 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREST: Debiased Social Recommendation via Reconstructing Exposure Strategies
Jan 13, 2022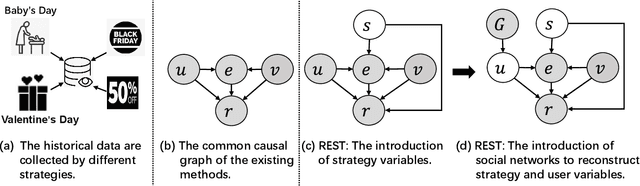
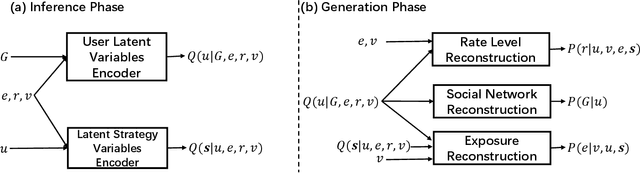
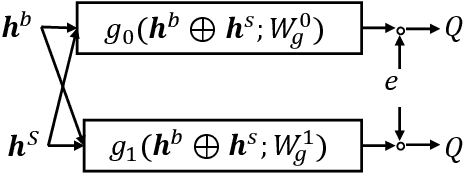
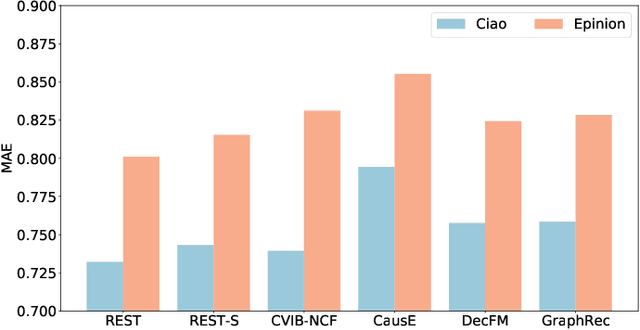
The recommendation system, relying on historical observational data to model the complex relationships among the users and items, has achieved great success in real-world applications. Selection bias is one of the most important issues of the existing observational data based approaches, which is actually caused by multiple types of unobserved exposure strategies (e.g. promotions and holiday effects). Though various methods have been proposed to address this problem, they are mainly relying on the implicit debiasing techniques but not explicitly modeling the unobserved exposure strategies. By explicitly Reconstructing Exposure STrategies (REST in short), we formalize the recommendation problem as the counterfactual reasoning and propose the debiased social recommendation method. In REST, we assume that the exposure of an item is controlled by the latent exposure strategies, the user, and the item. Based on the above generation process, we first provide the theoretical guarantee of our method via identification analysis. Second, we employ a variational auto-encoder to reconstruct the latent exposure strategies, with the help of the social networks and the items. Third, we devise a counterfactual reasoning based recommendation algorithm by leveraging the recovered exposure strategies. Experiments on four real-world datasets, including three published datasets and one private WeChat Official Account dataset, demonstrate significant improvements over several state-of-the-art methods.
