 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoseTraj: Pose-Aware Trajectory Control in Video Diffusion
Mar 20, 2025



Recent advancements in trajectory-guided video generation have achieved notable progress. However, existing models still face challenges in generating object motions with potentially changing 6D poses under wide-range rotations, due to limited 3D understanding. To address this problem, we introduce PoseTraj, a pose-aware video dragging model for generating 3D-aligned motion from 2D trajectories. Our method adopts a novel two-stage pose-aware pretraining framework, improving 3D understanding across diverse trajectories. Specifically, we propose a large-scale synthetic dataset PoseTraj-10K, containing 10k videos of objects following rotational trajectories, and enhance the model perception of object pose changes by incorporating 3D bounding boxes as intermediate supervision signals. Following this, we fine-tune the trajectory-controlling module on real-world videos, applying an additional camera-disentanglement module to further refine motion accuracy. Experiments on various benchmark datasets demonstrate that our method not only excels in 3D pose-aligned dragging for rotational trajectories but also outperforms existing baselines in trajectory accuracy and video quality.
C2G2: Controllable Co-speech Gesture Generation with Latent Diffusion Model
Aug 29, 2023



Co-speech gesture generation is crucial for automatic digital avatar animation. However, existing methods suffer from issues such as unstable training and temporal inconsistency, particularly in generating high-fidelity and comprehensive gestures. Additionally, these methods lack effective control over speaker identity and temporal editing of the generated gestures. Focusing on capturing temporal latent information and applying practical controlling, we propose a Controllable Co-speech Gesture Generation framework, named C2G2. Specifically, we propose a two-stage temporal dependency enhancement strategy motivated by latent diffusion models. We further introduce two key features to C2G2, namely a speaker-specific decoder to generate speaker-related real-length skeletons and a repainting strategy for flexible gesture generation/editing. Extensive experiments on benchmark gesture datasets verify the effectiveness of our proposed C2G2 compared with several state-of-the-art baselines. The link of the project demo page can be found at https://c2g2-gesture.github.io/c2_gesture
SR-R$^2$KAC: Improving Single Image Defocus Deblurring
Jul 30, 2023



We propose an efficient deep learning method for single image defocus deblurring (SIDD) by further exploring inverse kernel properties. Although the current inverse kernel method, i.e., kernel-sharing parallel atrous convolution (KPAC), can address spatially varying defocus blurs, it has difficulty in handling large blurs of this kind. To tackle this issue, we propose a Residual and Recursive Kernel-sharing Atrous Convolution (R$^2$KAC). R$^2$KAC builds on a significant observation of inverse kernels, that is, successive use of inverse-kernel-based deconvolutions with fixed size helps remove unexpected large blurs but produces ringing artifacts. Specifically, on top of kernel-sharing atrous convolutions used to simulate multi-scale inverse kernels, R$^2$KAC applies atrous convolutions recursively to simulate a large inverse kernel. Specifically, on top of kernel-sharing atrous convolutions, R$^2$KAC stacks atrous convolutions recursively to simulate a large inverse kernel. To further alleviate the contingent effect of recursive stacking, i.e., ringing artifacts, we add identity shortcuts between atrous convolutions to simulate residual deconvolutions. Lastly, a scale recurrent module is embedded in the R$^2$KAC network, leading to SR-R$^2$KAC, so that multi-scale information from coarse to fine is exploited to progressively remove the spatially varying defocus blurs. Extensive experimental results show that our method achieves the state-of-the-art performance.
