators and multi-domain graph nodes, thereby enhancing beneficial inter-domain interactions while mitigating negative transfer effects. Additionally, we develop a universal multi-domain graph pre-training strategy alongside HAGO to collaboratively learn high-quality node representations across domains. To effectively transfer the learned multi-domain knowledge to the target domain, we design an effective graph prompting method, which incorporates pre-trained embeddings with learnable prompts for the recommendation task. Our framework is compatible with various graph-based models and pre-training techniques, demonstrating broad applicability and effectiveness. Further experimental results show that our solutions outperform state-of-the-art methods in multi-domain recommendation scenarios and highlight their potential for real-world applications.
KELLMRec: Knowledge-Enhanced Large Language Models for Recommendation
Mar 11, 2024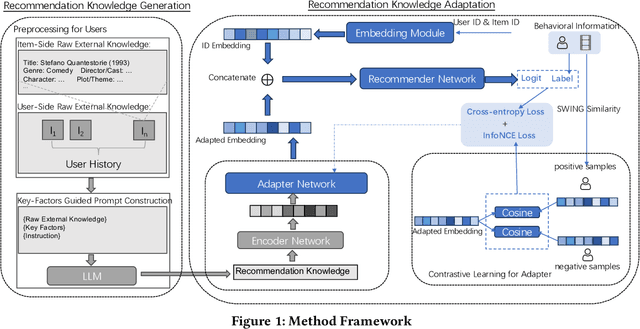


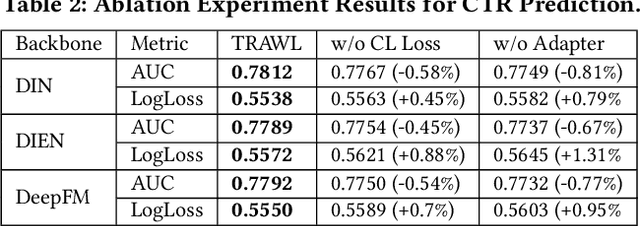
The utilization of semantic information is an important research problem in the field of recommender systems, which aims to complement the missing parts of mainstream ID-based approaches. With the rise of LLM, its ability to act as a knowledge base and its reasoning capability have opened up new possibilities for this research area, making LLM-based recommendation an emerging research direction. However, directly using LLM to process semantic information for recommendation scenarios is unreliable and sub-optimal due to several problems such as hallucination. A promising way to cope with this is to use external knowledge to aid LLM in generating truthful and usable text. Inspired by the above motivation, we propose a Knowledge-Enhanced LLMRec method. In addition to using external knowledge in prompts, the proposed method also includes a knowledge-based contrastive learning scheme for training. Experiments on public datasets and in-enterprise datasets validate the effectiveness of the proposed method.
Alleviating Video-Length Effect for Micro-video Recommendation
Aug 31, 2023

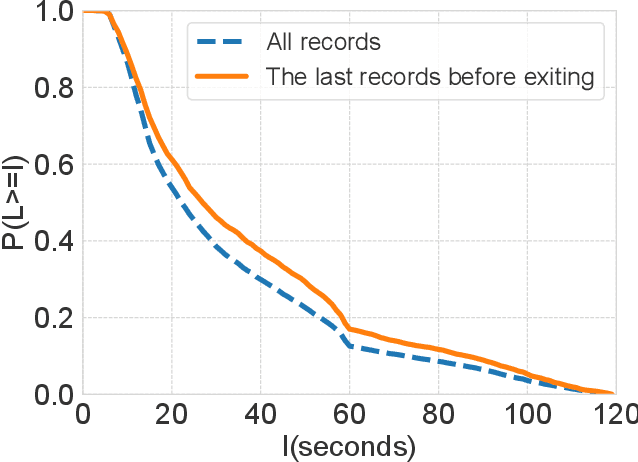
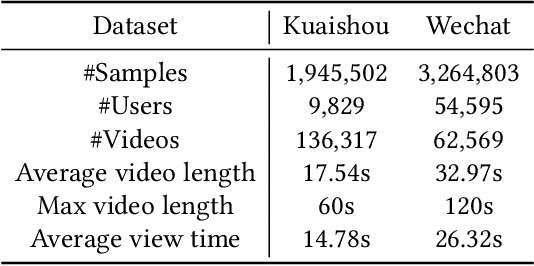
Micro-videos platforms such as TikTok are extremely popular nowadays. One important feature is that users no longer select interested videos from a set, instead they either watch the recommended video or skip to the next one. As a result, the time length of users' watching behavior becomes the most important signal for identifying preferences. However, our empirical data analysis has shown a video-length effect that long videos are easier to receive a higher value of average view time, thus adopting such view-time labels for measuring user preferences can easily induce a biased model that favors the longer videos. In this paper, we propose a Video Length Debiasing Recommendation (VLDRec) method to alleviate such an effect for micro-video recommendation. VLDRec designs the data labeling approach and the sample generation module that better capture user preferences in a view-time oriented manner. It further leverages the multi-task learning technique to jointly optimize the above samples with original biased ones. Extensive experiments show that VLDRec can improve the users' view time by 1.81% and 11.32% on two real-world datasets, given a recommendation list of a fixed overall video length, compared with the best baseline method. Moreover, VLDRec is also more effective in matching users' interests in terms of the video content.
