 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConflict Mitigation in Shared Environments using Flow-Aware Multi-Agent Path Finding
Mar 13, 2026Deploying multi-robot systems in environments shared with dynamic and uncontrollable agents presents significant challenges, especially for large robot fleets. In such environments, individual robot operations can be delayed due to unforeseen conflicts with uncontrollable agents. While existing research primarily focuses on preserving the completeness of Multi-Agent Path Finding (MAPF) solutions considering delays, there is limited emphasis on utilizing additional environmental information to enhance solution quality in the presence of other dynamic agents. To this end, we propose Flow-Aware Multi-Agent Path Finding (FA-MAPF), a novel framework that integrates learned motion patterns of uncontrollable agents into centralized MAPF algorithms. Our evaluation, conducted on a diverse set of benchmark maps with simulated uncontrollable agents and on a real-world map with recorded human trajectories, demonstrates the effectiveness of FA-MAPF compared to state-of-the-art baselines. The experimental results show that FA-MAPF can consistently reduce conflicts with uncontrollable agents, up to 55%, without compromising task efficiency.
UPTor: Unified 3D Human Pose Dynamics and Trajectory Prediction for Human-Robot Interaction
May 20, 2025



We introduce a unified approach to forecast the dynamics of human keypoints along with the motion trajectory based on a short sequence of input poses. While many studies address either full-body pose prediction or motion trajectory prediction, only a few attempt to merge them. We propose a motion transformation technique to simultaneously predict full-body pose and trajectory key-points in a global coordinate frame. We utilize an off-the-shelf 3D human pose estimation module, a graph attention network to encode the skeleton structure, and a compact, non-autoregressive transformer suitable for real-time motion prediction for human-robot interaction and human-aware navigation. We introduce a human navigation dataset ``DARKO'' with specific focus on navigational activities that are relevant for human-aware mobile robot navigation. We perform extensive evaluation on Human3.6M, CMU-Mocap, and our DARKO dataset. In comparison to prior work, we show that our approach is compact, real-time, and accurate in predicting human navigation motion across all datasets. Result animations, our dataset, and code will be available at https://nisarganc.github.io/UPTor-page/
Collecting Human Motion Data in Large and Occlusion-Prone Environments using Ultra-Wideband Localization
May 09, 2025With robots increasingly integrating into human environments, understanding and predicting human motion is essential for safe and efficient interactions. Modern human motion and activity prediction approaches require high quality and quantity of data for training and evaluation, usually collected from motion capture systems, onboard or stationary sensors. Setting up these systems is challenging due to the intricate setup of hardware components, extensive calibration procedures, occlusions, and substantial costs. These constraints make deploying such systems in new and large environments difficult and limit their usability for in-the-wild measurements. In this paper we investigate the possibility to apply the novel Ultra-Wideband (UWB) localization technology as a scalable alternative for human motion capture in crowded and occlusion-prone environments. We include additional sensing modalities such as eye-tracking, onboard robot LiDAR and radar sensors, and record motion capture data as ground truth for evaluation and comparison. The environment imitates a museum setup, with up to four active participants navigating toward random goals in a natural way, and offers more than 130 minutes of multi-modal data. Our investigation provides a step toward scalable and accurate motion data collection beyond vision-based systems, laying a foundation for evaluating sensing modalities like UWB in larger and complex environments like warehouses, airports, or convention centers.
Context-Aware Human Behavior Prediction Using Multimodal Large Language Models: Challenges and Insights
Apr 01, 2025Predicting human behavior in shared environments is crucial for safe and efficient human-robot interaction. Traditional data-driven methods to that end are pre-trained on domain-specific datasets, activity types, and prediction horizons. In contrast, the recent breakthroughs in Large Language Models (LLMs) promise open-ended cross-domain generalization to describe various human activities and make predictions in any context. In particular, Multimodal LLMs (MLLMs) are able to integrate information from various sources, achieving more contextual awareness and improved scene understanding. The difficulty in applying general-purpose MLLMs directly for prediction stems from their limited capacity for processing large input sequences, sensitivity to prompt design, and expensive fine-tuning. In this paper, we present a systematic analysis of applying pre-trained MLLMs for context-aware human behavior prediction. To this end, we introduce a modular multimodal human activity prediction framework that allows us to benchmark various MLLMs, input variations, In-Context Learning (ICL), and autoregressive techniques. Our evaluation indicates that the best-performing framework configuration is able to reach 92.8% semantic similarity and 66.1% exact label accuracy in predicting human behaviors in the target frame.
