 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle-View Shape Completion for Robotic Grasping in Clutter
Dec 18, 2025



In vision-based robot manipulation, a single camera view can only capture one side of objects of interest, with additional occlusions in cluttered scenes further restricting visibility. As a result, the observed geometry is incomplete, and grasp estimation algorithms perform suboptimally. To address this limitation, we leverage diffusion models to perform category-level 3D shape completion from partial depth observations obtained from a single view, reconstructing complete object geometries to provide richer context for grasp planning. Our method focuses on common household items with diverse geometries, generating full 3D shapes that serve as input to downstream grasp inference networks. Unlike prior work, which primarily considers isolated objects or minimal clutter, we evaluate shape completion and grasping in realistic clutter scenarios with household objects. In preliminary evaluations on a cluttered scene, our approach consistently results in better grasp success rates than a naive baseline without shape completion by 23% and over a recent state of the art shape completion approach by 19%. Our code is available at https://amm.aass.oru.se/shape-completion-grasping/.
Can Context Bridge the Reality Gap? Sim-to-Real Transfer of Context-Aware Policies
Nov 06, 2025Sim-to-real transfer remains a major challenge in reinforcement learning (RL) for robotics, as policies trained in simulation often fail to generalize to the real world due to discrepancies in environment dynamics. Domain Randomization (DR) mitigates this issue by exposing the policy to a wide range of randomized dynamics during training, yet leading to a reduction in performance. While standard approaches typically train policies agnostic to these variations, we investigate whether sim-to-real transfer can be improved by conditioning the policy on an estimate of the dynamics parameters -- referred to as context. To this end, we integrate a context estimation module into a DR-based RL framework and systematically compare SOTA supervision strategies. We evaluate the resulting context-aware policies in both a canonical control benchmark and a real-world pushing task using a Franka Emika Panda robot. Results show that context-aware policies outperform the context-agnostic baseline across all settings, although the best supervision strategy depends on the task.
Exploiting Radiance Fields for Grasp Generation on Novel Synthetic Views
May 16, 2025Vision based robot manipulation uses cameras to capture one or more images of a scene containing the objects to be manipulated. Taking multiple images can help if any object is occluded from one viewpoint but more visible from another viewpoint. However, the camera has to be moved to a sequence of suitable positions for capturing multiple images, which requires time and may not always be possible, due to reachability constraints. So while additional images can produce more accurate grasp poses due to the extra information available, the time-cost goes up with the number of additional views sampled. Scene representations like Gaussian Splatting are capable of rendering accurate photorealistic virtual images from user-specified novel viewpoints. In this work, we show initial results which indicate that novel view synthesis can provide additional context in generating grasp poses. Our experiments on the Graspnet-1billion dataset show that novel views contributed force-closure grasps in addition to the force-closure grasps obtained from sparsely sampled real views while also improving grasp coverage. In the future we hope this work can be extended to improve grasp extraction from radiance fields constructed with a single input image, using for example diffusion models or generalizable radiance fields.
Beyond Predefined Actions: Integrating Behavior Trees and Dynamic Movement Primitives for Robot Learning from Demonstration
May 13, 2025



Interpretable policy representations like Behavior Trees (BTs) and Dynamic Motion Primitives (DMPs) enable robot skill transfer from human demonstrations, but each faces limitations: BTs require expert-crafted low-level actions, while DMPs lack high-level task logic. We address these limitations by integrating DMP controllers into a BT framework, jointly learning the BT structure and DMP actions from single demonstrations, thereby removing the need for predefined actions. Additionally, by combining BT decision logic with DMP motion generation, our method enhances policy interpretability, modularity, and adaptability for autonomous systems. Our approach readily affords both learning to replicate low-level motions and combining partial demonstrations into a coherent and easy-to-modify overall policy.