Efficient and Joint Hyperparameter and Architecture Search for Collaborative Filtering
Jul 12, 2023



Automated Machine Learning (AutoML) techniques have recently been introduced to design Collaborative Filtering (CF) models in a data-specific manner. However, existing works either search architectures or hyperparameters while ignoring the fact they are intrinsically related and should be considered together. This motivates us to consider a joint hyperparameter and architecture search method to design CF models. However, this is not easy because of the large search space and high evaluation cost. To solve these challenges, we reduce the space by screening out usefulness yperparameter choices through a comprehensive understanding of individual hyperparameters. Next, we propose a two-stage search algorithm to find proper configurations from the reduced space. In the first stage, we leverage knowledge from subsampled datasets to reduce evaluation costs; in the second stage, we efficiently fine-tune top candidate models on the whole dataset. Extensive experiments on real-world datasets show better performance can be achieved compared with both hand-designed and previous searched models. Besides, ablation and case studies demonstrate the effectiveness of our search framework.
Robust Preference-Guided Denoising for Graph based Social Recommendation
Mar 15, 2023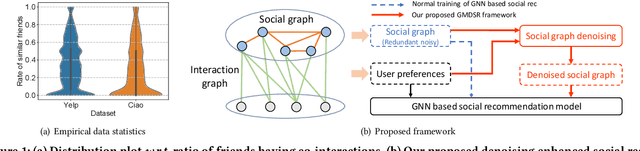

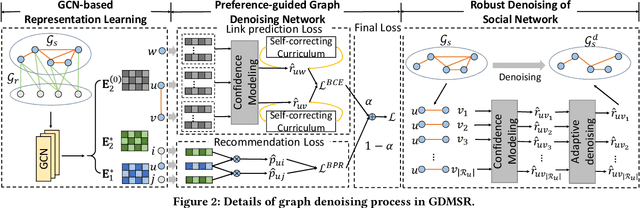
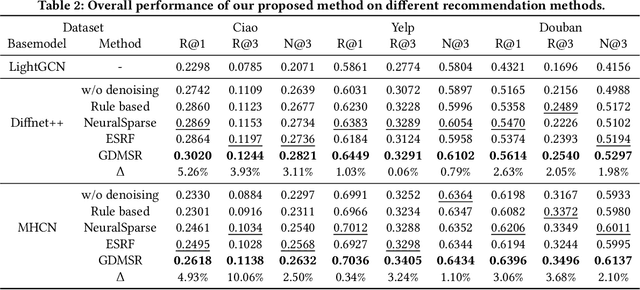
Graph Neural Network(GNN) based social recommendation models improve the prediction accuracy of user preference by leveraging GNN in exploiting preference similarity contained in social relations. However, in terms of both effectiveness and efficiency of recommendation, a large portion of social relations can be redundant or even noisy, e.g., it is quite normal that friends share no preference in a certain domain. Existing models do not fully solve this problem of relation redundancy and noise, as they directly characterize social influence over the full social network. In this paper, we instead propose to improve graph based social recommendation by only retaining the informative social relations to ensure an efficient and effective influence diffusion, i.e., graph denoising. Our designed denoising method is preference-guided to model social relation confidence and benefits user preference learning in return by providing a denoised but more informative social graph for recommendation models. Moreover, to avoid interference of noisy social relations, it designs a self-correcting curriculum learning module and an adaptive denoising strategy, both favoring highly-confident samples. Experimental results on three public datasets demonstrate its consistent capability of improving two state-of-the-art social recommendation models by robustly removing 10-40% of original relations. We release the source code at https://github.com/tsinghua-fib-lab/Graph-Denoising-SocialRec.
