 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFreeOrbit4D: Training-Free Arbitrary Camera Redirection for Monocular Videos via Geometry-Complete 4D Reconstruction
Jan 26, 2026Camera redirection aims to replay a dynamic scene from a single monocular video under a user-specified camera trajectory. However, large-angle redirection is inherently ill-posed: a monocular video captures only a narrow spatio-temporal view of a dynamic 3D scene, providing highly partial observations of the underlying 4D world. The key challenge is therefore to recover a complete and coherent representation from this limited input, with consistent geometry and motion. While recent diffusion-based methods achieve impressive results, they often break down under large-angle viewpoint changes far from the original trajectory, where missing visual grounding leads to severe geometric ambiguity and temporal inconsistency. To address this, we present FreeOrbit4D, an effective training-free framework that tackles this geometric ambiguity by recovering a geometry-complete 4D proxy as structural grounding for video generation. We obtain this proxy by decoupling foreground and background reconstructions: we unproject the monocular video into a static background and geometry-incomplete foreground point clouds in a unified global space, then leverage an object-centric multi-view diffusion model to synthesize multi-view images and reconstruct geometry-complete foreground point clouds in canonical object space. By aligning the canonical foreground point cloud to the global scene space via dense pixel-synchronized 3D--3D correspondences and projecting the geometry-complete 4D proxy onto target camera viewpoints, we provide geometric scaffolds that guide a conditional video diffusion model. Extensive experiments show that FreeOrbit4D produces more faithful redirected videos under challenging large-angle trajectories, and our geometry-complete 4D proxy further opens a potential avenue for practical applications such as edit propagation and 4D data generation. Project page and code will be released soon.
Versatile and Efficient Medical Image Super-Resolution Via Frequency-Gated Mamba
Oct 31, 2025Medical image super-resolution (SR) is essential for enhancing diagnostic accuracy while reducing acquisition cost and scanning time. However, modeling both long-range anatomical structures and fine-grained frequency details with low computational overhead remains challenging. We propose FGMamba, a novel frequency-aware gated state-space model that unifies global dependency modeling and fine-detail enhancement into a lightweight architecture. Our method introduces two key innovations: a Gated Attention-enhanced State-Space Module (GASM) that integrates efficient state-space modeling with dual-branch spatial and channel attention, and a Pyramid Frequency Fusion Module (PFFM) that captures high-frequency details across multiple resolutions via FFT-guided fusion. Extensive evaluations across five medical imaging modalities (Ultrasound, OCT, MRI, CT, and Endoscopic) demonstrate that FGMamba achieves superior PSNR/SSIM while maintaining a compact parameter footprint ($<$0.75M), outperforming CNN-based and Transformer-based SOTAs. Our results validate the effectiveness of frequency-aware state-space modeling for scalable and accurate medical image enhancement.
Neural Networks for Censored Expectile Regression Based on Data Augmentation
Oct 23, 2025Expectile regression neural networks (ERNNs) are powerful tools for capturing heterogeneity and complex nonlinear structures in data. However, most existing research has primarily focused on fully observed data, with limited attention paid to scenarios involving censored observations. In this paper, we propose a data augmentation based ERNNs algorithm, termed DAERNN, for modeling heterogeneous censored data. The proposed DAERNN is fully data driven, requires minimal assumptions, and offers substantial flexibility. Simulation studies and real data applications demonstrate that DAERNN outperforms existing censored ERNNs methods and achieves predictive performance comparable to models trained on fully observed data. Moreover, the algorithm provides a unified framework for handling various censoring mechanisms without requiring explicit parametric model specification, thereby enhancing its applicability to practical censored data analysis.
Pseudo-Simulation for Autonomous Driving
Jun 04, 2025Existing evaluation paradigms for Autonomous Vehicles (AVs) face critical limitations. Real-world evaluation is often challenging due to safety concerns and a lack of reproducibility, whereas closed-loop simulation can face insufficient realism or high computational costs. Open-loop evaluation, while being efficient and data-driven, relies on metrics that generally overlook compounding errors. In this paper, we propose pseudo-simulation, a novel paradigm that addresses these limitations. Pseudo-simulation operates on real datasets, similar to open-loop evaluation, but augments them with synthetic observations generated prior to evaluation using 3D Gaussian Splatting. Our key idea is to approximate potential future states the AV might encounter by generating a diverse set of observations that vary in position, heading, and speed. Our method then assigns a higher importance to synthetic observations that best match the AV's likely behavior using a novel proximity-based weighting scheme. This enables evaluating error recovery and the mitigation of causal confusion, as in closed-loop benchmarks, without requiring sequential interactive simulation. We show that pseudo-simulation is better correlated with closed-loop simulations (R^2=0.8) than the best existing open-loop approach (R^2=0.7). We also establish a public leaderboard for the community to benchmark new methodologies with pseudo-simulation. Our code is available at https://github.com/autonomousvision/navsim.