Multimodal Interaction and Intention Communication for Industrial Robots
Feb 25, 2025

Successful adoption of industrial robots will strongly depend on their ability to safely and efficiently operate in human environments, engage in natural communication, understand their users, and express intentions intuitively while avoiding unnecessary distractions. To achieve this advanced level of Human-Robot Interaction (HRI), robots need to acquire and incorporate knowledge of their users' tasks and environment and adopt multimodal communication approaches with expressive cues that combine speech, movement, gazes, and other modalities. This paper presents several methods to design, enhance, and evaluate expressive HRI systems for non-humanoid industrial robots. We present the concept of a small anthropomorphic robot communicating as a proxy for its non-humanoid host, such as a forklift. We developed a multimodal and LLM-enhanced communication framework for this robot and evaluated it in several lab experiments, using gaze tracking and motion capture to quantify how users perceive the robot and measure the task progress.
Evaluating Efficiency and Engagement in Scripted and LLM-Enhanced Human-Robot Interactions
Jan 21, 2025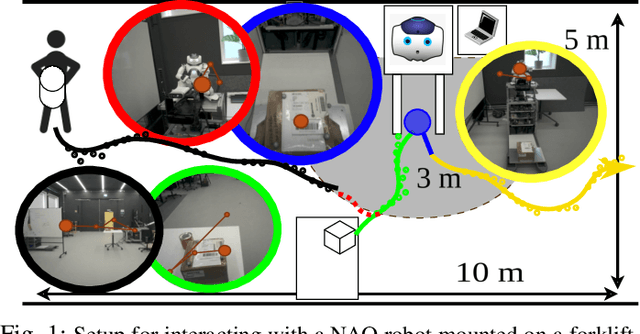
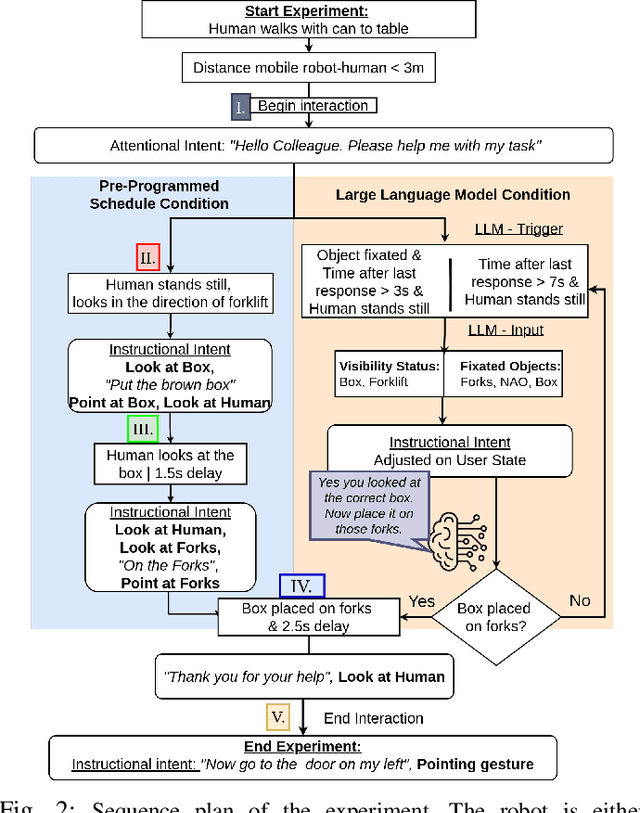

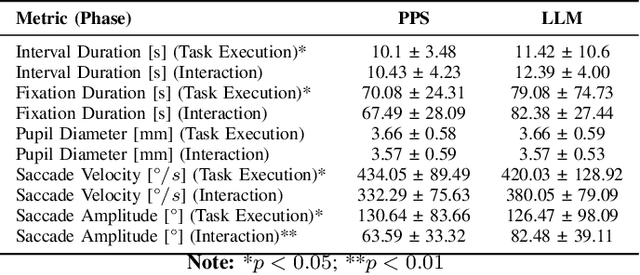
To achieve natural and intuitive interaction with people, HRI frameworks combine a wide array of methods for human perception, intention communication, human-aware navigation and collaborative action. In practice, when encountering unpredictable behavior of people or unexpected states of the environment, these frameworks may lack the ability to dynamically recognize such states, adapt and recover to resume the interaction. Large Language Models (LLMs), owing to their advanced reasoning capabilities and context retention, present a promising solution for enhancing robot adaptability. This potential, however, may not directly translate to improved interaction metrics. This paper considers a representative interaction with an industrial robot involving approach, instruction, and object manipulation, implemented in two conditions: (1) fully scripted and (2) including LLM-enhanced responses. We use gaze tracking and questionnaires to measure the participants' task efficiency, engagement, and robot perception. The results indicate higher subjective ratings for the LLM condition, but objective metrics show that the scripted condition performs comparably, particularly in efficiency and focus during simple tasks. We also note that the scripted condition may have an edge over LLM-enhanced responses in terms of response latency and energy consumption, especially for trivial and repetitive interactions.
