 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Context Bridge the Reality Gap? Sim-to-Real Transfer of Context-Aware Policies
Nov 06, 2025Sim-to-real transfer remains a major challenge in reinforcement learning (RL) for robotics, as policies trained in simulation often fail to generalize to the real world due to discrepancies in environment dynamics. Domain Randomization (DR) mitigates this issue by exposing the policy to a wide range of randomized dynamics during training, yet leading to a reduction in performance. While standard approaches typically train policies agnostic to these variations, we investigate whether sim-to-real transfer can be improved by conditioning the policy on an estimate of the dynamics parameters -- referred to as context. To this end, we integrate a context estimation module into a DR-based RL framework and systematically compare SOTA supervision strategies. We evaluate the resulting context-aware policies in both a canonical control benchmark and a real-world pushing task using a Franka Emika Panda robot. Results show that context-aware policies outperform the context-agnostic baseline across all settings, although the best supervision strategy depends on the task.
Inverse Optimization Latent Variable Models for Learning Costs Applied to Route Problems
Sep 19, 2025Learning representations for solutions of constrained optimization problems (COPs) with unknown cost functions is challenging, as models like (Variational) Autoencoders struggle to enforce constraints when decoding structured outputs. We propose an Inverse Optimization Latent Variable Model (IO-LVM) that learns a latent space of COP cost functions from observed solutions and reconstructs feasible outputs by solving a COP with a solver in the loop. Our approach leverages estimated gradients of a Fenchel-Young loss through a non-differentiable deterministic solver to shape the latent space. Unlike standard Inverse Optimization or Inverse Reinforcement Learning methods, which typically recover a single or context-specific cost function, IO-LVM captures a distribution over cost functions, enabling the identification of diverse solution behaviors arising from different agents or conditions not available during the training process. We validate our method on real-world datasets of ship and taxi routes, as well as paths in synthetic graphs, demonstrating its ability to reconstruct paths and cycles, predict their distributions, and yield interpretable latent representations.
DFW: A Novel Weighting Scheme for Covariate Balancing and Treatment Effect Estimation
Aug 07, 2025Estimating causal effects from observational data is challenging due to selection bias, which leads to imbalanced covariate distributions across treatment groups. Propensity score-based weighting methods are widely used to address this issue by reweighting samples to simulate a randomized controlled trial (RCT). However, the effectiveness of these methods heavily depends on the observed data and the accuracy of the propensity score estimator. For example, inverse propensity weighting (IPW) assigns weights based on the inverse of the propensity score, which can lead to instable weights when propensity scores have high variance-either due to data or model misspecification-ultimately degrading the ability of handling selection bias and treatment effect estimation. To overcome these limitations, we propose Deconfounding Factor Weighting (DFW), a novel propensity score-based approach that leverages the deconfounding factor-to construct stable and effective sample weights. DFW prioritizes less confounded samples while mitigating the influence of highly confounded ones, producing a pseudopopulation that better approximates a RCT. Our approach ensures bounded weights, lower variance, and improved covariate balance.While DFW is formulated for binary treatments, it naturally extends to multi-treatment settings, as the deconfounding factor is computed based on the estimated probability of the treatment actually received by each sample. Through extensive experiments on real-world benchmark and synthetic datasets, we demonstrate that DFW outperforms existing methods, including IPW and CBPS, in both covariate balancing and treatment effect estimation.
ZipMPC: Compressed Context-Dependent MPC Cost via Imitation Learning
Jul 17, 2025The computational burden of model predictive control (MPC) limits its application on real-time systems, such as robots, and often requires the use of short prediction horizons. This not only affects the control performance, but also increases the difficulty of designing MPC cost functions that reflect the desired long-term objective. This paper proposes ZipMPC, a method that imitates a long-horizon MPC behaviour by learning a compressed and context-dependent cost function for a short-horizon MPC. It improves performance over alternative methods, such as approximate explicit MPC and automatic cost parameter tuning, in particular in terms of i) optimizing the long term objective; ii) maintaining computational costs comparable to a short-horizon MPC; iii) ensuring constraint satisfaction; and iv) generalizing control behaviour to environments not observed during training. For this purpose, ZipMPC leverages the concept of differentiable MPC with neural networks to propagate gradients of the imitation loss through the MPC optimization. We validate our proposed method in simulation and real-world experiments on autonomous racing. ZipMPC consistently completes laps faster than selected baselines, achieving lap times close to the long-horizon MPC baseline. In challenging scenarios where the short-horizon MPC baseline fails to complete a lap, ZipMPC is able to do so. In particular, these performance gains are also observed on tracks unseen during training.