On the Fly Adaptation of Behavior Tree-Based Policies through Reinforcement Learning
Mar 08, 2025With the rising demand for flexible manufacturing, robots are increasingly expected to operate in dynamic environments where local -- such as slight offsets or size differences in workpieces -- are common. We propose to address the problem of adapting robot behaviors to these task variations with a sample-efficient hierarchical reinforcement learning approach adapting Behavior Tree (BT)-based policies. We maintain the core BT properties as an interpretable, modular framework for structuring reactive behaviors, but extend their use beyond static tasks by inherently accommodating local task variations. To show the efficiency and effectiveness of our approach, we conduct experiments both in simulation and on a Franka Emika Panda 7-DoF, with the manipulator adapting to different obstacle avoidance and pivoting tasks.
Learning Extrinsic Dexterity with Parameterized Manipulation Primitives
Nov 02, 2023
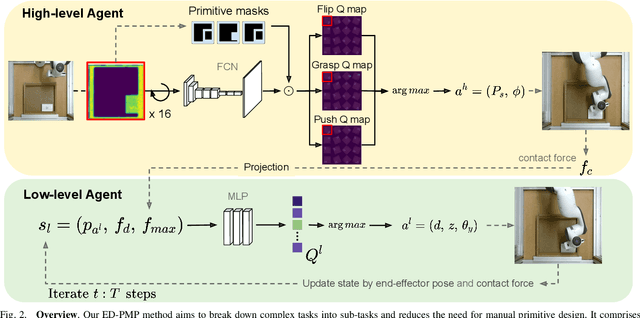
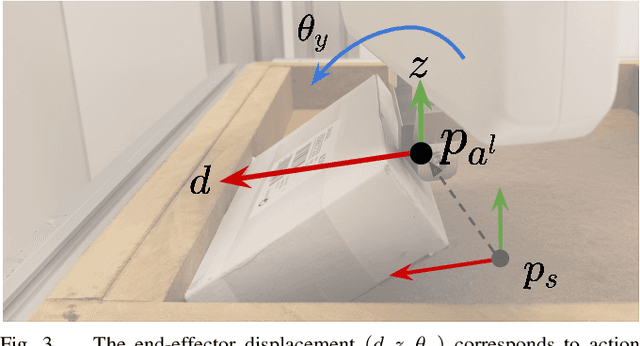
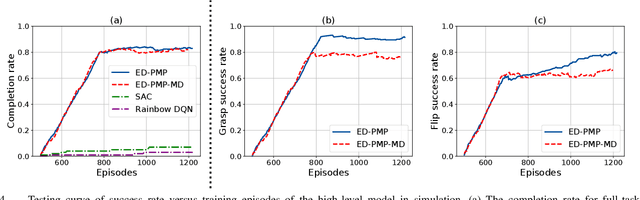
Many practically relevant robot grasping problems feature a target object for which all grasps are occluded, e.g., by the environment. Single-shot grasp planning invariably fails in such scenarios. Instead, it is necessary to first manipulate the object into a configuration that affords a grasp. We solve this problem by learning a sequence of actions that utilize the environment to change the object's pose. Concretely, we employ hierarchical reinforcement learning to combine a sequence of learned parameterized manipulation primitives. By learning the low-level manipulation policies, our approach can control the object's state through exploiting interactions between the object, the gripper, and the environment. Designing such a complex behavior analytically would be infeasible under uncontrolled conditions, as an analytic approach requires accurate physical modeling of the interaction and contact dynamics. In contrast, we learn a hierarchical policy model that operates directly on depth perception data, without the need for object detection, pose estimation, or manual design of controllers. We evaluate our approach on picking box-shaped objects of various weight, shape, and friction properties from a constrained table-top workspace. Our method transfers to a real robot and is able to successfully complete the object picking task in 98\% of experimental trials.
