 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgress Constraints for Reinforcement Learning in Behavior Trees
Feb 06, 2026Behavior Trees (BTs) provide a structured and reactive framework for decision-making, commonly used to switch between sub-controllers based on environmental conditions. Reinforcement Learning (RL), on the other hand, can learn near-optimal controllers but sometimes struggles with sparse rewards, safe exploration, and long-horizon credit assignment. Combining BTs with RL has the potential for mutual benefit: a BT design encodes structured domain knowledge that can simplify RL training, while RL enables automatic learning of the controllers within BTs. However, naive integration of BTs and RL can lead to some controllers counteracting other controllers, possibly undoing previously achieved subgoals, thereby degrading the overall performance. To address this, we propose progress constraints, a novel mechanism where feasibility estimators constrain the allowed action set based on theoretical BT convergence results. Empirical evaluations in a 2D proof-of-concept and a high-fidelity warehouse environment demonstrate improved performance, sample efficiency, and constraint satisfaction, compared to prior methods of BT-RL integration.
APC-RL: Exceeding Data-Driven Behavior Priors with Adaptive Policy Composition
Jan 27, 2026Incorporating demonstration data into reinforcement learning (RL) can greatly accelerate learning, but existing approaches often assume demonstrations are optimal and fully aligned with the target task. In practice, demonstrations are frequently sparse, suboptimal, or misaligned, which can degrade performance when these demonstrations are integrated into RL. We propose Adaptive Policy Composition (APC), a hierarchical model that adaptively composes multiple data-driven Normalizing Flow (NF) priors. Instead of enforcing strict adherence to the priors, APC estimates each prior's applicability to the target task while leveraging them for exploration. Moreover, APC either refines useful priors, or sidesteps misaligned ones when necessary to optimize downstream reward. Across diverse benchmarks, APC accelerates learning when demonstrations are aligned, remains robust under severe misalignment, and leverages suboptimal demonstrations to bootstrap exploration while avoiding performance degradation caused by overly strict adherence to suboptimal demonstrations.
Enhancing Pre-Trained Decision Transformers with Prompt-Tuning Bandits
Feb 10, 2025Harnessing large offline datasets is vital for training foundation models that can generalize across diverse tasks. Offline Reinforcement Learning (RL) offers a powerful framework for these scenarios, enabling the derivation of optimal policies even from suboptimal data. The Prompting Decision Transformer (PDT) is an offline RL multi-task model that distinguishes tasks through stochastic trajectory prompts, which are task-specific tokens maintained in context during rollouts. However, PDT samples these tokens uniformly at random from per-task demonstration datasets, failing to account for differences in token informativeness and potentially leading to performance degradation. To address this limitation, we introduce a scalable bandit-based prompt-tuning method that dynamically learns to construct high-performance trajectory prompts. Our approach significantly enhances downstream task performance without modifying the pre-trained Transformer backbone. Empirical results on benchmark tasks and a newly designed multi-task environment demonstrate the effectiveness of our method, creating a seamless bridge between general multi-task offline pre-training and task-specific online adaptation.
Towards bandit-based prompt-tuning for in-the-wild foundation agents
Feb 10, 2025Prompting has emerged as the dominant paradigm for adapting large, pre-trained transformer-based models to downstream tasks. The Prompting Decision Transformer (PDT) enables large-scale, multi-task offline reinforcement learning pre-training by leveraging stochastic trajectory prompts to identify the target task. However, these prompts are sampled uniformly from expert demonstrations, overlooking a critical limitation: Not all prompts are equally informative for differentiating between tasks. To address this, we propose an inference time bandit-based prompt-tuning framework that explores and optimizes trajectory prompt selection to enhance task performance. Our experiments indicate not only clear performance gains due to bandit-based prompt-tuning, but also better sample complexity, scalability, and prompt space exploration compared to prompt-tuning baselines.