Beyond Predefined Actions: Integrating Behavior Trees and Dynamic Movement Primitives for Robot Learning from Demonstration
May 13, 2025



Interpretable policy representations like Behavior Trees (BTs) and Dynamic Motion Primitives (DMPs) enable robot skill transfer from human demonstrations, but each faces limitations: BTs require expert-crafted low-level actions, while DMPs lack high-level task logic. We address these limitations by integrating DMP controllers into a BT framework, jointly learning the BT structure and DMP actions from single demonstrations, thereby removing the need for predefined actions. Additionally, by combining BT decision logic with DMP motion generation, our method enhances policy interpretability, modularity, and adaptability for autonomous systems. Our approach readily affords both learning to replicate low-level motions and combining partial demonstrations into a coherent and easy-to-modify overall policy.
On the Fly Adaptation of Behavior Tree-Based Policies through Reinforcement Learning
Mar 08, 2025With the rising demand for flexible manufacturing, robots are increasingly expected to operate in dynamic environments where local -- such as slight offsets or size differences in workpieces -- are common. We propose to address the problem of adapting robot behaviors to these task variations with a sample-efficient hierarchical reinforcement learning approach adapting Behavior Tree (BT)-based policies. We maintain the core BT properties as an interpretable, modular framework for structuring reactive behaviors, but extend their use beyond static tasks by inherently accommodating local task variations. To show the efficiency and effectiveness of our approach, we conduct experiments both in simulation and on a Franka Emika Panda 7-DoF, with the manipulator adapting to different obstacle avoidance and pivoting tasks.
On the Effects of Irrelevant Variables in Treatment Effect Estimation with Deep Disentanglement
Jul 29, 2024Estimating treatment effects from observational data is paramount in healthcare, education, and economics, but current deep disentanglement-based methods to address selection bias are insufficiently handling irrelevant variables. We demonstrate in experiments that this leads to prediction errors. We disentangle pre-treatment variables with a deep embedding method and explicitly identify and represent irrelevant variables, additionally to instrumental, confounding and adjustment latent factors. To this end, we introduce a reconstruction objective and create an embedding space for irrelevant variables using an attached autoencoder. Instead of relying on serendipitous suppression of irrelevant variables as in previous deep disentanglement approaches, we explicitly force irrelevant variables into this embedding space and employ orthogonalization to prevent irrelevant information from leaking into the latent space representations of the other factors. Our experiments with synthetic and real-world benchmark datasets show that we can better identify irrelevant variables and more precisely predict treatment effects than previous methods, while prediction quality degrades less when additional irrelevant variables are introduced.
Learning Solutions of Stochastic Optimization Problems with Bayesian Neural Networks
Jun 05, 2024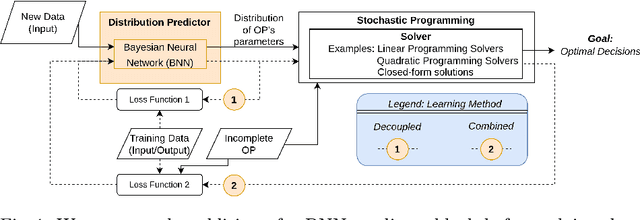
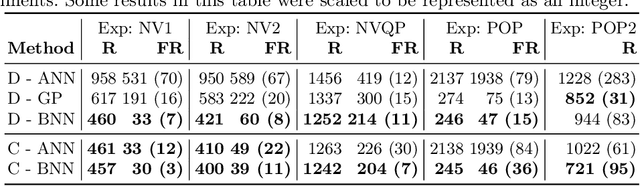

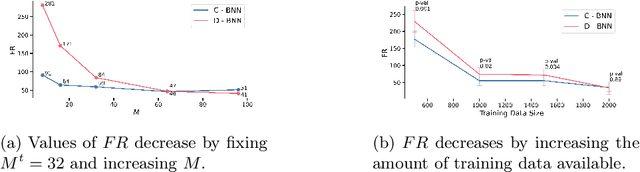
Mathematical solvers use parametrized Optimization Problems (OPs) as inputs to yield optimal decisions. In many real-world settings, some of these parameters are unknown or uncertain. Recent research focuses on predicting the value of these unknown parameters using available contextual features, aiming to decrease decision regret by adopting end-to-end learning approaches. However, these approaches disregard prediction uncertainty and therefore make the mathematical solver susceptible to provide erroneous decisions in case of low-confidence predictions. We propose a novel framework that models prediction uncertainty with Bayesian Neural Networks (BNNs) and propagates this uncertainty into the mathematical solver with a Stochastic Programming technique. The differentiable nature of BNNs and differentiable mathematical solvers allow for two different learning approaches: In the Decoupled learning approach, we update the BNN weights to increase the quality of the predictions' distribution of the OP parameters, while in the Combined learning approach, we update the weights aiming to directly minimize the expected OP's cost function in a stochastic end-to-end fashion. We do an extensive evaluation using synthetic data with various noise properties and a real dataset, showing that decisions regret are generally lower (better) with both proposed methods.