Mega-TTS 2: Zero-Shot Text-to-Speech with Arbitrary Length Speech Prompts
Jul 14, 2023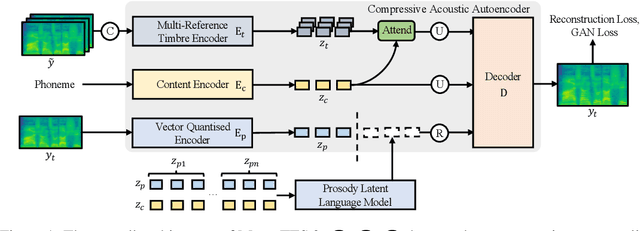
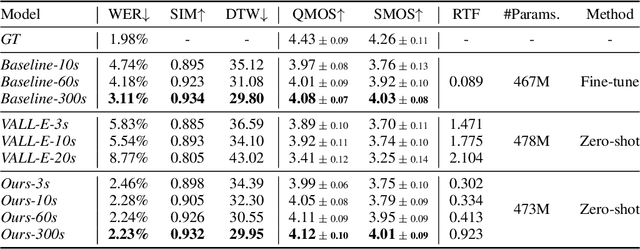
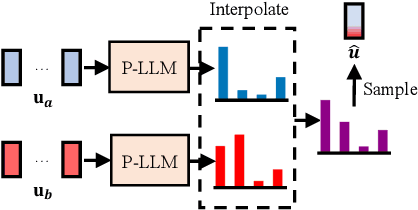

Zero-shot text-to-speech aims at synthesizing voices with unseen speech prompts. Previous large-scale multispeaker TTS models have successfully achieved this goal with an enrolled recording within 10 seconds. However, most of them are designed to utilize only short speech prompts. The limited information in short speech prompts significantly hinders the performance of fine-grained identity imitation. In this paper, we introduce Mega-TTS 2, a generic zero-shot multispeaker TTS model that is capable of synthesizing speech for unseen speakers with arbitrary-length prompts. Specifically, we 1) design a multi-reference timbre encoder to extract timbre information from multiple reference speeches; 2) and train a prosody language model with arbitrary-length speech prompts; With these designs, our model is suitable for prompts of different lengths, which extends the upper bound of speech quality for zero-shot text-to-speech. Besides arbitrary-length prompts, we introduce arbitrary-source prompts, which leverages the probabilities derived from multiple P-LLM outputs to produce expressive and controlled prosody. Furthermore, we propose a phoneme-level auto-regressive duration model to introduce in-context learning capabilities to duration modeling. Experiments demonstrate that our method could not only synthesize identity-preserving speech with a short prompt of an unseen speaker but also achieve improved performance with longer speech prompts. Audio samples can be found in https://mega-tts.github.io/mega2_demo/.
Adaptive Policy Learning for Offline-to-Online Reinforcement Learning
Mar 14, 2023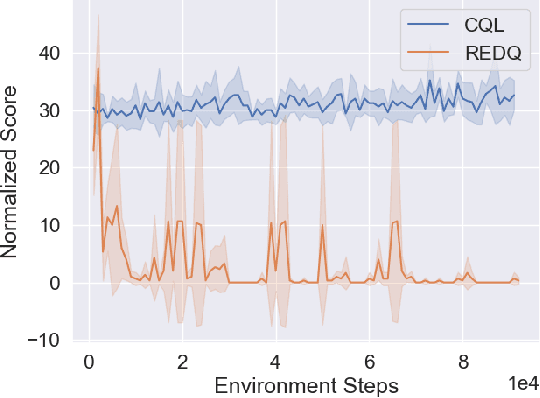
