 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConflict Mitigation in Shared Environments using Flow-Aware Multi-Agent Path Finding
Mar 13, 2026Deploying multi-robot systems in environments shared with dynamic and uncontrollable agents presents significant challenges, especially for large robot fleets. In such environments, individual robot operations can be delayed due to unforeseen conflicts with uncontrollable agents. While existing research primarily focuses on preserving the completeness of Multi-Agent Path Finding (MAPF) solutions considering delays, there is limited emphasis on utilizing additional environmental information to enhance solution quality in the presence of other dynamic agents. To this end, we propose Flow-Aware Multi-Agent Path Finding (FA-MAPF), a novel framework that integrates learned motion patterns of uncontrollable agents into centralized MAPF algorithms. Our evaluation, conducted on a diverse set of benchmark maps with simulated uncontrollable agents and on a real-world map with recorded human trajectories, demonstrates the effectiveness of FA-MAPF compared to state-of-the-art baselines. The experimental results show that FA-MAPF can consistently reduce conflicts with uncontrollable agents, up to 55%, without compromising task efficiency.
HiCrowd: Hierarchical Crowd Flow Alignment for Dense Human Environments
Feb 05, 2026Navigating through dense human crowds remains a significant challenge for mobile robots. A key issue is the freezing robot problem, where the robot struggles to find safe motions and becomes stuck within the crowd. To address this, we propose HiCrowd, a hierarchical framework that integrates reinforcement learning (RL) with model predictive control (MPC). HiCrowd leverages surrounding pedestrian motion as guidance, enabling the robot to align with compatible crowd flows. A high-level RL policy generates a follow point to align the robot with a suitable pedestrian group, while a low-level MPC safely tracks this guidance with short horizon planning. The method combines long-term crowd aware decision making with safe short-term execution. We evaluate HiCrowd against reactive and learning-based baselines in offline setting (replaying recorded human trajectories) and online setting (human trajectories are updated to react to the robot in simulation). Experiments on a real-world dataset and a synthetic crowd dataset show that our method outperforms in navigation efficiency and safety, while reducing freezing behaviors. Our results suggest that leveraging human motion as guidance, rather than treating humans solely as dynamic obstacles, provides a powerful principle for safe and efficient robot navigation in crowds.
Template-Guided Reconstruction of Pulmonary Segments with Neural Implicit Functions
May 13, 2025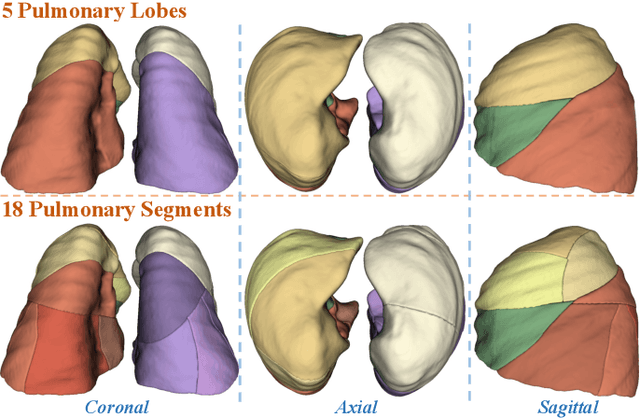
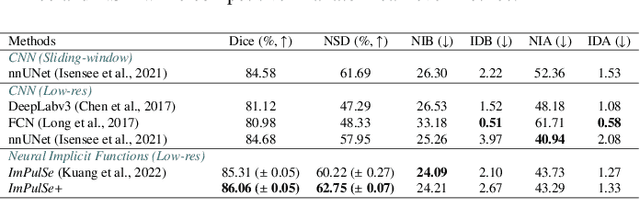
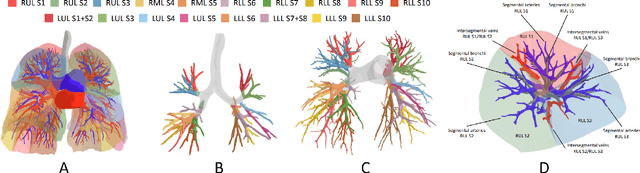
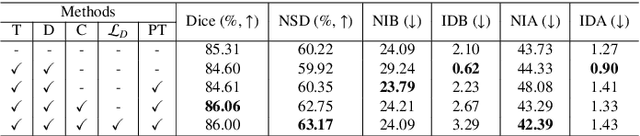
High-quality 3D reconstruction of pulmonary segments plays a crucial role in segmentectomy and surgical treatment planning for lung cancer. Due to the resolution requirement of the target reconstruction, conventional deep learning-based methods often suffer from computational resource constraints or limited granularity. Conversely, implicit modeling is favored due to its computational efficiency and continuous representation at any resolution. We propose a neural implicit function-based method to learn a 3D surface to achieve anatomy-aware, precise pulmonary segment reconstruction, represented as a shape by deforming a learnable template. Additionally, we introduce two clinically relevant evaluation metrics to assess the reconstruction comprehensively. Further, due to the absence of publicly available shape datasets to benchmark reconstruction algorithms, we developed a shape dataset named Lung3D, including the 3D models of 800 labeled pulmonary segments and the corresponding airways, arteries, veins, and intersegmental veins. We demonstrate that the proposed approach outperforms existing methods, providing a new perspective for pulmonary segment reconstruction. Code and data will be available at https://github.com/M3DV/ImPulSe.