THÖR-MAGNI Act: Actions for Human Motion Modeling in Robot-Shared Industrial Spaces
Dec 18, 2024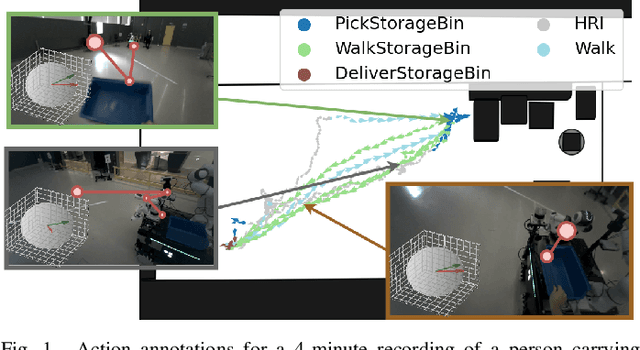
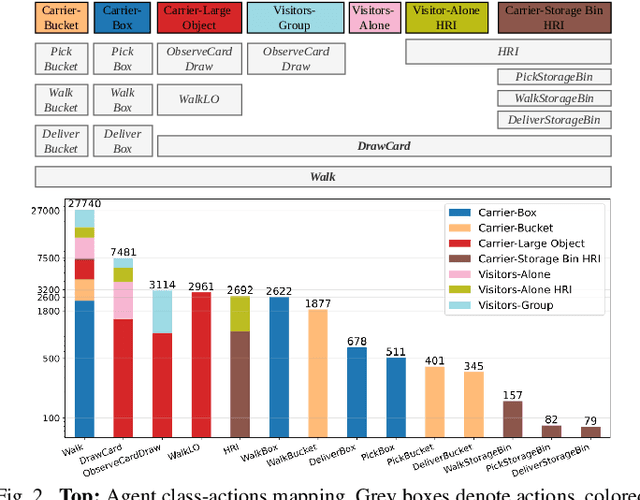
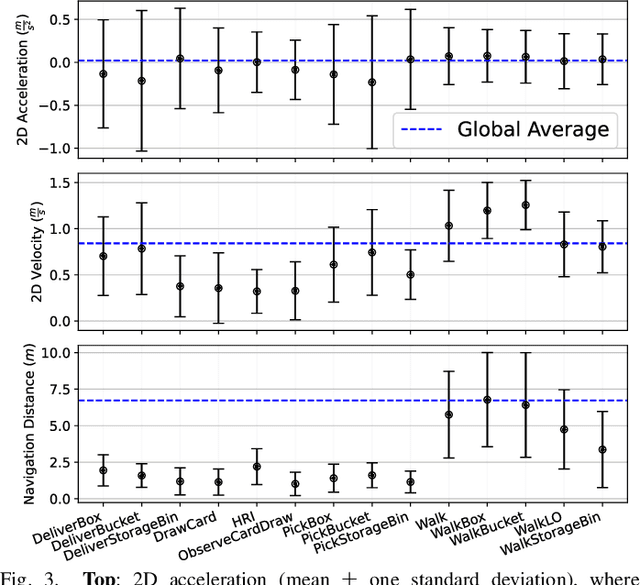
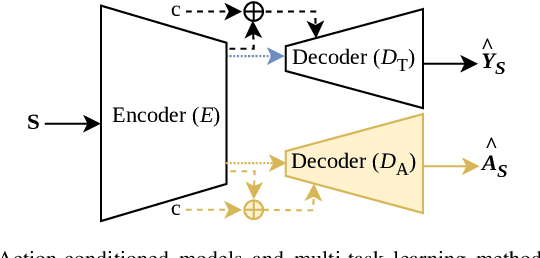
Accurate human activity and trajectory prediction are crucial for ensuring safe and reliable human-robot interactions in dynamic environments, such as industrial settings, with mobile robots. Datasets with fine-grained action labels for moving people in industrial environments with mobile robots are scarce, as most existing datasets focus on social navigation in public spaces. This paper introduces the TH\"OR-MAGNI Act dataset, a substantial extension of the TH\"OR-MAGNI dataset, which captures participant movements alongside robots in diverse semantic and spatial contexts. TH\"OR-MAGNI Act provides 8.3 hours of manually labeled participant actions derived from egocentric videos recorded via eye-tracking glasses. These actions, aligned with the provided TH\"OR-MAGNI motion cues, follow a long-tailed distribution with diversified acceleration, velocity, and navigation distance profiles. We demonstrate the utility of TH\"OR-MAGNI Act for two tasks: action-conditioned trajectory prediction and joint action and trajectory prediction. We propose two efficient transformer-based models that outperform the baselines to address these tasks. These results underscore the potential of TH\"OR-MAGNI Act to develop predictive models for enhanced human-robot interaction in complex environments.
