 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Cooperative Drone Tracking for Open-Path Gas Measurements
Feb 24, 2026Open-path Tunable Diode Laser Absorption Spectroscopy offers an effective method for measuring, mapping, and monitoring gas concentrations, such as leaking CO2 or methane. Compared to spatial sampling of gas distributions using in-situ sensors, open-path sensors in combination with gas tomography algorithms can cover large outdoor environments faster in a non-invasive way. However, the requirement of a dedicated reflection surface for the open-path laser makes automating the spatial sampling process challenging. This publication presents a robotic system for collecting open-path measurements, making use of a sensor mounted on a ground-based pan-tilt unit and a small drone carrying a reflector. By means of a zoom camera, the ground unit visually tracks red LED markers mounted on the drone and aligns the sensor's laser beam with the reflector. Incorporating GNSS position information provided by the drone's flight controller further improves the tracking approach. Outdoor experiments validated the system's performance, demonstrating successful autonomous tracking and valid CO2 measurements at distances up to 60 meters. Furthermore, the system successfully measured a CO2 plume without interference from the drone's propulsion system, demonstrating its superiority compared to flying in-situ sensors.
Collecting Human Motion Data in Large and Occlusion-Prone Environments using Ultra-Wideband Localization
May 09, 2025With robots increasingly integrating into human environments, understanding and predicting human motion is essential for safe and efficient interactions. Modern human motion and activity prediction approaches require high quality and quantity of data for training and evaluation, usually collected from motion capture systems, onboard or stationary sensors. Setting up these systems is challenging due to the intricate setup of hardware components, extensive calibration procedures, occlusions, and substantial costs. These constraints make deploying such systems in new and large environments difficult and limit their usability for in-the-wild measurements. In this paper we investigate the possibility to apply the novel Ultra-Wideband (UWB) localization technology as a scalable alternative for human motion capture in crowded and occlusion-prone environments. We include additional sensing modalities such as eye-tracking, onboard robot LiDAR and radar sensors, and record motion capture data as ground truth for evaluation and comparison. The environment imitates a museum setup, with up to four active participants navigating toward random goals in a natural way, and offers more than 130 minutes of multi-modal data. Our investigation provides a step toward scalable and accurate motion data collection beyond vision-based systems, laying a foundation for evaluating sensing modalities like UWB in larger and complex environments like warehouses, airports, or convention centers.
Large-scale visual SLAM for in-the-wild videos
Apr 29, 2025Accurate and robust 3D scene reconstruction from casual, in-the-wild videos can significantly simplify robot deployment to new environments. However, reliable camera pose estimation and scene reconstruction from such unconstrained videos remains an open challenge. Existing visual-only SLAM methods perform well on benchmark datasets but struggle with real-world footage which often exhibits uncontrolled motion including rapid rotations and pure forward movements, textureless regions, and dynamic objects. We analyze the limitations of current methods and introduce a robust pipeline designed to improve 3D reconstruction from casual videos. We build upon recent deep visual odometry methods but increase robustness in several ways. Camera intrinsics are automatically recovered from the first few frames using structure-from-motion. Dynamic objects and less-constrained areas are masked with a predictive model. Additionally, we leverage monocular depth estimates to regularize bundle adjustment, mitigating errors in low-parallax situations. Finally, we integrate place recognition and loop closure to reduce long-term drift and refine both intrinsics and pose estimates through global bundle adjustment. We demonstrate large-scale contiguous 3D models from several online videos in various environments. In contrast, baseline methods typically produce locally inconsistent results at several points, producing separate segments or distorted maps. In lieu of ground-truth pose data, we evaluate map consistency, execution time and visual accuracy of re-rendered NeRF models. Our proposed system establishes a new baseline for visual reconstruction from casual uncontrolled videos found online, demonstrating more consistent reconstructions over longer sequences of in-the-wild videos than previously achieved.