Towards Dataset Copyright Evasion Attack against Personalized Text-to-Image Diffusion Models
May 05, 2025Text-to-image (T2I) diffusion models have rapidly advanced, enabling high-quality image generation conditioned on textual prompts. However, the growing trend of fine-tuning pre-trained models for personalization raises serious concerns about unauthorized dataset usage. To combat this, dataset ownership verification (DOV) has emerged as a solution, embedding watermarks into the fine-tuning datasets using backdoor techniques. These watermarks remain inactive under benign samples but produce owner-specified outputs when triggered. Despite the promise of DOV for T2I diffusion models, its robustness against copyright evasion attacks (CEA) remains unexplored. In this paper, we explore how attackers can bypass these mechanisms through CEA, allowing models to circumvent watermarks even when trained on watermarked datasets. We propose the first copyright evasion attack (i.e., CEAT2I) specifically designed to undermine DOV in T2I diffusion models. Concretely, our CEAT2I comprises three stages: watermarked sample detection, trigger identification, and efficient watermark mitigation. A key insight driving our approach is that T2I models exhibit faster convergence on watermarked samples during the fine-tuning, evident through intermediate feature deviation. Leveraging this, CEAT2I can reliably detect the watermarked samples. Then, we iteratively ablate tokens from the prompts of detected watermarked samples and monitor shifts in intermediate features to pinpoint the exact trigger tokens. Finally, we adopt a closed-form concept erasure method to remove the injected watermark. Extensive experiments show that our CEAT2I effectively evades DOV mechanisms while preserving model performance.
EvolvingGrasp: Evolutionary Grasp Generation via Efficient Preference Alignment
Mar 19, 2025



Dexterous robotic hands often struggle to generalize effectively in complex environments due to the limitations of models trained on low-diversity data. However, the real world presents an inherently unbounded range of scenarios, making it impractical to account for every possible variation. A natural solution is to enable robots learning from experience in complex environments, an approach akin to evolution, where systems improve through continuous feedback, learning from both failures and successes, and iterating toward optimal performance. Motivated by this, we propose EvolvingGrasp, an evolutionary grasp generation method that continuously enhances grasping performance through efficient preference alignment. Specifically, we introduce Handpose wise Preference Optimization (HPO), which allows the model to continuously align with preferences from both positive and negative feedback while progressively refining its grasping strategies. To further enhance efficiency and reliability during online adjustments, we incorporate a Physics-aware Consistency Model within HPO, which accelerates inference, reduces the number of timesteps needed for preference finetuning, and ensures physical plausibility throughout the process. Extensive experiments across four benchmark datasets demonstrate state of the art performance of our method in grasp success rate and sampling efficiency. Our results validate that EvolvingGrasp enables evolutionary grasp generation, ensuring robust, physically feasible, and preference-aligned grasping in both simulation and real scenarios.