Diversity for Contingency: Learning Diverse Behaviors for Efficient Adaptation and Transfer
Oct 11, 2023



Discovering all useful solutions for a given task is crucial for transferable RL agents, to account for changes in the task or transition dynamics. This is not considered by classical RL algorithms that are only concerned with finding the optimal policy, given the current task and dynamics. We propose a simple method for discovering all possible solutions of a given task, to obtain an agent that performs well in the transfer setting and adapts quickly to changes in the task or transition dynamics. Our method iteratively learns a set of policies, while each subsequent policy is constrained to yield a solution that is unlikely under all previous policies. Unlike prior methods, our approach does not require learning additional models for novelty detection and avoids balancing task and novelty reward signals, by directly incorporating the constraint into the action selection and optimization steps.
Prioritized Soft Q-Decomposition for Lexicographic Reinforcement Learning
Oct 03, 2023Reinforcement learning (RL) for complex tasks remains a challenge, primarily due to the difficulties of engineering scalar reward functions and the inherent inefficiency of training models from scratch. Instead, it would be better to specify complex tasks in terms of elementary subtasks and to reuse subtask solutions whenever possible. In this work, we address continuous space lexicographic multi-objective RL problems, consisting of prioritized subtasks, which are notoriously difficult to solve. We show that these can be scalarized with a subtask transformation and then solved incrementally using value decomposition. Exploiting this insight, we propose prioritized soft Q-decomposition (PSQD), a novel algorithm for learning and adapting subtask solutions under lexicographic priorities in continuous state-action spaces. PSQD offers the ability to reuse previously learned subtask solutions in a zero-shot composition, followed by an adaptation step. Its ability to use retained subtask training data for offline learning eliminates the need for new environment interaction during adaptation. We demonstrate the efficacy of our approach by presenting successful learning, reuse, and adaptation results for both low- and high-dimensional simulated robot control tasks, as well as offline learning results. In contrast to baseline approaches, PSQD does not trade off between conflicting subtasks or priority constraints and satisfies subtask priorities during learning. PSQD provides an intuitive framework for tackling complex RL problems, offering insights into the inner workings of the subtask composition.
Towards Task-Prioritized Policy Composition
Sep 20, 2022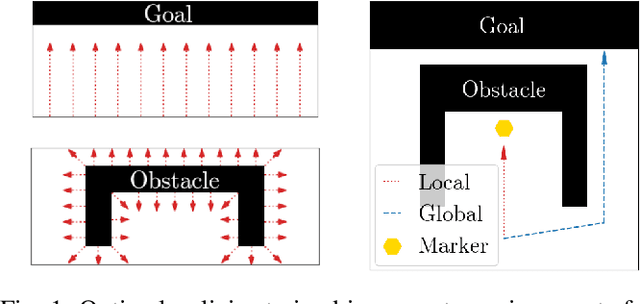
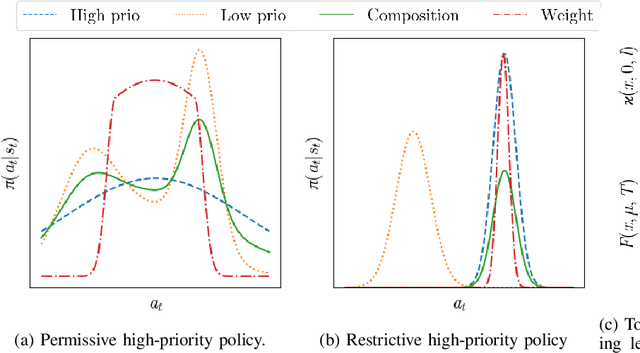
Combining learned policies in a prioritized, ordered manner is desirable because it allows for modular design and facilitates data reuse through knowledge transfer. In control theory, prioritized composition is realized by null-space control, where low-priority control actions are projected into the null-space of high-priority control actions. Such a method is currently unavailable for Reinforcement Learning. We propose a novel, task-prioritized composition framework for Reinforcement Learning, which involves a novel concept: The indifferent-space of Reinforcement Learning policies. Our framework has the potential to facilitate knowledge transfer and modular design while greatly increasing data efficiency and data reuse for Reinforcement Learning agents. Further, our approach can ensure high-priority constraint satisfaction, which makes it promising for learning in safety-critical domains like robotics. Unlike null-space control, our approach allows learning globally optimal policies for the compound task by online learning in the indifference-space of higher-level policies after initial compound policy construction.