Introspective Loop Closure for SLAM with 4D Imaging Radar
Mar 04, 2025Simultaneous Localization and Mapping (SLAM) allows mobile robots to navigate without external positioning systems or pre-existing maps. Radar is emerging as a valuable sensing tool, especially in vision-obstructed environments, as it is less affected by particles than lidars or cameras. Modern 4D imaging radars provide three-dimensional geometric information and relative velocity measurements, but they bring challenges, such as a small field of view and sparse, noisy point clouds. Detecting loop closures in SLAM is critical for reducing trajectory drift and maintaining map accuracy. However, the directional nature of 4D radar data makes identifying loop closures, especially from reverse viewpoints, difficult due to limited scan overlap. This article explores using 4D radar for loop closure in SLAM, focusing on similar and opposing viewpoints. We generate submaps for a denser environment representation and use introspective measures to reject false detections in feature-degenerate environments. Our experiments show accurate loop closure detection in geometrically diverse settings for both similar and opposing viewpoints, improving trajectory estimation with up to 82 % improvement in ATE and rejecting false positives in self-similar environments.
Multimodal Interaction and Intention Communication for Industrial Robots
Feb 25, 2025

Successful adoption of industrial robots will strongly depend on their ability to safely and efficiently operate in human environments, engage in natural communication, understand their users, and express intentions intuitively while avoiding unnecessary distractions. To achieve this advanced level of Human-Robot Interaction (HRI), robots need to acquire and incorporate knowledge of their users' tasks and environment and adopt multimodal communication approaches with expressive cues that combine speech, movement, gazes, and other modalities. This paper presents several methods to design, enhance, and evaluate expressive HRI systems for non-humanoid industrial robots. We present the concept of a small anthropomorphic robot communicating as a proxy for its non-humanoid host, such as a forklift. We developed a multimodal and LLM-enhanced communication framework for this robot and evaluated it in several lab experiments, using gaze tracking and motion capture to quantify how users perceive the robot and measure the task progress.