Diffusion Prior Interpolation for Flexibility Real-World Face Super-Resolution
Dec 21, 2024
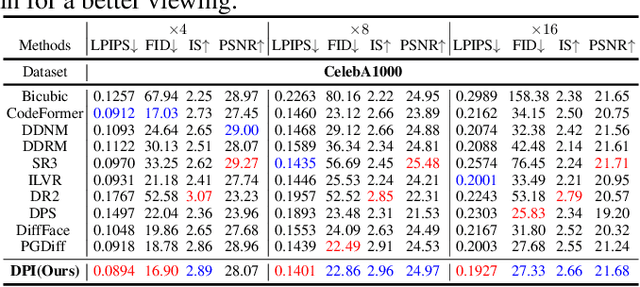
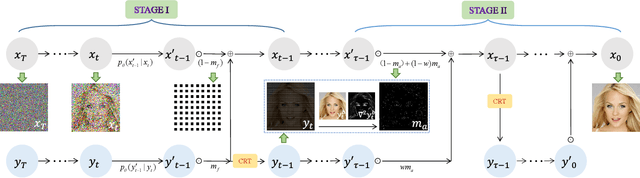
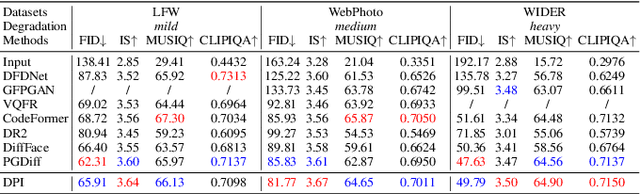
Diffusion models represent the state-of-the-art in generative modeling. Due to their high training costs, many works leverage pre-trained diffusion models' powerful representations for downstream tasks, such as face super-resolution (FSR), through fine-tuning or prior-based methods. However, relying solely on priors without supervised training makes it challenging to meet the pixel-level accuracy requirements of discrimination task. Although prior-based methods can achieve high fidelity and high-quality results, ensuring consistency remains a significant challenge. In this paper, we propose a masking strategy with strong and weak constraints and iterative refinement for real-world FSR, termed Diffusion Prior Interpolation (DPI). We introduce conditions and constraints on consistency by masking different sampling stages based on the structural characteristics of the face. Furthermore, we propose a condition Corrector (CRT) to establish a reciprocal posterior sampling process, enhancing FSR performance by mutual refinement of conditions and samples. DPI can balance consistency and diversity and can be seamlessly integrated into pre-trained models. In extensive experiments conducted on synthetic and real datasets, along with consistency validation in face recognition, DPI demonstrates superiority over SOTA FSR methods. The code is available at \url{https://github.com/JerryYann/DPI}.