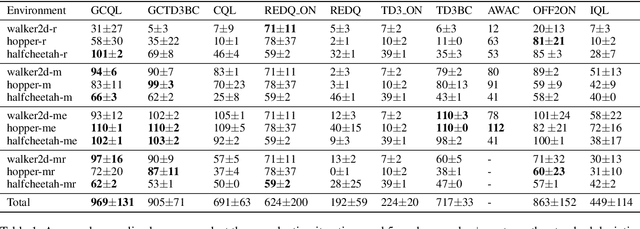
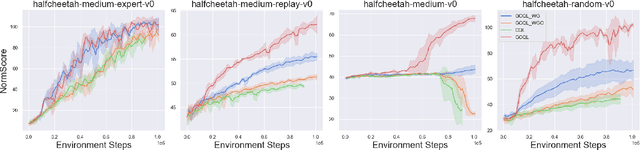
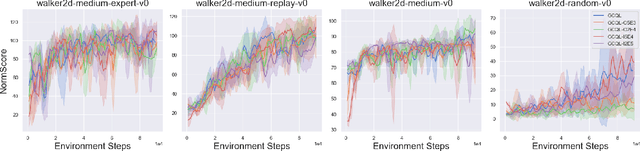
Conventional reinforcement learning (RL) needs an environment to collect fresh data, which is impractical when online interactions are costly. Offline RL provides an alternative solution by directly learning from the previously collected dataset. However, it will yield unsatisfactory performance if the quality of the offline datasets is poor. In this paper, we consider an offline-to-online setting where the agent is first learned from the offline dataset and then trained online, and propose a framework called Adaptive Policy Learning for effectively taking advantage of offline and online data. Specifically, we explicitly consider the difference between the online and offline data and apply an adaptive update scheme accordingly, that is, a pessimistic update strategy for the offline dataset and an optimistic/greedy update scheme for the online dataset. Such a simple and effective method provides a way to mix the offline and online RL and achieve the best of both worlds. We further provide two detailed algorithms for implementing the framework through embedding value or policy-based RL algorithms into it. Finally, we conduct extensive experiments on popular continuous control tasks, and results show that our algorithm can learn the expert policy with high sample efficiency even when the quality of offline dataset is poor, e.g., random dataset.
Multi-objective optimization via evolutionary algorithm (MOVEA) for high-definition transcranial electrical stimulation of the human brain
Nov 10, 2022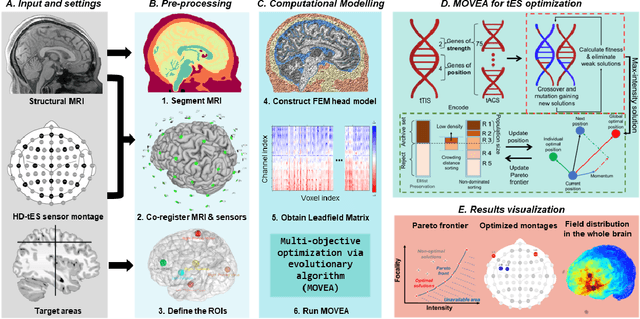
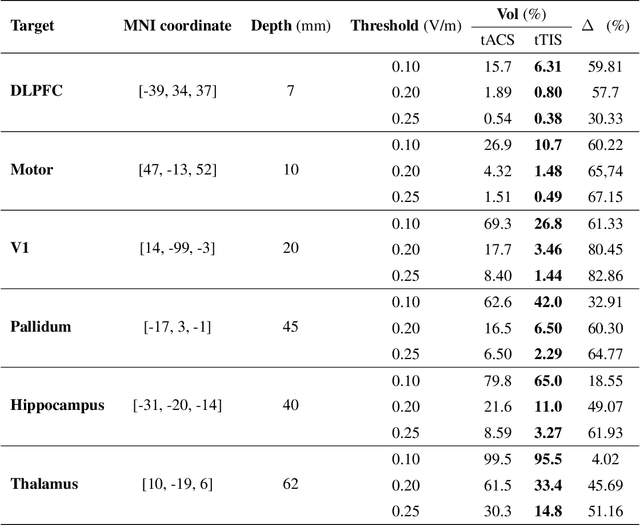
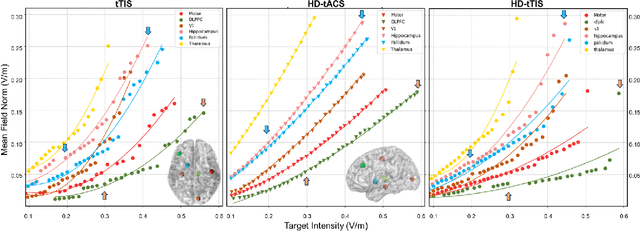
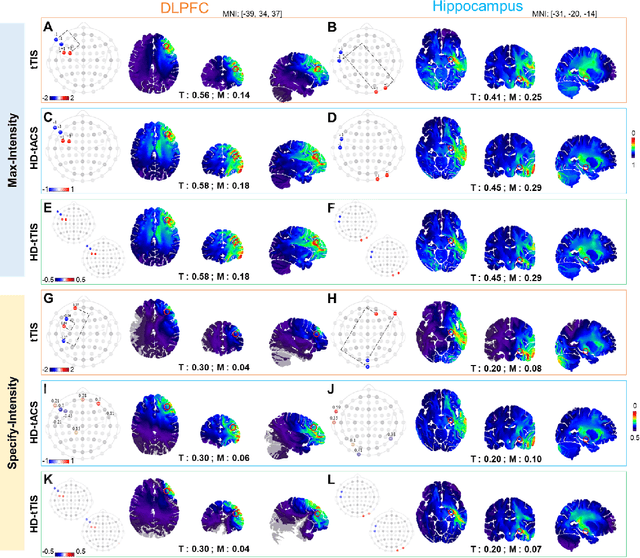