Heterogeneous Full-body Control of a Mobile Manipulator with Behavior Trees
Oct 16, 2022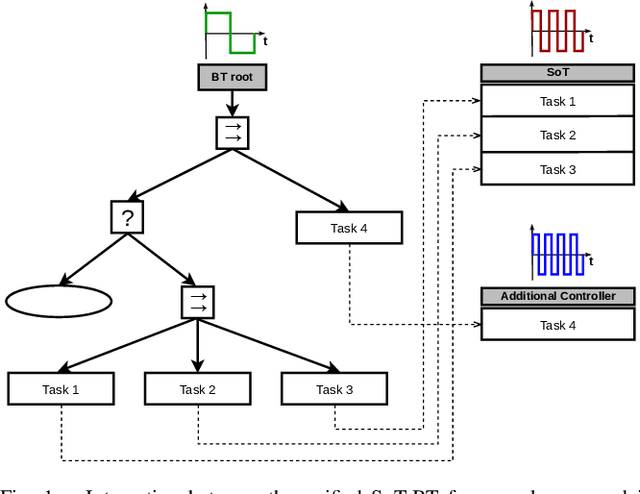
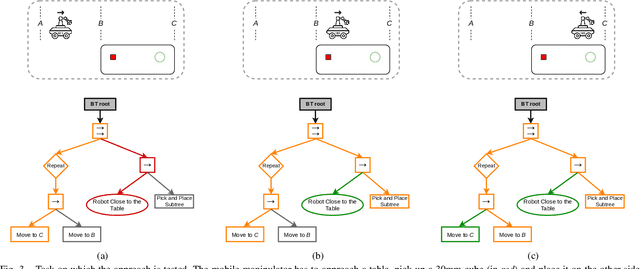
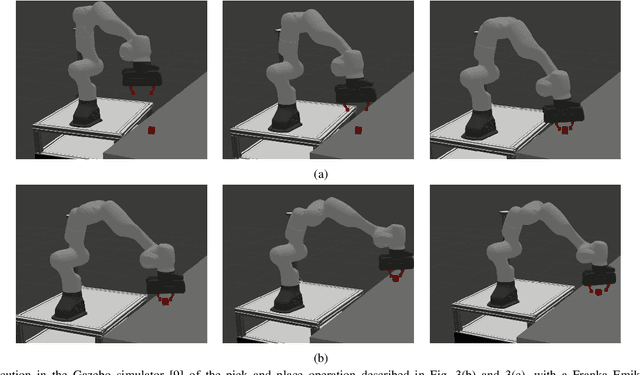
Integrating the heterogeneous controllers of a complex mechanical system, such as a mobile manipulator, within the same structure and in a modular way is still challenging. In this work we extend our framework based on Behavior Trees for the control of a redundant mechanical system to the problem of commanding more complex systems that involve multiple low-level controllers. This allows the integrated systems to achieve non-trivial goals that require coordination among the sub-systems.
Towards Task-Prioritized Policy Composition
Sep 20, 2022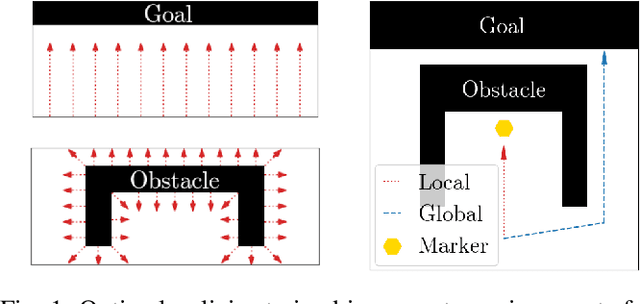
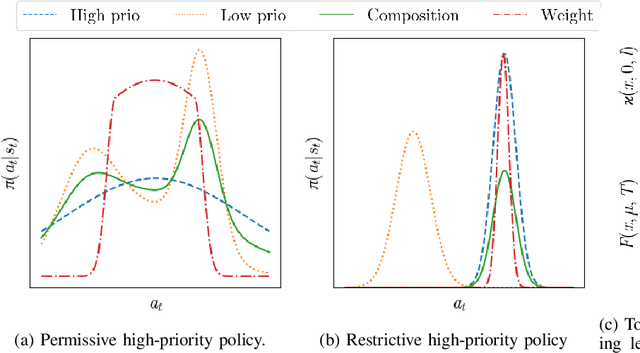
Combining learned policies in a prioritized, ordered manner is desirable because it allows for modular design and facilitates data reuse through knowledge transfer. In control theory, prioritized composition is realized by null-space control, where low-priority control actions are projected into the null-space of high-priority control actions. Such a method is currently unavailable for Reinforcement Learning. We propose a novel, task-prioritized composition framework for Reinforcement Learning, which involves a novel concept: The indifferent-space of Reinforcement Learning policies. Our framework has the potential to facilitate knowledge transfer and modular design while greatly increasing data efficiency and data reuse for Reinforcement Learning agents. Further, our approach can ensure high-priority constraint satisfaction, which makes it promising for learning in safety-critical domains like robotics. Unlike null-space control, our approach allows learning globally optimal policies for the compound task by online learning in the indifference-space of higher-level policies after initial compound policy construction.