Fast Online Learning of CLiFF-maps in Changing Environments
Oct 16, 2024
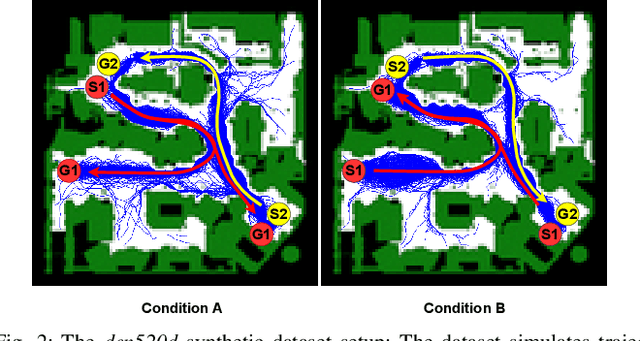
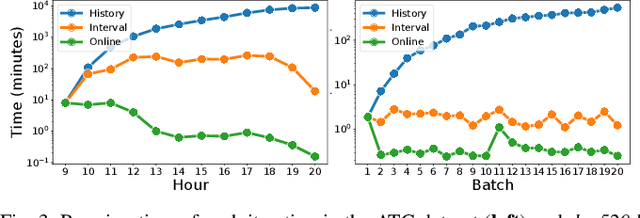

Maps of dynamics are effective representations of motion patterns learned from prior observations, with recent research demonstrating their ability to enhance performance in various downstream tasks such as human-aware robot navigation, long-term human motion prediction, and robot localization. Current advancements have primarily concentrated on methods for learning maps of human flow in environments where the flow is static, i.e., not assumed to change over time. In this paper we propose a method to update the CLiFF-map, one type of map of dynamics, for achieving efficient life-long robot operation. As new observations are collected, our goal is to update a CLiFF-map to effectively and accurately integrate new observations, while retaining relevant historic motion patterns. The proposed online update method maintains a probabilistic representation in each observed location, updating parameters by continuously tracking sufficient statistics. In experiments using both synthetic and real-world datasets, we show that our method is able to maintain accurate representations of human motion dynamics, contributing to high performance flow-compliant planning downstream tasks, while being orders of magnitude faster than the comparable baselines.
Bidirectional Intent Communication: A Role for Large Foundation Models
Aug 20, 2024Integrating multimodal foundation models has significantly enhanced autonomous agents' language comprehension, perception, and planning capabilities. However, while existing works adopt a \emph{task-centric} approach with minimal human interaction, applying these models to developing assistive \emph{user-centric} robots that can interact and cooperate with humans remains underexplored. This paper introduces ``Bident'', a framework designed to integrate robots seamlessly into shared spaces with humans. Bident enhances the interactive experience by incorporating multimodal inputs like speech and user gaze dynamics. Furthermore, Bident supports verbal utterances and physical actions like gestures, making it versatile for bidirectional human-robot interactions. Potential applications include personalized education, where robots can adapt to individual learning styles and paces, and healthcare, where robots can offer personalized support, companionship, and everyday assistance in the home and workplace environments.