Transcranial temporal interference stimulation (tTIS) has been reported to be effective in stimulating deep brain structures in experimental studies. However, a computational framework for optimizing the tTIS strategy and simulating the impact of tTIS on the brain is still lacking, as previous methods rely on predefined parameters and hardly adapt to additional constraints. Here, we propose a general framework, namely multi-objective optimization via evolutionary algorithm (MOVEA), to solve the nonconvex optimization problem for various stimulation techniques, including tTIS and transcranial alternating current stimulation (tACS). By optimizing the electrode montage in a two-stage structure, MOVEA can be compatible with additional constraints (e.g., the number of electrodes, additional avoidance regions), and MOVEA can accelerate to obtain the Pareto fronts. These Pareto fronts consist of a set of optimal solutions under different requirements, suggesting a trade-off relationship between conflicting objectives, such as intensity and focality. Based on MOVEA, we make comprehensive comparisons between tACS and tTIS in terms of intensity, focality and maneuverability for targets of different depths. Our results show that although the tTIS can only obtain a relatively low maximum achievable electric field strength, for example, the maximum intensity of motor area under tTIS is 0.42V /m, while 0.51V /m under tACS, it helps improve the focality by reducing 60% activated volume outside the target. We further perform ANOVA on the stimulation results of eight subjects with tACS and tTIS. Despite the individual differences in head models, our results suggest that tACS has a greater intensity and tTIS has a higher focality. These findings provide guidance on the choice between tACS and tTIS and indicate a great potential in tTIS-based personalized neuromodulation. Code will be released soon.