TEA: A Sequential Recommendation Framework via Temporally Evolving Aggregations
Nov 14, 2021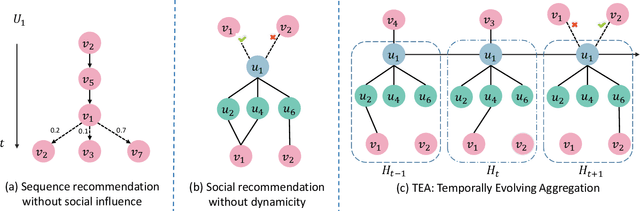
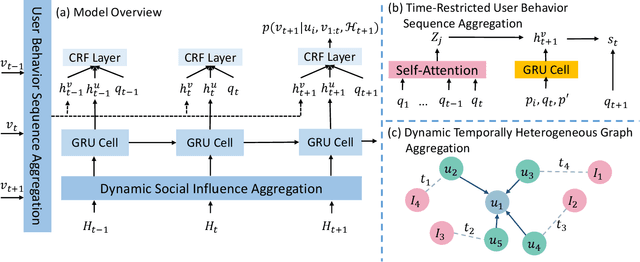
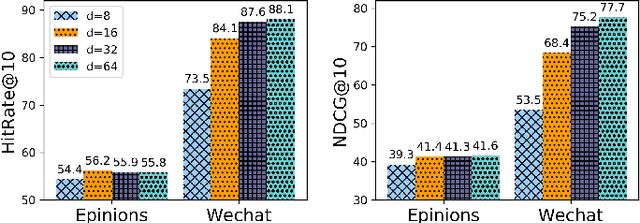
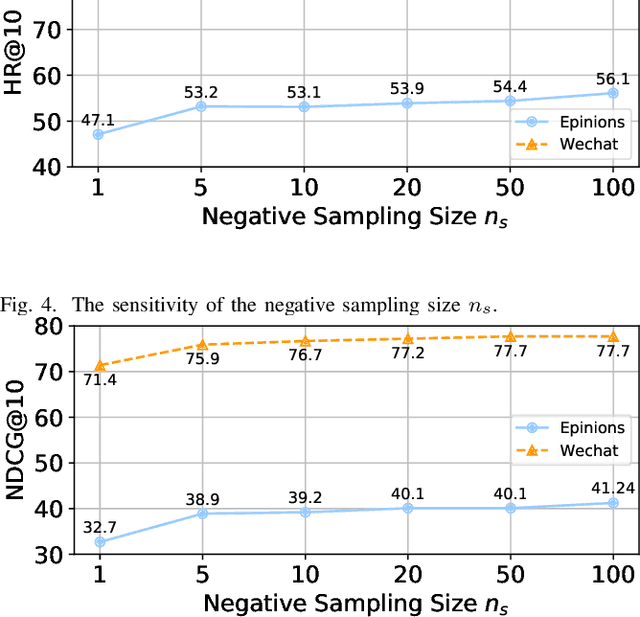
Sequential recommendation aims to choose the most suitable items for a user at a specific timestamp given historical behaviors. Existing methods usually model the user behavior sequence based on the transition-based methods like Markov Chain. However, these methods also implicitly assume that the users are independent of each other without considering the influence between users. In fact, this influence plays an important role in sequence recommendation since the behavior of a user is easily affected by others. Therefore, it is desirable to aggregate both user behaviors and the influence between users, which are evolved temporally and involved in the heterogeneous graph of users and items. In this paper, we incorporate dynamic user-item heterogeneous graphs to propose a novel sequential recommendation framework. As a result, the historical behaviors as well as the influence between users can be taken into consideration. To achieve this, we firstly formalize sequential recommendation as a problem to estimate conditional probability given temporal dynamic heterogeneous graphs and user behavior sequences. After that, we exploit the conditional random field to aggregate the heterogeneous graphs and user behaviors for probability estimation, and employ the pseudo-likelihood approach to derive a tractable objective function. Finally, we provide scalable and flexible implementations of the proposed framework. Experimental results on three real-world datasets not only demonstrate the effectiveness of our proposed method but also provide some insightful discoveries on sequential recommendation.