Human Gaze and Head Rotation during Navigation, Exploration and Object Manipulation in Shared Environments with Robots
Jun 10, 2024
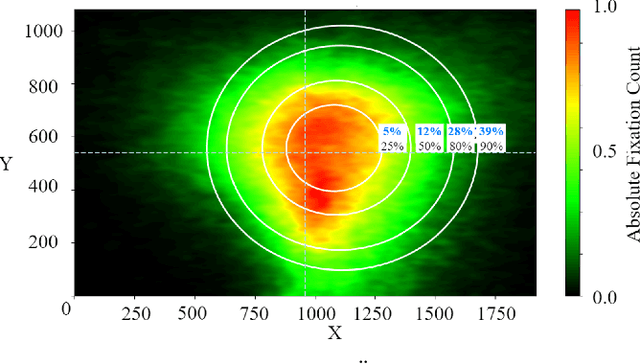
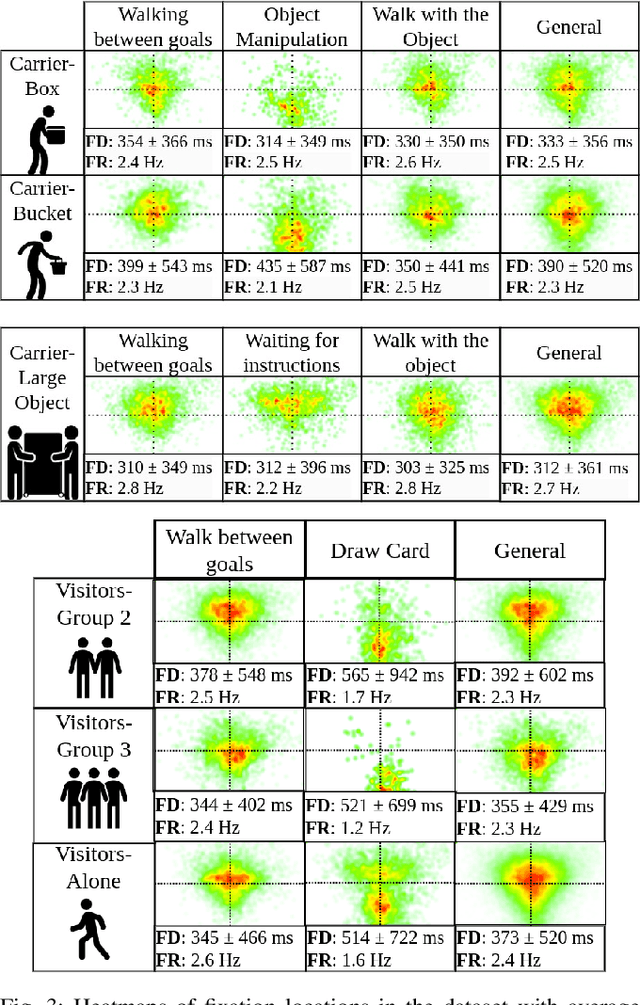
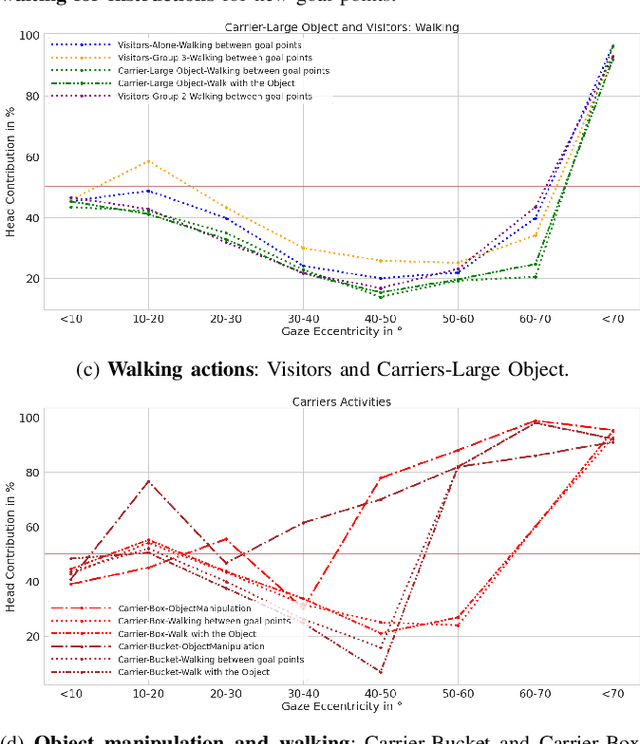
The human gaze is an important cue to signal intention, attention, distraction, and the regions of interest in the immediate surroundings. Gaze tracking can transform how robots perceive, understand, and react to people, enabling new modes of robot control, interaction, and collaboration. In this paper, we use gaze tracking data from a rich dataset of human motion (TH\"OR-MAGNI) to investigate the coordination between gaze direction and head rotation of humans engaged in various indoor activities involving navigation, interaction with objects, and collaboration with a mobile robot. In particular, we study the spread and central bias of fixations in diverse activities and examine the correlation between gaze direction and head rotation. We introduce various human motion metrics to enhance the understanding of gaze behavior in dynamic interactions. Finally, we apply semantic object labeling to decompose the gaze distribution into activity-relevant regions.
* This is the final version of the accepted version of the manuscript that will be published in the 2024 33rd IEEE International Conference on Robot and Human Interactive Communication (ROMAN). Copyright 2024 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses