 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Energy Impact of Domain Model Design in Classical Planning
Jan 29, 2026AI research has traditionally prioritised algorithmic performance, such as optimising accuracy in machine learning or runtime in automated planning. The emerging paradigm of Green AI challenges this by recognising energy consumption as a critical performance dimension. Despite the high computational demands of automated planning, its energy efficiency has received little attention. This gap is particularly salient given the modular planning structure, in which domain models are specified independently of algorithms. On the other hand, this separation also enables systematic analysis of energy usage through domain model design. We empirically investigate how domain model characteristics affect the energy consumption of classical planners. We introduce a domain model configuration framework that enables controlled variation of features, such as element ordering, action arity, and dead-end states. Using five benchmark domains and five state-of-the-art planners, we analyse energy and runtime impacts across 32 domain variants per benchmark. Results demonstrate that domain-level modifications produce measurable energy differences across planners, with energy consumption not always correlating with runtime.
Seeing is Believing (and Predicting): Context-Aware Multi-Human Behavior Prediction with Vision Language Models
Dec 17, 2025Accurately predicting human behaviors is crucial for mobile robots operating in human-populated environments. While prior research primarily focuses on predicting actions in single-human scenarios from an egocentric view, several robotic applications require understanding multiple human behaviors from a third-person perspective. To this end, we present CAMP-VLM (Context-Aware Multi-human behavior Prediction): a Vision Language Model (VLM)-based framework that incorporates contextual features from visual input and spatial awareness from scene graphs to enhance prediction of humans-scene interactions. Due to the lack of suitable datasets for multi-human behavior prediction from an observer view, we perform fine-tuning of CAMP-VLM with synthetic human behavior data generated by a photorealistic simulator, and evaluate the resulting models on both synthetic and real-world sequences to assess their generalization capabilities. Leveraging Supervised Fine-Tuning (SFT) and Direct Preference Optimization (DPO), CAMP-VLM outperforms the best-performing baseline by up to 66.9% in prediction accuracy.
Pseudo-Simulation for Autonomous Driving
Jun 04, 2025Existing evaluation paradigms for Autonomous Vehicles (AVs) face critical limitations. Real-world evaluation is often challenging due to safety concerns and a lack of reproducibility, whereas closed-loop simulation can face insufficient realism or high computational costs. Open-loop evaluation, while being efficient and data-driven, relies on metrics that generally overlook compounding errors. In this paper, we propose pseudo-simulation, a novel paradigm that addresses these limitations. Pseudo-simulation operates on real datasets, similar to open-loop evaluation, but augments them with synthetic observations generated prior to evaluation using 3D Gaussian Splatting. Our key idea is to approximate potential future states the AV might encounter by generating a diverse set of observations that vary in position, heading, and speed. Our method then assigns a higher importance to synthetic observations that best match the AV's likely behavior using a novel proximity-based weighting scheme. This enables evaluating error recovery and the mitigation of causal confusion, as in closed-loop benchmarks, without requiring sequential interactive simulation. We show that pseudo-simulation is better correlated with closed-loop simulations (R^2=0.8) than the best existing open-loop approach (R^2=0.7). We also establish a public leaderboard for the community to benchmark new methodologies with pseudo-simulation. Our code is available at https://github.com/autonomousvision/navsim.
Retrieval-Augmented Generation for Service Discovery: Chunking Strategies and Benchmarking
May 25, 2025Integrating multiple (sub-)systems is essential to create advanced Information Systems. Difficulties mainly arise when integrating dynamic environments, e.g., the integration at design time of not yet existing services. This has been traditionally addressed using a registry that provides the API documentation of the endpoints. Large Language Models have shown to be capable of automatically creating system integrations (e.g., as service composition) based on this documentation but require concise input due to input oken limitations, especially regarding comprehensive API descriptions. Currently, it is unknown how best to preprocess these API descriptions. In the present work, we (i) analyze the usage of Retrieval Augmented Generation for endpoint discovery and the chunking, i.e., preprocessing, of state-of-practice OpenAPIs to reduce the input oken length while preserving the most relevant information. To further reduce the input token length for the composition prompt and improve endpoint retrieval, we propose (ii) a Discovery Agent that only receives a summary of the most relevant endpoints nd retrieves specification details on demand. We evaluate RAG for endpoint discovery using (iii) a proposed novel service discovery benchmark SOCBench-D representing a general setting across numerous domains and the real-world RestBench enchmark, first, for the different chunking possibilities and parameters measuring the endpoint retrieval accuracy. Then, we assess the Discovery Agent using the same test data set. The prototype shows how to successfully employ RAG for endpoint discovery to reduce the token count. Our experiments show that endpoint-based approaches outperform naive chunking methods for preprocessing. Relying on an agent significantly improves precision while being prone to decrease recall, disclosing the need for further reasoning capabilities.