Accelerating Multi-Objective Collaborative Optimization of Doped Thermoelectric Materials via Artificial Intelligence
Apr 11, 2025The thermoelectric performance of materials exhibits complex nonlinear dependencies on both elemental types and their proportions, rendering traditional trial-and-error approaches inefficient and time-consuming for material discovery. In this work, we present a deep learning model capable of accurately predicting thermoelectric properties of doped materials directly from their chemical formulas, achieving state-of-the-art performance. To enhance interpretability, we further incorporate sensitivity analysis techniques to elucidate how physical descriptors affect the thermoelectric figure of merit (zT). Moreover, we establish a coupled framework that integrates a surrogate model with a multi-objective genetic algorithm to efficiently explore the vast compositional space for high-performance candidates. Experimental validation confirms the discovery of a novel thermoelectric material with superior $zT$ values in the medium-temperature regime.
Qubit-Wise Architecture Search Method for Variational Quantum Circuits
Mar 07, 2024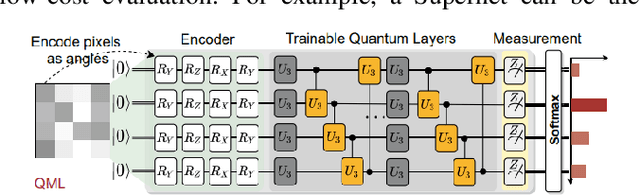

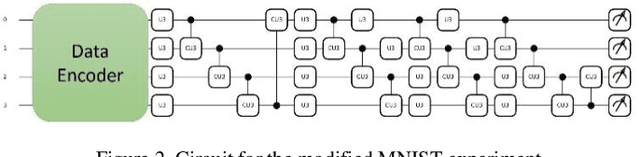
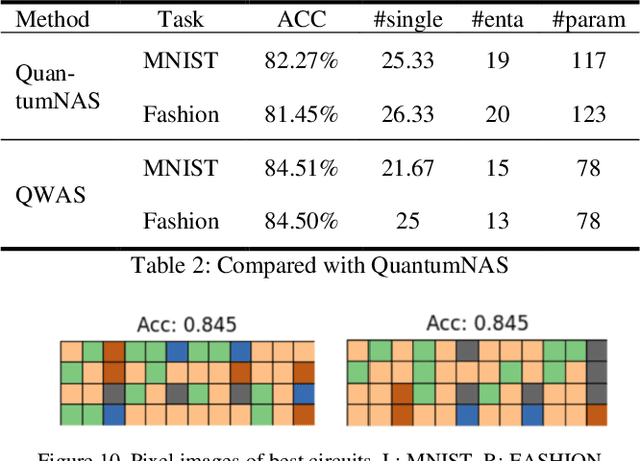
Considering the noise level limit, one crucial aspect for quantum machine learning is to design a high-performing variational quantum circuit architecture with small number of quantum gates. As the classical neural architecture search (NAS), quantum architecture search methods (QAS) employ methods like reinforcement learning, evolutionary algorithms and supernet optimiza-tion to improve the search efficiency. In this paper, we propose a novel qubit-wise architec-ture search (QWAS) method, which progres-sively search one-qubit configuration per stage, and combine with Monte Carlo Tree Search al-gorithm to find good quantum architectures by partitioning the search space into several good and bad subregions. The numerical experimental results indicate that our proposed method can balance the exploration and exploitation of cir-cuit performance and size in some real-world tasks, such as MNIST, Fashion and MOSI. As far as we know, QWAS achieves the state-of-art re-sults of all tasks in the terms of accuracy and circuit size.