Graph Domain Adaptation: A Generative View
Jun 14, 2021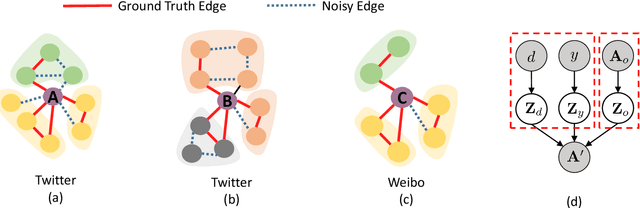
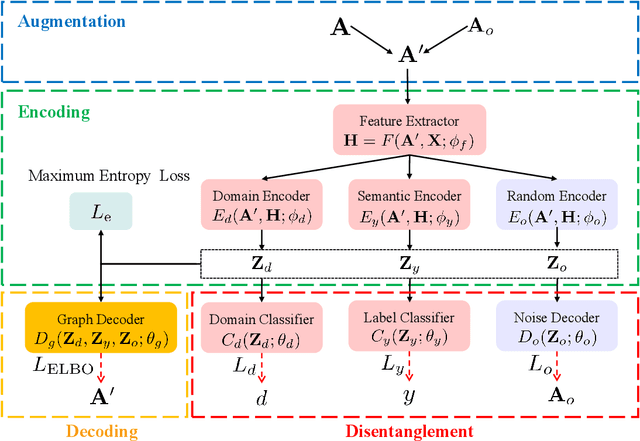
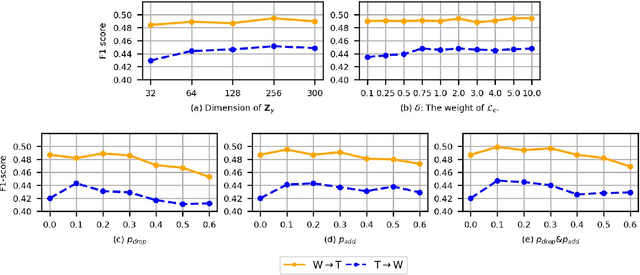
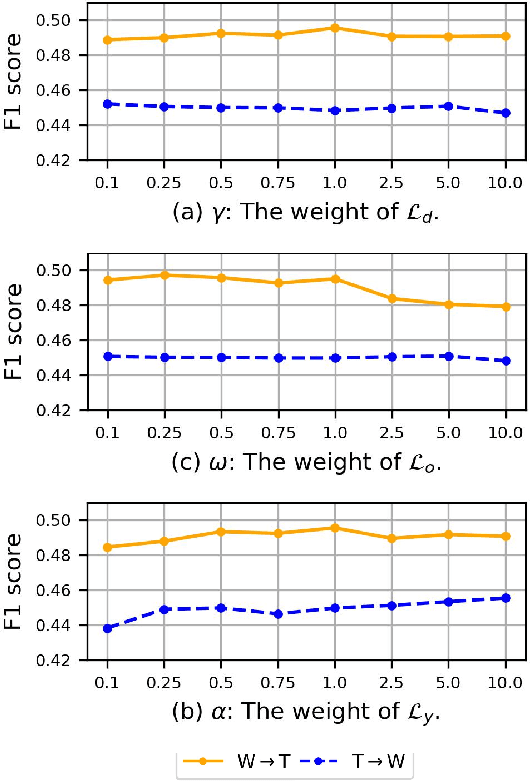
Recent years have witnessed tremendous interest in deep learning on graph-structured data. Due to the high cost of collecting labeled graph-structured data, domain adaptation is important to supervised graph learning tasks with limited samples. However, current graph domain adaptation methods are generally adopted from traditional domain adaptation tasks, and the properties of graph-structured data are not well utilized. For example, the observed social networks on different platforms are controlled not only by the different crowd or communities but also by the domain-specific policies and the background noise. Based on these properties in graph-structured data, we first assume that the graph-structured data generation process is controlled by three independent types of latent variables, i.e., the semantic latent variables, the domain latent variables, and the random latent variables. Based on this assumption, we propose a disentanglement-based unsupervised domain adaptation method for the graph-structured data, which applies variational graph auto-encoders to recover these latent variables and disentangles them via three supervised learning modules. Extensive experimental results on two real-world datasets in the graph classification task reveal that our method not only significantly outperforms the traditional domain adaptation methods and the disentangled-based domain adaptation methods but also outperforms the state-of-the-art graph domain adaptation algorithms.