Context-Aware Human Behavior Prediction Using Multimodal Large Language Models: Challenges and Insights
Apr 01, 2025Predicting human behavior in shared environments is crucial for safe and efficient human-robot interaction. Traditional data-driven methods to that end are pre-trained on domain-specific datasets, activity types, and prediction horizons. In contrast, the recent breakthroughs in Large Language Models (LLMs) promise open-ended cross-domain generalization to describe various human activities and make predictions in any context. In particular, Multimodal LLMs (MLLMs) are able to integrate information from various sources, achieving more contextual awareness and improved scene understanding. The difficulty in applying general-purpose MLLMs directly for prediction stems from their limited capacity for processing large input sequences, sensitivity to prompt design, and expensive fine-tuning. In this paper, we present a systematic analysis of applying pre-trained MLLMs for context-aware human behavior prediction. To this end, we introduce a modular multimodal human activity prediction framework that allows us to benchmark various MLLMs, input variations, In-Context Learning (ICL), and autoregressive techniques. Our evaluation indicates that the best-performing framework configuration is able to reach 92.8% semantic similarity and 66.1% exact label accuracy in predicting human behaviors in the target frame.
Introduction to AI Planning
Dec 16, 2024



These are notes for lectures presented at the University of Stuttgart that provide an introduction to key concepts and techniques in AI Planning. Artificial Intelligence Planning, also known as Automated Planning, emerged somewhere in 1966 from the need to give autonomy to a wheeled robot. Since then, it has evolved into a flourishing research and development discipline, often associated with scheduling. Over the decades, various approaches to planning have been developed with characteristics that make them appropriate for specific tasks and applications. Most approaches represent the world as a state within a state transition system; then the planning problem becomes that of searching a path in the state space from the current state to one which satisfies the goals of the user. The notes begin by introducing the state model and move on to exploring classical planning, the foundational form of planning, and present fundamental algorithms for solving such problems. Subsequently, we examine planning as a constraint satisfaction problem, outlining the mapping process and describing an approach to solve such problems. The most extensive section is dedicated to Hierarchical Task Network (HTN) planning, one of the most widely used and powerful planning techniques in the field. The lecture notes end with a bonus chapter on the Planning Domain Definition (PDDL) Language, the de facto standard syntax for representing non-hierarchical planning problems.
Advanced System Integration: Analyzing OpenAPI Chunking for Retrieval-Augmented Generation
Nov 29, 2024

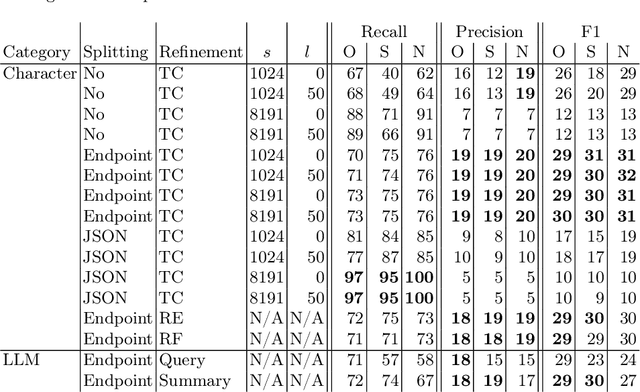
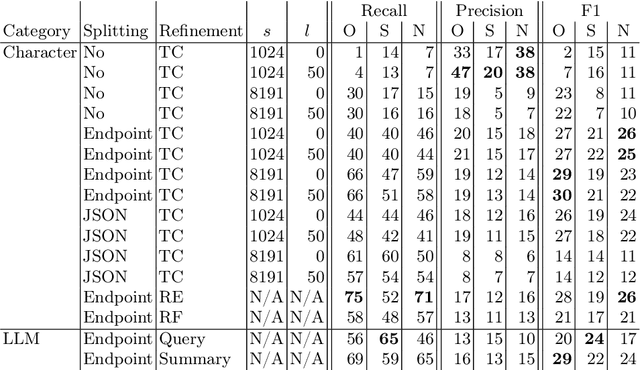
Integrating multiple (sub-)systems is essential to create advanced Information Systems (ISs). Difficulties mainly arise when integrating dynamic environments across the IS lifecycle. A traditional approach is a registry that provides the API documentation of the systems' endpoints. Large Language Models (LLMs) have shown to be capable of automatically creating system integrations (e.g., as service composition) based on this documentation but require concise input due to input token limitations, especially regarding comprehensive API descriptions. Currently, it is unknown how best to preprocess these API descriptions. Within this work, we (i) analyze the usage of Retrieval Augmented Generation (RAG) for endpoint discovery and the chunking, i.e., preprocessing, of OpenAPIs to reduce the input token length while preserving the most relevant information. To further reduce the input token length for the composition prompt and improve endpoint retrieval, we propose (ii) a Discovery Agent that only receives a summary of the most relevant endpoints and retrieves details on demand. We evaluate RAG for endpoint discovery using the RestBench benchmark, first, for the different chunking possibilities and parameters measuring the endpoint retrieval recall, precision, and F1 score. Then, we assess the Discovery Agent using the same test set. With our prototype, we demonstrate how to successfully employ RAG for endpoint discovery to reduce the token count. While revealing high values for recall, precision, and F1, further research is necessary to retrieve all requisite endpoints. Our experiments show that for preprocessing, LLM-based and format-specific approaches outperform na\"ive chunking methods. Relying on an agent further enhances these results as the agent splits the tasks into multiple fine granular subtasks, improving the overall RAG performance in the token count, precision, and F1 score.