DVR: Micro-Video Recommendation Optimizing Watch-Time-Gain under Duration Bias
Aug 10, 2022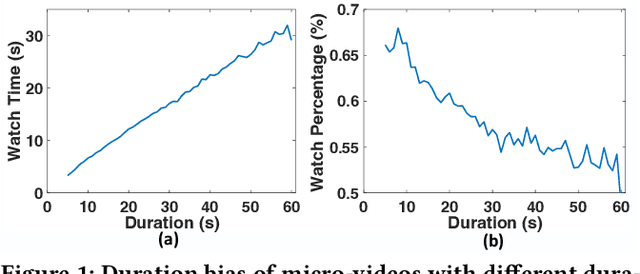
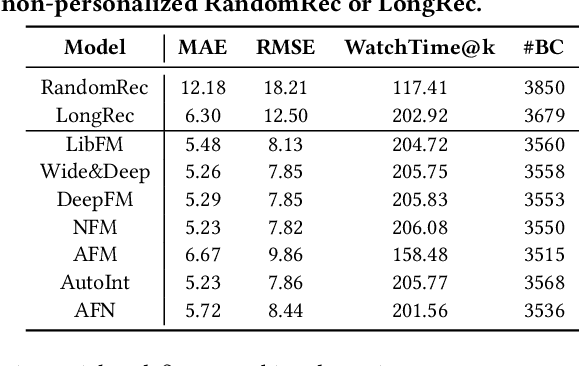
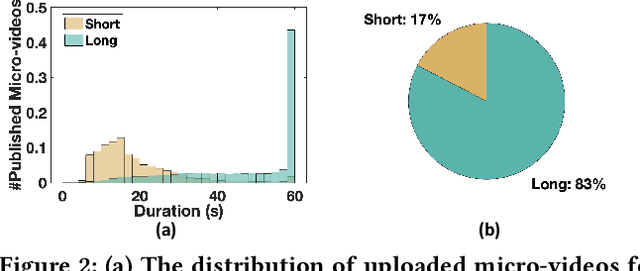
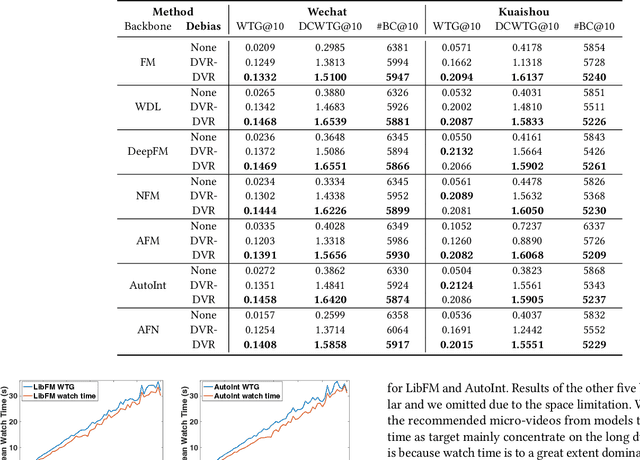
Recommender systems are prone to be misled by biases in the data. Models trained with biased data fail to capture the real interests of users, thus it is critical to alleviate the impact of bias to achieve unbiased recommendation. In this work, we focus on an essential bias in micro-video recommendation, duration bias. Specifically, existing micro-video recommender systems usually consider watch time as the most critical metric, which measures how long a user watches a video. Since videos with longer duration tend to have longer watch time, there exists a kind of duration bias, making longer videos tend to be recommended more against short videos. In this paper, we empirically show that commonly-used metrics are vulnerable to duration bias, making them NOT suitable for evaluating micro-video recommendation. To address it, we further propose an unbiased evaluation metric, called WTG (short for Watch Time Gain). Empirical results reveal that WTG can alleviate duration bias and better measure recommendation performance. Moreover, we design a simple yet effective model named DVR (short for Debiased Video Recommendation) that can provide unbiased recommendation of micro-videos with varying duration, and learn unbiased user preferences via adversarial learning. Extensive experiments based on two real-world datasets demonstrate that DVR successfully eliminates duration bias and significantly improves recommendation performance with over 30% relative progress. Codes and datasets are released at https://github.com/tsinghua-fib-lab/WTG-DVR.