Evaluating Efficiency and Engagement in Scripted and LLM-Enhanced Human-Robot Interactions
Jan 21, 2025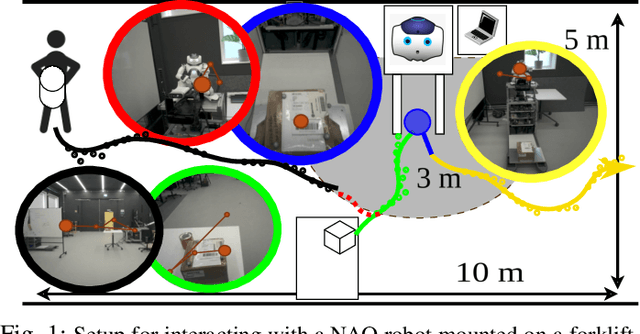
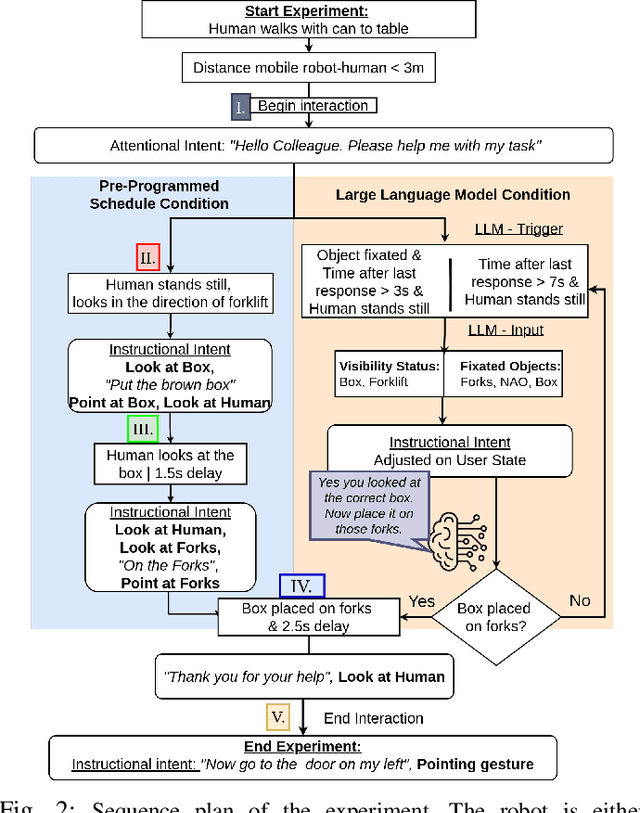

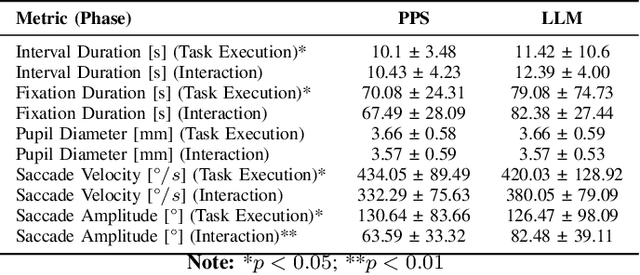
To achieve natural and intuitive interaction with people, HRI frameworks combine a wide array of methods for human perception, intention communication, human-aware navigation and collaborative action. In practice, when encountering unpredictable behavior of people or unexpected states of the environment, these frameworks may lack the ability to dynamically recognize such states, adapt and recover to resume the interaction. Large Language Models (LLMs), owing to their advanced reasoning capabilities and context retention, present a promising solution for enhancing robot adaptability. This potential, however, may not directly translate to improved interaction metrics. This paper considers a representative interaction with an industrial robot involving approach, instruction, and object manipulation, implemented in two conditions: (1) fully scripted and (2) including LLM-enhanced responses. We use gaze tracking and questionnaires to measure the participants' task efficiency, engagement, and robot perception. The results indicate higher subjective ratings for the LLM condition, but objective metrics show that the scripted condition performs comparably, particularly in efficiency and focus during simple tasks. We also note that the scripted condition may have an edge over LLM-enhanced responses in terms of response latency and energy consumption, especially for trivial and repetitive interactions.
THÖR-MAGNI Act: Actions for Human Motion Modeling in Robot-Shared Industrial Spaces
Dec 18, 2024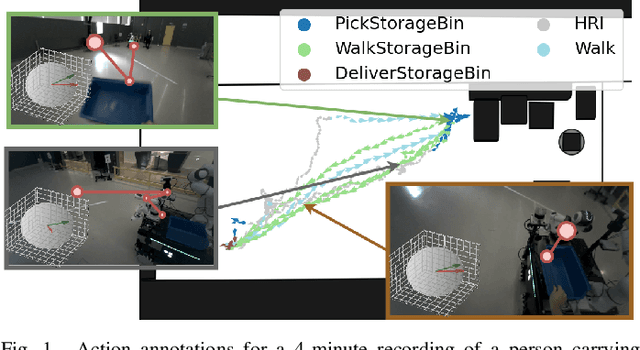
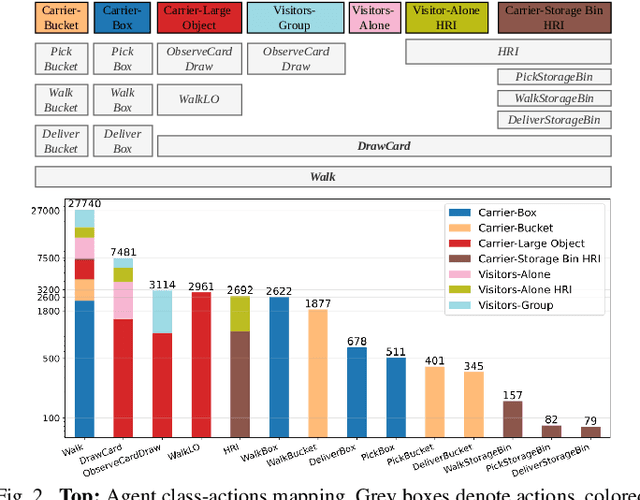
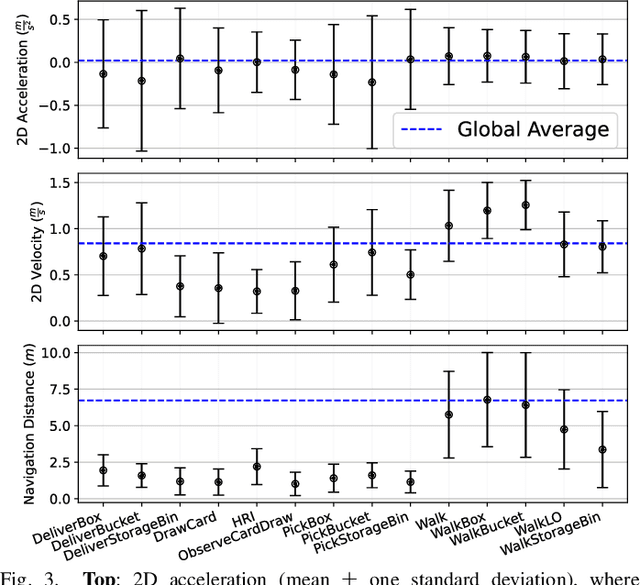
Accurate human activity and trajectory prediction are crucial for ensuring safe and reliable human-robot interactions in dynamic environments, such as industrial settings, with mobile robots. Datasets with fine-grained action labels for moving people in industrial environments with mobile robots are scarce, as most existing datasets focus on social navigation in