Unsupervised Video Domain Adaptation: A Disentanglement Perspective
Aug 15, 2022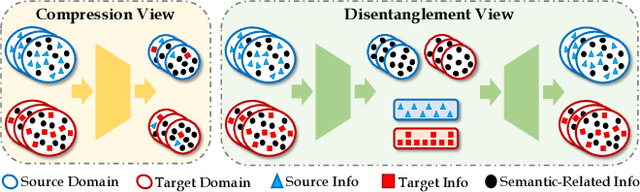
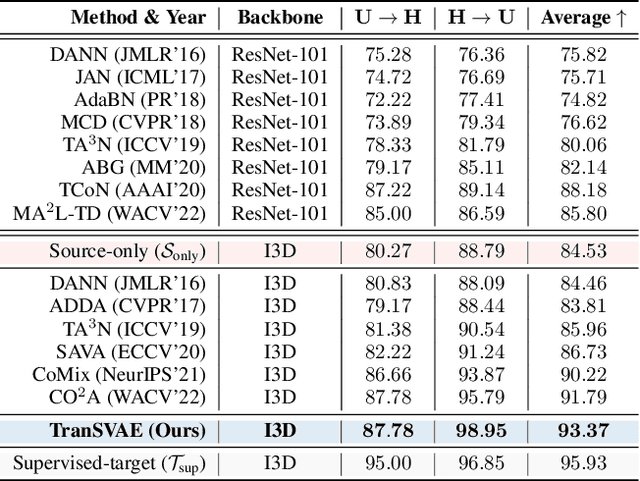
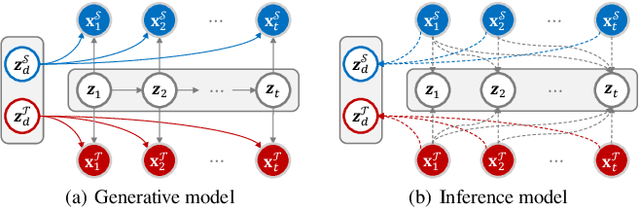
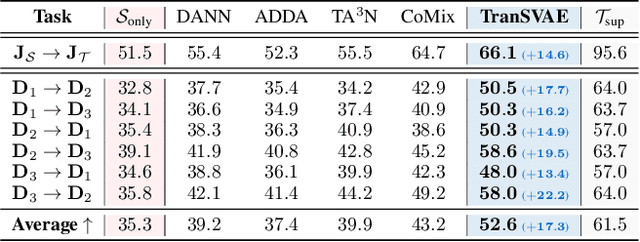
Unsupervised video domain adaptation is a practical yet challenging task. In this work, for the first time, we tackle it from a disentanglement view. Our key idea is to disentangle the domain-related information from the data during the adaptation process. Specifically, we consider the generation of cross-domain videos from two sets of latent factors, one encoding the static domain-related information and another encoding the temporal and semantic-related information. A Transfer Sequential VAE (TranSVAE) framework is then developed to model such generation. To better serve for adaptation, we further propose several objectives to constrain the latent factors in TranSVAE. Extensive experiments on the UCF-HMDB, Jester, and Epic-Kitchens datasets verify the effectiveness and superiority of TranSVAE compared with several state-of-the-art methods. Code is publicly available at https://github.com/ldkong1205/TranSVAE.
Language Adaptive Cross-lingual Speech Representation Learning with Sparse Sharing Sub-networks
Mar 09, 2022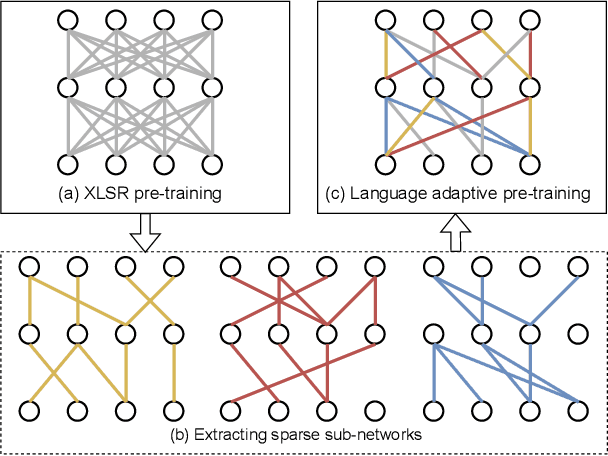
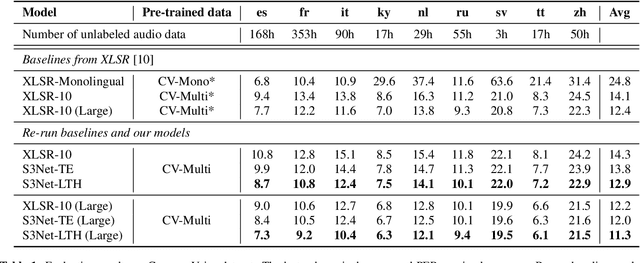
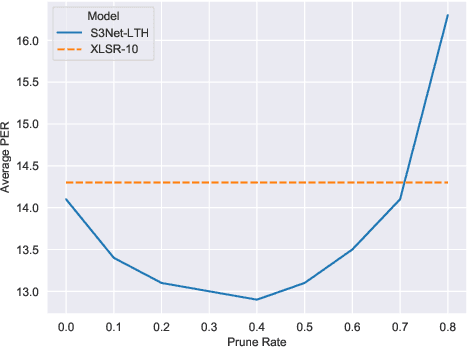
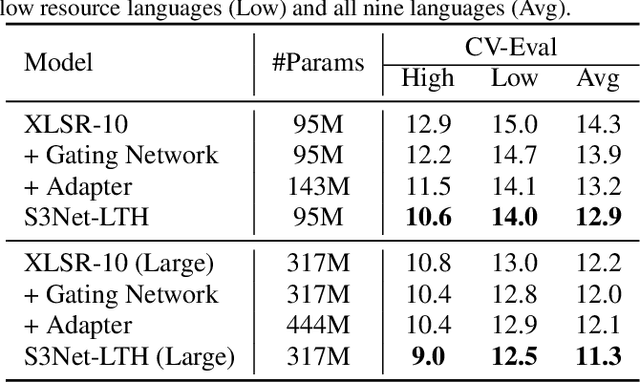
Unsupervised cross-lingual speech representation learning (XLSR) has recently shown promising results in speech recognition by leveraging vast amounts of unlabeled data across multiple languages. However, standard XLSR model suffers from language interference problem due to the lack of language specific modeling ability. In this work, we investigate language adaptive training on XLSR