Fast Online Learning of CLiFF-maps in Changing Environments
Oct 16, 2024
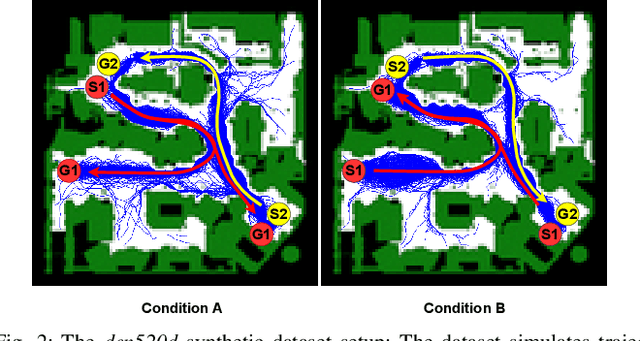
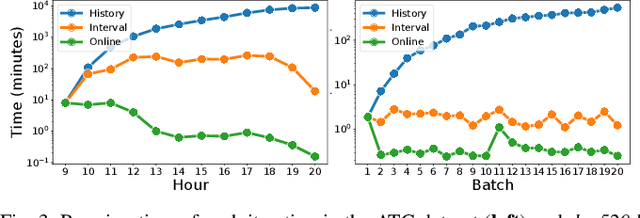

Maps of dynamics are effective representations of motion patterns learned from prior observations, with recent research demonstrating their ability to enhance performance in various downstream tasks such as human-aware robot navigation, long-term human motion prediction, and robot localization. Current advancements have primarily concentrated on methods for learning maps of human flow in environments where the flow is static, i.e., not assumed to change over time. In this paper we propose a method to update the CLiFF-map, one type of map of dynamics, for achieving efficient life-long robot operation. As new observations are collected, our goal is to update a CLiFF-map to effectively and accurately integrate new observations, while retaining relevant historic motion patterns. The proposed online update method maintains a probabilistic representation in each observed location, updating parameters by continuously tracking sufficient statistics. In experiments using both synthetic and real-world datasets, we show that our method is able to maintain accurate representations of human motion dynamics, contributing to high performance flow-compliant planning downstream tasks, while being orders of magnitude faster than the comparable baselines.
The Role of Network and Identity in the Diffusion of Hashtags
Jul 17, 2024


Although the spread of behaviors is influenced by many social factors, existing literature tends to study the effects of single factors -- most often, properties of the social network -- on the final cascade. In order to move towards a more integrated view of cascades, this paper offers the first comprehensive investigation into the role of two social factors in the diffusion of 1,337 popular hashtags representing the production of novel culture on Twitter: 1) the topology of the Twitter social network and 2) performance of each user's probable demographic identity. Here, we show that cascades are best modeled using a combination of network and identity, rather than either factor alone. This combined model best reproduces a composite index of ten cascade properties across all 1,337 hashtags. However, there is important heterogeneity in what social factors are required to reproduce different properties of hashtag cascades. For instance, while a combined network+identity model best predicts the popularity of cascades, a network-only model has better performance in predicting cascade growth and an identity-only model in adopter composition. We are able to predict what type of hashtag is best modeled by each combination of features and use this to further improve performance. Additionally, consistent with prior literature on the combined network+identity model most outperforms the single-factor counterfactuals among hashtags used for expressing racial or regional identity, stance-taking, talking about sports, or variants of existing cultural trends with very slow- or fast-growing communicative need. In sum, our results imply the utility of multi-factor models in predicting cascades, in order to account for the varied ways in which network, identity, and other social factors play a role in the diffusion of hashtags on Twitter.