Addressing Confounding Feature Issue for Causal Recommendation
May 13, 2022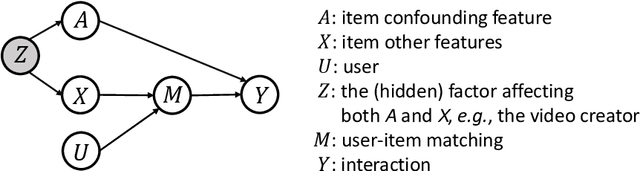

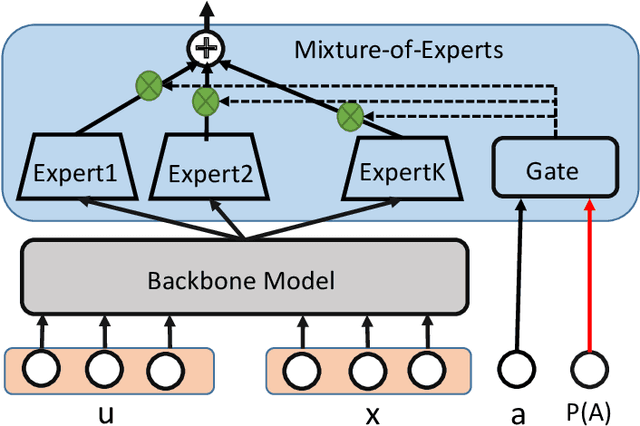
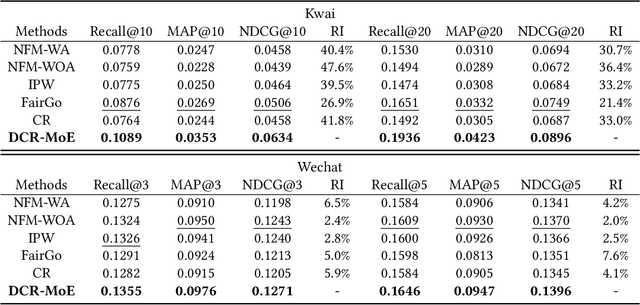
In recommender system, some feature directly affects whether an interaction would happen, making the happened interactions not necessarily indicate user preference. For instance, short videos are objectively easier to be finished even though the user does not like the video. We term such feature as confounding feature, and video length is a confounding feature in video recommendation. If we fit a model on such interaction data, just as done by most data-driven recommender systems, the model will be biased to recommend short videos more, and deviate from user actual requirement. This work formulates and addresses the problem from the causal perspective. Assuming there are some factors affecting both the confounding feature and other item features, e.g., the video creator, we find the confounding feature opens a backdoor path behind user item matching and introduces spurious correlation. To remove the effect of backdoor path, we propose a framework named Deconfounding Causal Recommendation (DCR), which performs intervened inference with do-calculus. Nevertheless, evaluating do calculus requires to sum over the prediction on all possible values of confounding feature, significantly increasing the time cost. To address the efficiency challenge, we further propose a mixture-of experts (MoE) model architecture, modeling each value of confounding feature with a separate expert module. Through this way, we retain the model expressiveness with few additional costs. We demonstrate DCR on the backbone model of neural factorization machine (NFM), showing that DCR leads to more accurate prediction of user preference with small inference time cost.