models. More importantly, we propose a novel language adaptive pre-training approach based on sparse sharing sub-networks. It makes room for language specific modeling by pruning out unimportant parameters for each language, without requiring any manually designed language specific component. After pruning, each language only maintains a sparse sub-network, while the sub-networks are partially shared with each other. Experimental results on a downstream multilingual speech recognition task show that our proposed method significantly outperforms baseline XLSR models on both high resource and low resource languages. Besides, our proposed method consistently outperforms other adaptation methods and requires fewer parameters.
Towards Inter-class and Intra-class Imbalance in Class-imbalanced Learning
Nov 24, 2021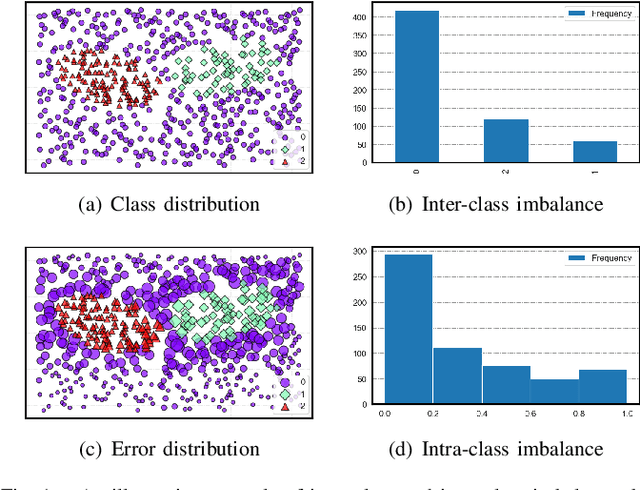
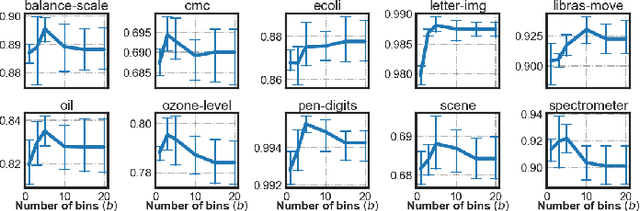
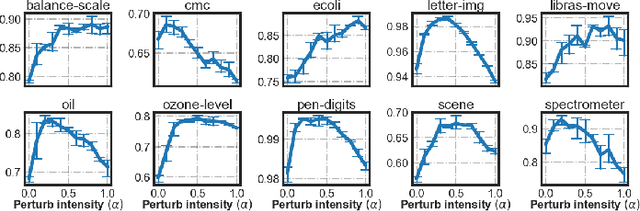
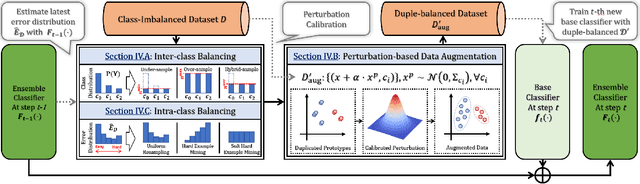
Imbalanced Learning (IL) is an important problem that widely exists in data mining applications. Typical IL methods utilize intuitive class-wise resampling or reweighting to directly balance the training set. However, some recent research efforts in specific domains show that class-imbalanced learning can be achieved without class-wise manipulation. This prompts us to think about the relationship between the two different IL strategies and the nature of the class imbalance. Fundamentally, they correspond to two essential imbalances that exist in IL: the difference in quantity between examples from different classes as well as between easy and hard examples within a single class, i.e., inter-class and intra-class imbalance. Existing works fail to explicitly take both imbalances into account and thus suffer from suboptimal performance. In