LaCE-LHMP: Airflow Modelling-Inspired Long-Term Human Motion Prediction By Enhancing Laminar Characteristics in Human Flow
Mar 20, 2024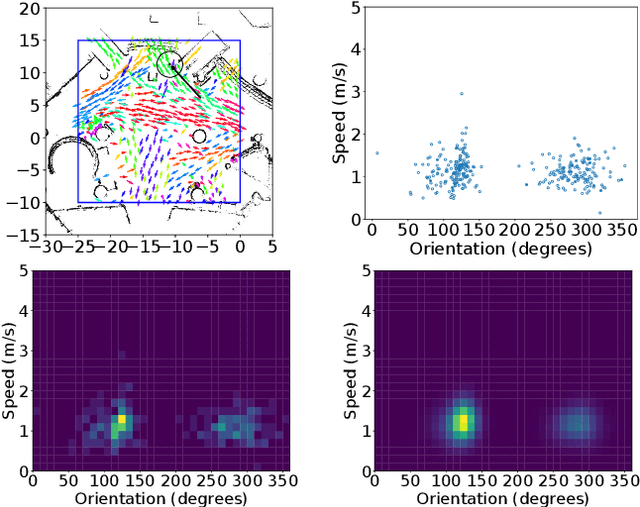
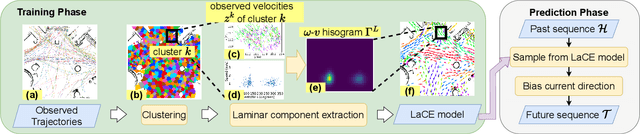
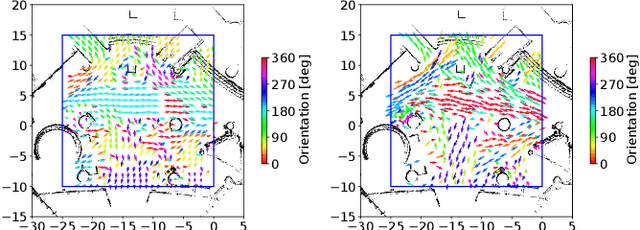
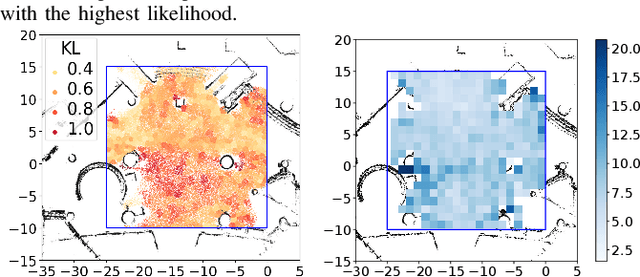
Long-term human motion prediction (LHMP) is essential for safely operating autonomous robots and vehicles in populated environments. It is fundamental for various applications, including motion planning, tracking, human-robot interaction and safety monitoring. However, accurate prediction of human trajectories is challenging due to complex factors, including, for example, social norms and environmental conditions. The influence of such factors can be captured through Maps of Dynamics (MoDs), which encode spatial motion patterns learned from (possibly scattered and partial) past observations of motion in the environment and which can be used for data-efficient, interpretable motion prediction (MoD-LHMP). To address the limitations of prior work, especially regarding accuracy and sensitivity to anomalies in long-term prediction, we propose the Laminar Component Enhanced LHMP approach (LaCE-LHMP). Our approach is inspired by data-driven airflow modelling, which estimates laminar and turbulent flow components and uses predominantly the laminar components to make flow predictions. Based on the hypothesis that human trajectory patterns also manifest laminar flow (that represents predictable motion) and turbulent flow components (that reflect more unpredictable and arbitrary motion), LaCE-LHMP extracts the laminar patterns in human dynamics and uses them for human motion prediction. We demonstrate the superior prediction performance of LaCE-LHMP through benchmark comparisons with state-of-the-art LHMP methods, offering an unconventional perspective and a more intuitive understanding of human movement patterns.
THÖR-MAGNI: A Large-scale Indoor Motion Capture Recording of Human Movement and Robot Interaction
Mar 14, 2024



We present a new large dataset of indoor human and robot navigation and interaction, called TH\"OR-MAGNI, that is designed to facilitate research on social navigation: e.g., modelling and predicting human motion, analyzing goal-oriented interactions between humans and robots, and investigating visual attention in a social interaction context. TH\"OR-MAGNI was created to fill a gap in available datasets for human motion analysis and HRI. This gap is characterized by a lack of comprehensive inclusion of exogenous factors and essential target agent cues, which hinders the development of robust models capable of capturing the relationship between contextual cues and human behavior in different scenarios. Unlike existing datasets, TH\"OR-MAGNI includes a broader set of contextual features and offers multiple scenario variations to facilitate factor isolation. The dataset includes many social human-human and human-robot interaction scenarios, rich context annotations, and multi-modal data, such as walking trajectories, gaze tracking data, and lidar and camera streams recorded from a mobile robot. We also provide a set of tools for visualization and processing of the recorded data. TH\"OR-MAGNI is, to the best of our knowledge, unique in the amount and diversity of sensor data collected in a contextualized and socially dynamic environment, capturing natural human-robot interactions.