DataSP: A Differential All-to-All Shortest Path Algorithm for Learning Costs and Predicting Paths with Context
May 08, 2024
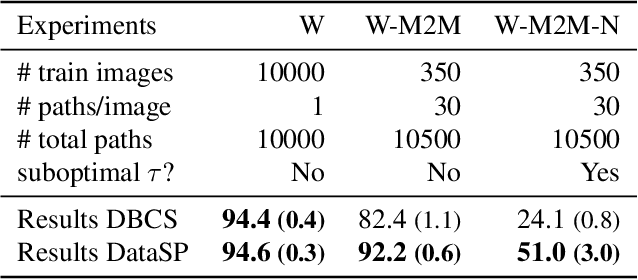

Learning latent costs of transitions on graphs from trajectories demonstrations under various contextual features is challenging but useful for path planning. Yet, existing methods either oversimplify cost assumptions or scale poorly with the number of observed trajectories. This paper introduces DataSP, a differentiable all-to-all shortest path algorithm to facilitate learning latent costs from trajectories. It allows to learn from a large number of trajectories in each learning step without additional computation. Complex latent cost functions from contextual features can be represented in the algorithm through a neural network approximation. We further propose a method to sample paths from DataSP in order to reconstruct/mimic observed paths' distributions. We prove that the inferred distribution follows the maximum entropy principle. We show that DataSP outperforms state-of-the-art differentiable combinatorial solver and classical machine learning approaches in predicting paths on graphs.
LaCE-LHMP: Airflow Modelling-Inspired Long-Term Human Motion Prediction By Enhancing Laminar Characteristics in Human Flow
Mar 20, 2024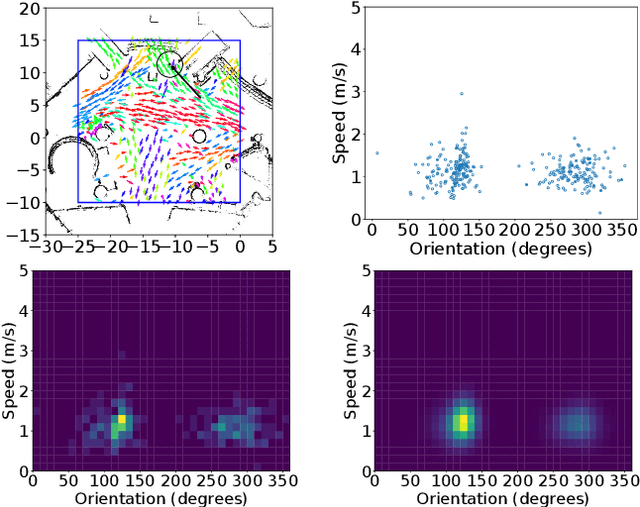
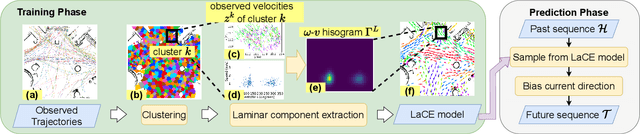
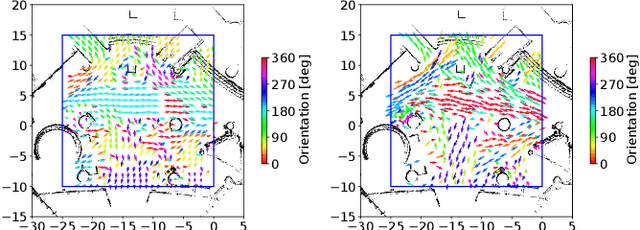
Long-term human motion prediction (LHMP) is essential for safely operating autonomous robots and vehicles in populated environments. It is fundamental for various applications, including motion planning, tracking, human-robot interaction and safety monitoring. However, accurate prediction of human trajectories is challenging due to complex factors, including, for example, social norms and environmental conditions. The influence of such factors can be captured through Maps of Dynamics (MoDs), which encode spatial motion patterns learned from (possibly scattered and partial) past observations of motion in the environment and which can be used for data-efficient, interpretable motion prediction (MoD-LHMP). To address the limitations of prior work, especially regarding accuracy and sensitivity to anomalies in long-term prediction, we propose the Laminar Component Enhanced LHMP approach (LaCE-LHMP). Our approach is inspired by data-driven airflow modelling, which estimates laminar and turbulent flow components and uses predominantly the laminar components to make flow predictions. Based on the hypothesis that human trajectory patterns also manifest laminar flow (that represents predictable motion) and turbulent flow components (that reflect more unpredictable and arbitrary motion), LaCE-LHMP extracts the laminar patterns in human dynamics and uses them for human motion prediction. We demonstrate the superior prediction performance of LaCE-LHMP through benchmark comparisons with state-of-the-art LHMP methods, offering an unconventional perspective and a more intuitive understanding of human movement patterns.