light of this, we present Duple-Balanced Ensemble, namely DUBE , a versatile ensemble learning framework. Unlike prevailing methods, DUBE directly performs inter-class and intra-class balancing without relying on heavy distance-based computation, which allows it to achieve competitive performance while being computationally efficient. We also present a detailed discussion and analysis about the pros and cons of different inter/intra-class balancing strategies based on DUBE . Extensive experiments validate the effectiveness of the proposed method. Code and examples are available at https://github.com/ICDE2022Sub/duplebalance.
IMBENS: Ensemble Class-imbalanced Learning in Python
Nov 24, 2021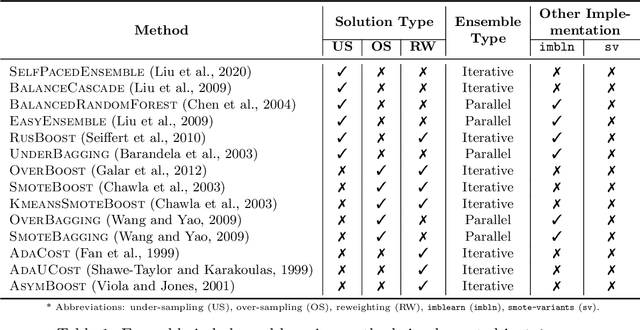
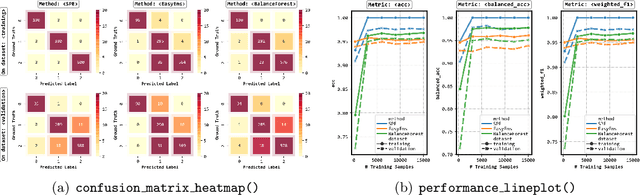
imbalanced-ensemble, abbreviated as imbens, is an open-source Python toolbox for quick implementing and deploying ensemble learning algorithms on class-imbalanced data. It provides access to multiple state-of-art ensemble imbalanced learning (EIL) methods, visualizer, and utility functions for dealing with the class imbalance problem. These ensemble methods include resampling-based, e.g., under/over-sampling, and reweighting-based ones, e.g., cost-sensitive learning. Beyond the implementation, we also extend conventional binary EIL algorithms with new functionalities like multi-class support and resampling scheduler, thereby enabling them to handle more complex tasks. The package was developed under a simple, well-documented API design follows that of scikit-learn for increased ease of use. imbens is released under the MIT open-source license and can be installed from Python Package Index (PyPI). Source code, binaries, detailed documentation, and usage examples are available at https://github.com/ZhiningLiu1998/imbalanced-ensemble.