Transferring Knowledge for Reinforcement Learning in Contact-Rich Manipulation
Sep 19, 2022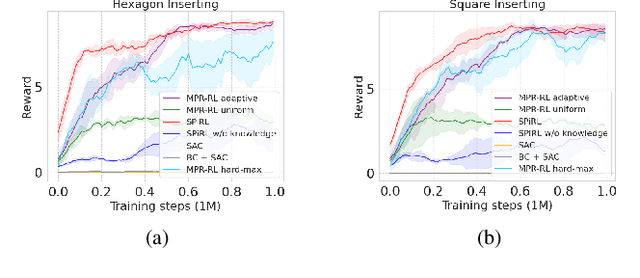
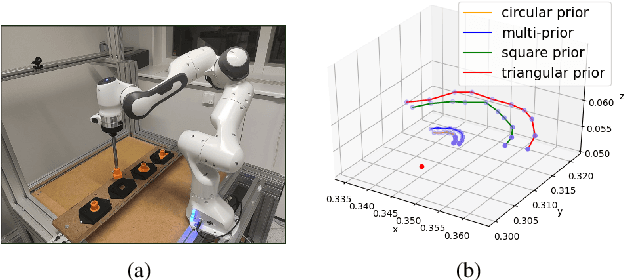
In manufacturing, assembly tasks have been a challenge for learning algorithms due to variant dynamics of different environments. Reinforcement learning (RL) is a promising framework to automatically learn these tasks, yet it is still not easy to apply a learned policy or skill, that is the ability of solving a task, to a similar environment even if the deployment conditions are only slightly different. In this paper, we address the challenge of transferring knowledge within a family of similar tasks by leveraging multiple skill priors. We propose to learn prior distribution over the specific skill required to accomplish each task and compose the family of skill priors to guide learning the policy for a new task by comparing the similarity between the target task and the prior ones. Our method learns a latent action space representing the skill embedding from demonstrated trajectories for each prior task. We have evaluated our method on a set of peg-in-hole insertion tasks and demonstrate better generalization to new tasks that have never been encountered during training.
A Stack-of-Tasks Approach Combined with Behavior Trees: a New Framework for Robot Control
Sep 18, 2022


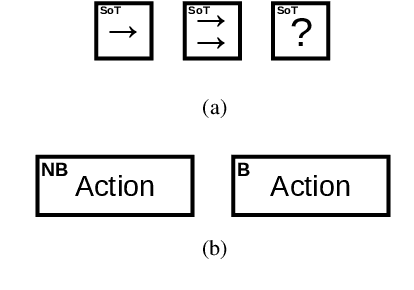
Stack-of-Tasks (SoT) control allows a robot to simultaneously fulfill a number of prioritized goals formulated in terms of (in)equality constraints in error space. Since this approach solves a sequence of Quadratic Programs (QP) at each time-step, without taking into account any temporal state evolution, it is suitable for dealing with local disturbances. However, its limitation lies in the handling of situations that require non-quadratic objectives to achieve a specific goal, as well as situations where countering the control disturbance would require a locally suboptimal action. Recent works address this shortcoming by exploiting Finite State Machines (FSMs) to compose the tasks in such a way that the robot does not get stuck in local minima. Nevertheless, the intrinsic trade-off between reactivity and modularity that characterizes FSMs makes them impractical for defining reactive behaviors in dynamic environments. In this letter, we combine the SoT control strategy with Behavior Trees (BTs), a task switching structure that addresses some of the limitations of the FSMs in terms of reactivity, modularity and re-usability. Experimental results on a Franka Emika Panda 7-DOF manipulator show the robustness of our framework, that allows the robot to benefit from the reactivity of both SoT and BTs.