public spaces. This paper introduces the TH\"OR-MAGNI Act dataset, a substantial extension of the TH\"OR-MAGNI dataset, which captures participant movements alongside robots in diverse semantic and spatial contexts. TH\"OR-MAGNI Act provides 8.3 hours of manually labeled participant actions derived from egocentric videos recorded via eye-tracking glasses. These actions, aligned with the provided TH\"OR-MAGNI motion cues, follow a long-tailed distribution with diversified acceleration, velocity, and navigation distance profiles. We demonstrate the utility of TH\"OR-MAGNI Act for two tasks: action-conditioned trajectory prediction and joint action and trajectory prediction. We propose two efficient transformer-based models that outperform the baselines to address these tasks. These results underscore the potential of TH\"OR-MAGNI Act to develop predictive models for enhanced human-robot interaction in complex environments.
Fast Online Learning of CLiFF-maps in Changing Environments
Oct 16, 2024
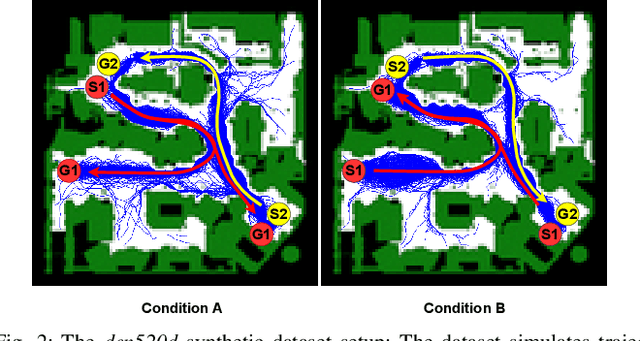
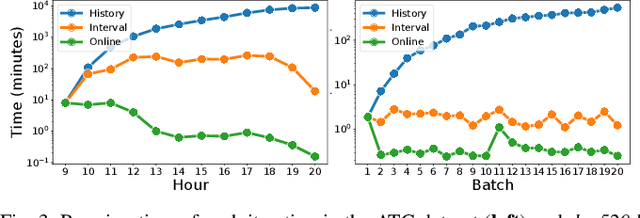

Maps of dynamics are effective representations of motion patterns learned from prior observations, with recent research demonstrating their ability to enhance performance in various downstream tasks such as human-aware robot navigation, long-term human motion prediction, and robot localization. Current advancements have primarily concentrated on methods for learning maps of human flow in environments where the flow is static, i.e., not assumed to change over time. In this paper we propose a method to update the CLiFF-map, one type of map of dynamics, for achieving efficient life-long robot operation. As new observations are collected, our goal is to update a CLiFF-map to effectively and accurately integrate new observations, while retaining relevant historic motion patterns. The proposed online update method maintains a probabilistic representation in each observed location, updating parameters by continuously tracking sufficient statistics. In experiments using both synthetic and real-world datasets, we show that our method is able to maintain accurate representations of human motion dynamics, contributing to high performance flow-compliant planning downstream tasks, while being orders of magnitude faster than the comparable baselines.