Towards Human Awareness in Robot Task Planning with Large Language Models
Apr 17, 2024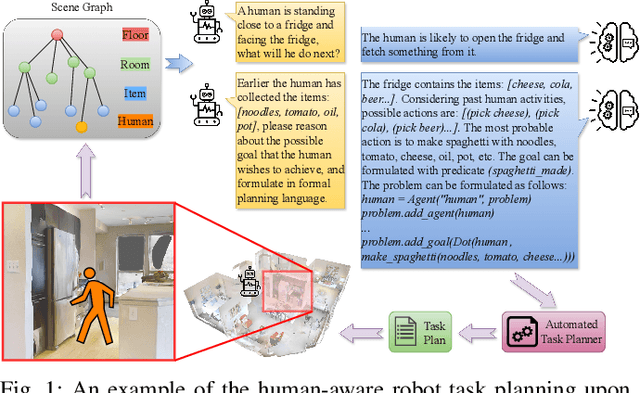
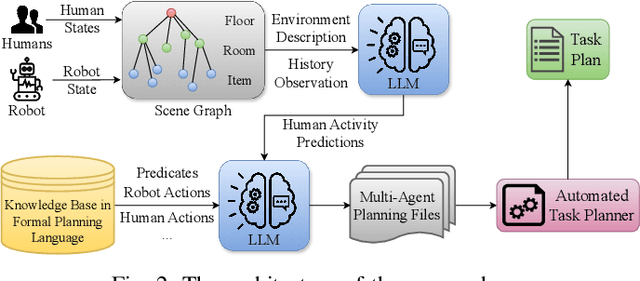
The recent breakthroughs in the research on Large Language Models (LLMs) have triggered a transformation across several research domains. Notably, the integration of LLMs has greatly enhanced performance in robot Task And Motion Planning (TAMP). However, previous approaches often neglect the consideration of dynamic environments, i.e., the presence of dynamic objects such as humans. In this paper, we propose a novel approach to address this gap by incorporating human awareness into LLM-based robot task planning. To obtain an effective representation of the dynamic environment, our approach integrates humans' information into a hierarchical scene graph. To ensure the plan's executability, we leverage LLMs to ground the environmental topology and actionable knowledge into formal planning language. Most importantly, we use LLMs to predict future human activities and plan tasks for the robot considering the predictions. Our contribution facilitates the development of integrating human awareness into LLM-driven robot task planning, and paves the way for proactive robot decision-making in dynamic environments.
DELTA: Decomposed Efficient Long-Term Robot Task Planning using Large Language Models
Apr 04, 2024



Recent advancements in Large Language Models (LLMs) have sparked a revolution across various research fields. In particular, the integration of common-sense knowledge from LLMs into robot task and motion planning has been proven to be a game-changer, elevating performance in terms of explainability and downstream task efficiency to unprecedented heights. However, managing the vast knowledge encapsulated within these large models has posed challenges, often resulting in infeasible plans generated by LLM-based planning systems due to hallucinations or missing domain information. To overcome these challenges and obtain even greater planning feasibility and computational efficiency, we propose a novel LLM-driven task planning approach called DELTA. For achieving better grounding from environmental topology into actionable knowledge, DELTA leverages the power of scene graphs as environment representations within LLMs, enabling the fast generation of precise planning problem descriptions. For obtaining higher planning performance, we use LLMs to decompose the long-term task goals into an autoregressive sequence of sub-goals for an automated task planner to solve. Our contribution enables a more efficient and fully automatic task planning pipeline, achieving higher planning success rates and significantly shorter planning times compared to the state of the art.
The STOIC2021 COVID-19 AI challenge: applying reusable training methodologies to private data
Jun 25, 2023Challenges drive the state-of-the-art of automated medical image analysis. The quantity of public training data that they provide can limit the performance of their solutions. Public access to the training methodology for these solutions remains absent. This study implements the Type Three (T3) challenge format, which allows for training solutions on private data and guarantees reusable training methodologies. With T3, challenge organizers train a codebase provided by the participants on sequestered training data. T3 was implemented in the STOIC2021 challenge, with the goal of predicting from a computed tomography (CT) scan whether subjects had a severe COVID-19 infection, defined as intubation or death within one month. STOIC2021 consisted of a Qualification phase, where participants developed challenge solutions using 2000 publicly available CT scans, and a Final phase, where participants submitted their training methodologies with which solutions were trained on CT scans of 9724 subjects. The organizers successfully trained six of the eight Final phase submissions. The submitted codebases for training and running inference were released publicly. The winning solution obtained an area under the receiver operating characteristic curve for discerning between severe and non-severe COVID-19 of 0.815. The Final phase solutions of all finalists improved upon their Qualification phase solutions.HSUXJM-TNZF9CHSUXJM-TNZF9C