Deep Learning for Multivariate Time Series Imputation: A Survey
Feb 06, 2024The ubiquitous missing values cause the multivariate time series data to be partially observed, destroying the integrity of time series and hindering the effective time series data analysis. Recently deep learning imputation methods have demonstrated remarkable success in elevating the quality of corrupted time series data, subsequently enhancing performance in downstream tasks. In this paper, we conduct a comprehensive survey on the recently proposed deep learning imputation methods. First, we propose a taxonomy for the reviewed methods, and then provide a structured review of these methods by highlighting their strengths and limitations. We also conduct empirical experiments to study different methods and compare their enhancement for downstream tasks. Finally, the open issues for future research on multivariate time series imputation are pointed out. All code and configurations of this work, including a regularly maintained multivariate time series imputation paper list, can be found in the GitHub repository~\url{https://github.com/WenjieDu/Awesome\_Imputation}.
Motion2VecSets: 4D Latent Vector Set Diffusion for Non-rigid Shape Reconstruction and Tracking
Jan 12, 2024



We introduce Motion2VecSets, a 4D diffusion model for dynamic surface reconstruction from point cloud sequences. While existing state-of-the-art methods have demonstrated success in reconstructing non-rigid objects using neural field representations, conventional feed-forward networks encounter challenges with ambiguous observations from noisy, partial, or sparse point clouds. To address these challenges, we introduce a diffusion model that explicitly learns the shape and motion distribution of non-rigid objects through an iterative denoising process of compressed latent representations. The diffusion-based prior enables more plausible and probabilistic reconstructions when handling ambiguous inputs. We parameterize 4D dynamics with latent vector sets instead of using a global latent. This novel 4D representation allows us to learn local surface shape and deformation patterns, leading to more accurate non-linear motion capture and significantly improving generalizability to unseen motions and identities. For more temporal-coherent object tracking, we synchronously denoise deformation latent sets and exchange information across multiple frames. To avoid the computational overhead, we design an interleaved space and time attention block to alternately aggregate deformation latents along spatial and temporal domains. Extensive comparisons against the state-of-the-art methods demonstrate the superiority of our Motion2VecSets in 4D reconstruction from various imperfect observations, notably achieving a 19% improvement in Intersection over Union (IoU) compared to CaDex for reconstructing unseen individuals from sparse point clouds on the DeformingThings4D-Animals dataset. More detailed information can be found at https://vveicao.github.io/projects/Motion2VecSets/.
NuTime: Numerically Multi-Scaled Embedding for Large-Scale Time Series Pretraining
Oct 12, 2023Recent research on time-series self-supervised models shows great promise in learning semantic representations. However, it has been limited to small-scale datasets, e.g., thousands of temporal sequences. In this work, we make key technical contributions that are tailored to the numerical properties of time-series data and allow the model to scale to large datasets, e.g., millions of temporal sequences. We adopt the Transformer architecture by first partitioning the input into non-overlapping windows. Each window is then characterized by its normalized shape and two scalar values denoting the mean and standard deviation within each window. To embed scalar values that may possess arbitrary numerical scales to high-dimensional vectors, we propose a numerically multi-scaled embedding module enumerating all possible scales for the scalar values. The model undergoes pretraining using the proposed numerically multi-scaled embedding with a simple contrastive objective on a large-scale dataset containing over a million sequences. We study its transfer performance on a number of univariate and multivariate classification benchmarks. Our method exhibits remarkable improvement against previous representation learning approaches and establishes the new state of the art, even compared with domain-specific non-learning-based methods.
What Matters to Enhance Traffic Rule Compliance of Imitation Learning for Automated Driving
Sep 14, 2023



More research attention has recently been given to end-to-end autonomous driving technologies where the entire driving pipeline is replaced with a single neural network because of its simpler structure and faster inference time. Despite this appealing approach largely reducing the components in driving pipeline, its simplicity also leads to interpretability problems and safety issues arXiv:2003.06404. The trained policy is not always compliant with the traffic rules and it is also hard to discover the reason for the misbehavior because of the lack of intermediate outputs. Meanwhile, Sensors are also critical to autonomous driving's security and feasibility to perceive the surrounding environment under complex driving scenarios. In this paper, we proposed P-CSG, a novel penalty-based imitation learning approach with cross semantics generation sensor fusion technologies to increase the overall performance of End-to-End Autonomous Driving. We conducted an assessment of our model's performance using the Town 05 Long benchmark, achieving an impressive driving score improvement of over 15%. Furthermore, we conducted robustness evaluations against adversarial attacks like FGSM and Dot attacks, revealing a substantial increase in robustness compared to baseline models.More detailed information, such as code-based resources, ablation studies and videos can be found at https://hk-zh.github.io/p-csg-plus.