Graph Domain Adaptation: A Generative View
Jun 14, 2021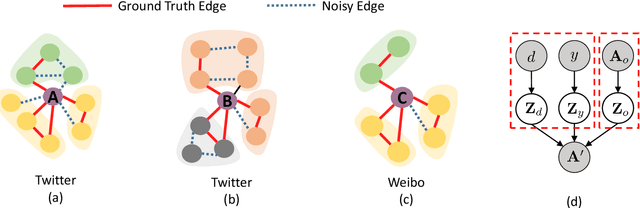
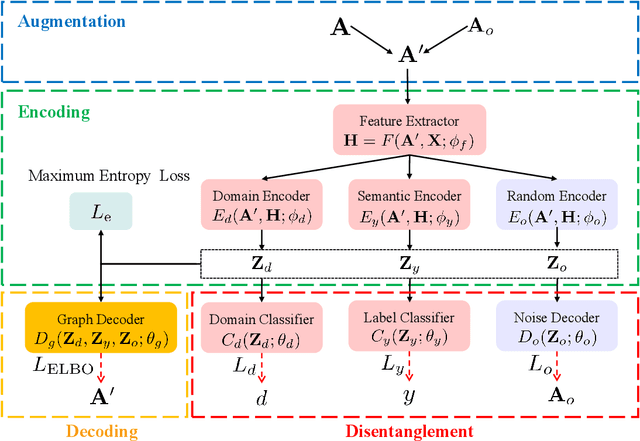
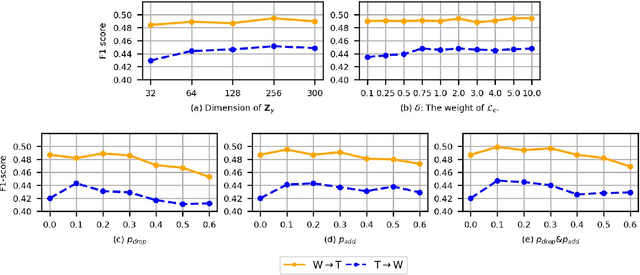
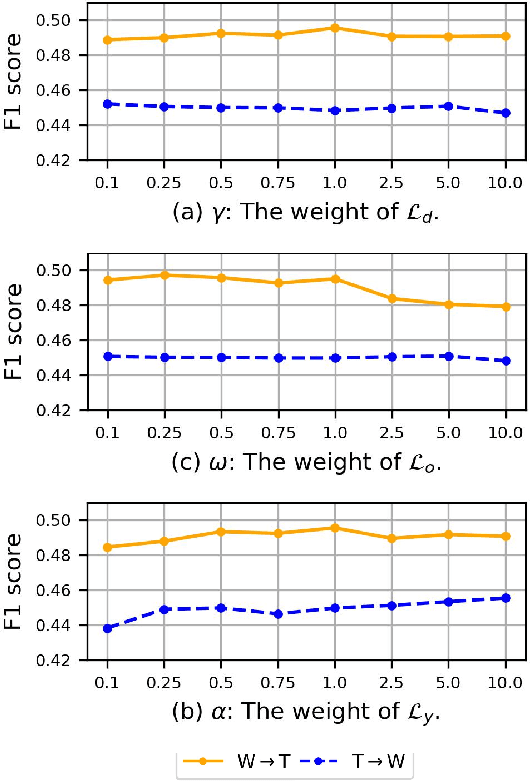
Recent years have witnessed tremendous interest in deep learning on graph-structured data. Due to the high cost of collecting labeled graph-structured data, domain adaptation is important to supervised graph learning tasks with limited samples. However, current graph domain adaptation methods are generally adopted from traditional domain adaptation tasks, and the properties of graph-structured data are not well utilized. For example, the observed social networks on different platforms are controlled not only by the different crowd or communities but also by the domain-specific policies and the background noise. Based on these properties in graph-structured data, we first assume that the graph-structured data generation process is controlled by three independent types of latent variables, i.e., the semantic latent variables, the domain latent variables, and the random latent variables. Based on this assumption, we propose a disentanglement-based unsupervised domain adaptation method for the graph-structured data, which applies variational graph auto-encoders to recover these latent variables and disentangles them via three supervised learning modules. Extensive experimental results on two real-world datasets in the graph classification task reveal that our method not only significantly outperforms the traditional domain adaptation methods and the disentangled-based domain adaptation methods but also outperforms the state-of-the-art graph domain adaptation algorithms.