Human Gaze and Head Rotation during Navigation, Exploration and Object Manipulation in Shared Environments with Robots
Jun 10, 2024
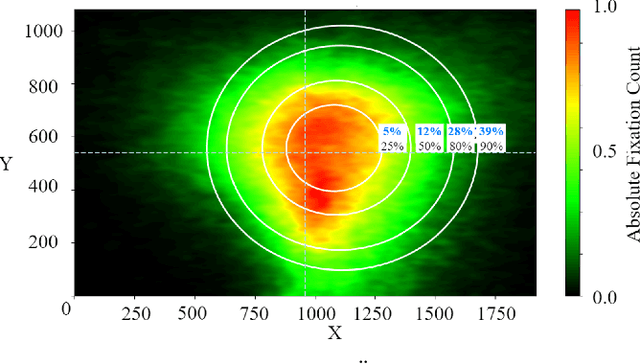
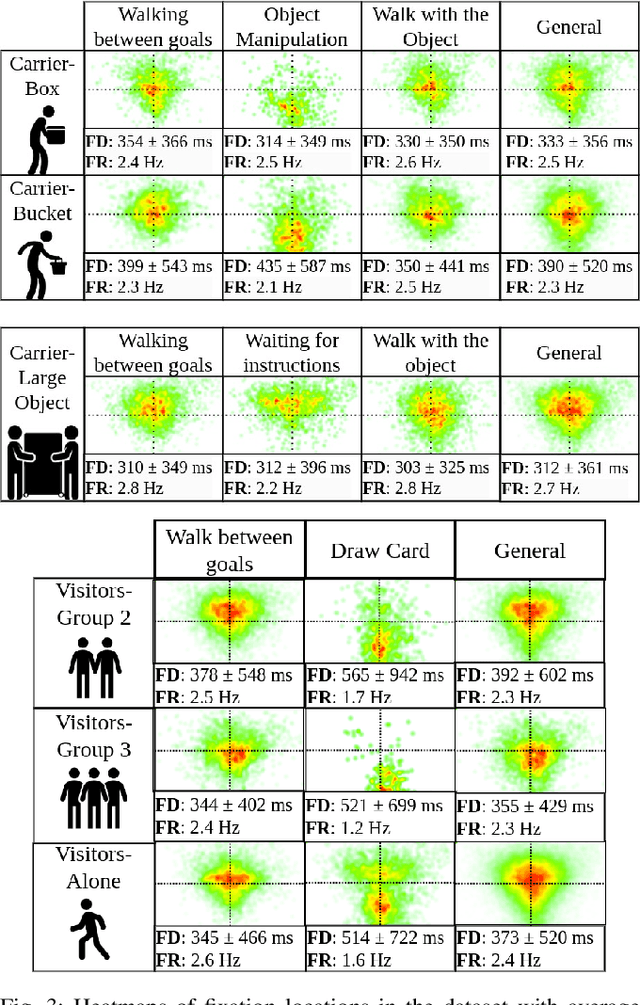
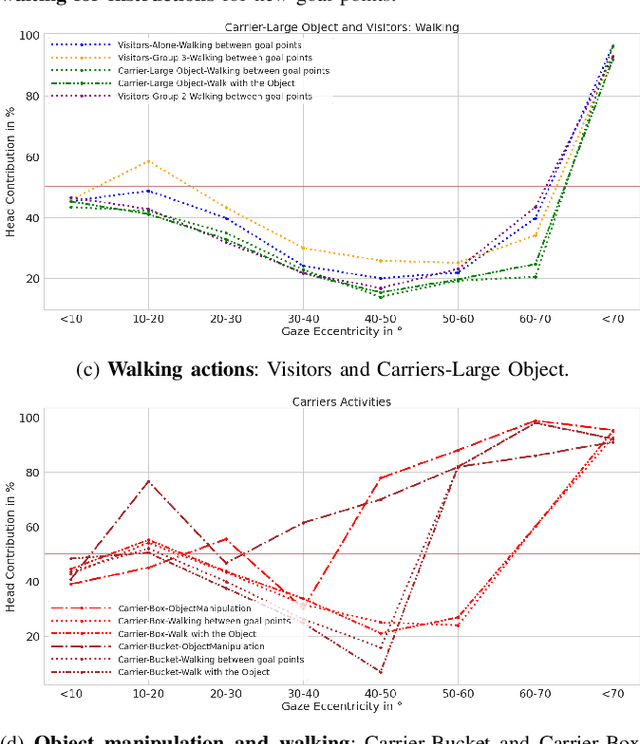
The human gaze is an important cue to signal intention, attention, distraction, and the regions of interest in the immediate surroundings. Gaze tracking can transform how robots perceive, understand, and react to people, enabling new modes of robot control, interaction, and collaboration. In this paper, we use gaze tracking data from a rich dataset of human motion (TH\"OR-MAGNI) to investigate the coordination between gaze direction and head rotation of humans engaged in various indoor activities involving navigation, interaction with objects, and collaboration with a mobile robot. In particular, we study the spread and central bias of fixations in diverse activities and examine the correlation between gaze direction and head rotation. We introduce various human motion metrics to enhance the understanding of gaze behavior in dynamic interactions. Finally, we apply semantic object labeling to decompose the gaze distribution into activity-relevant regions.