SocialTrans: A Deep Sequential Model with Social Information for Web-Scale Recommendation Systems
May 09, 2020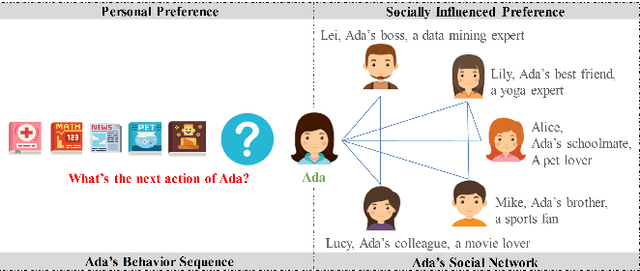
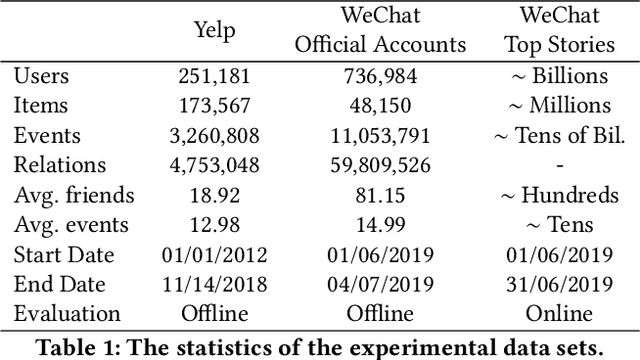
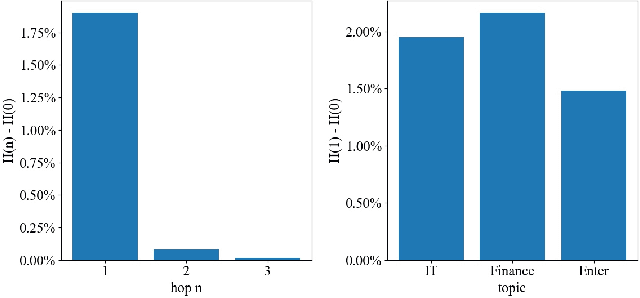
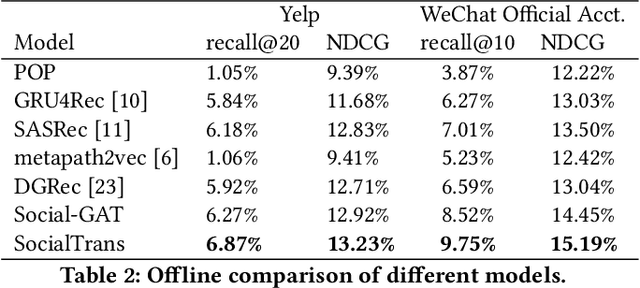
On social network platforms, a user's behavior is based on his/her personal interests, or influenced by his/her friends. In the literature, it is common to model either users' personal preference or their socially influenced preference. In this paper, we present a novel deep learning model SocialTrans for social recommendations to integrate these two types of preferences. SocialTrans is composed of three modules. The first module is based on a multi-layer Transformer to model users' personal preference. The second module is a multi-layer graph attention neural network (GAT), which is used to model the social influence strengths between friends in social networks. The last module merges users' personal preference and socially influenced preference to produce recommendations. Our model can efficiently fit large-scale data and we deployed SocialTrans to a major article recommendation system in China. Experiments on three data sets verify the effectiveness of our model and show that it outperforms state-of-the-art social recommendation methods.