* This is the final version of the accepted version of the manuscript that will be published in the 2024 33rd IEEE International Conference on Robot and Human Interactive Communication (ROMAN). Copyright 2024 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses
The Child Factor in Child-Robot Interaction: Discovering the Impact of Developmental Stage and Individual Characteristics
Apr 20, 2024
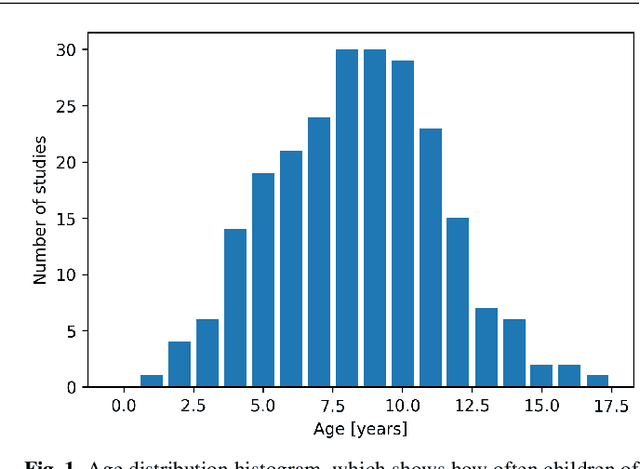
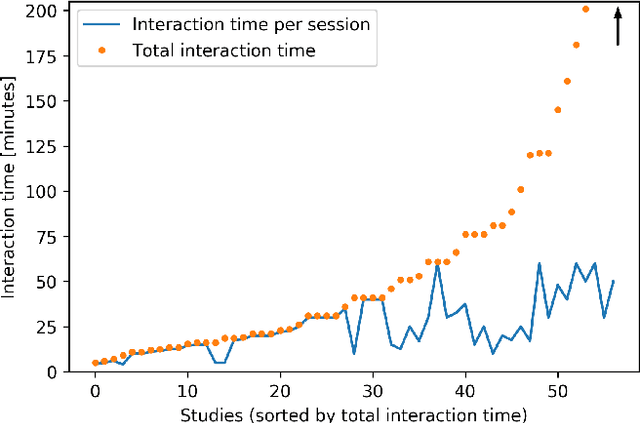
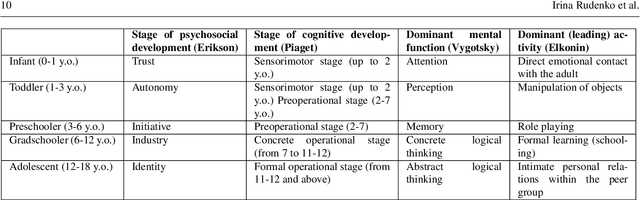
Social robots, owing to their embodied physical presence in human spaces and the ability to directly interact with the users and their environment, have a great potential to support children in various activities in education, healthcare and daily life. Child-Robot Interaction (CRI), as any domain involving children, inevitably faces the major challenge of designing generalized strategies to work with unique, turbulent and very diverse individuals. Addressing this challenging endeavor requires to combine the standpoint of the robot-centered perspective, i.e. what robots technically can and are best positioned to do, with that of the child-centered perspective, i.e. what children may gain from the robot and how the robot should act to best support them in reaching the goals of the interaction. This article aims to help researchers bridge the two perspectives and proposes to address the development of CRI scenarios with insights from child psychology and child development theories. To that end, we review the outcomes of the CRI studies, outline common trends and challenges, and identify two key factors from child psychology that impact child-robot interactions, especially in a long-term perspective: developmental stage and individual characteristics. For both of them we discuss prospective experiment designs which support building naturally engaging and sustainable interactions.