 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViSA-Flow: Accelerating Robot Skill Learning via Large-Scale Video Semantic Action Flow
May 02, 2025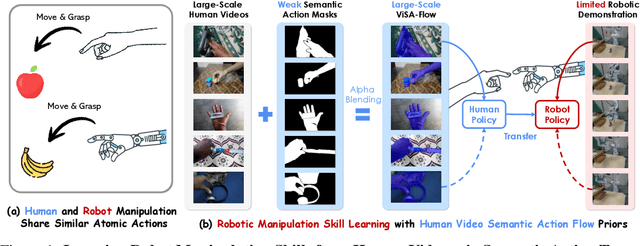
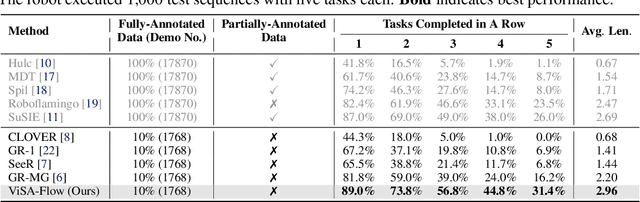
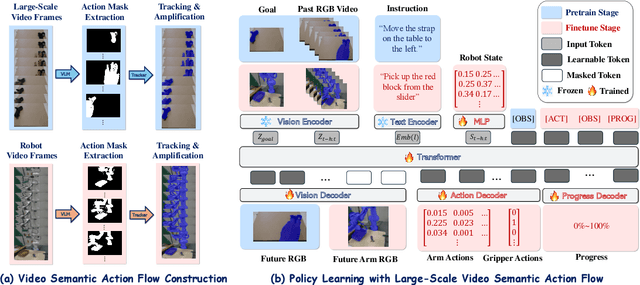
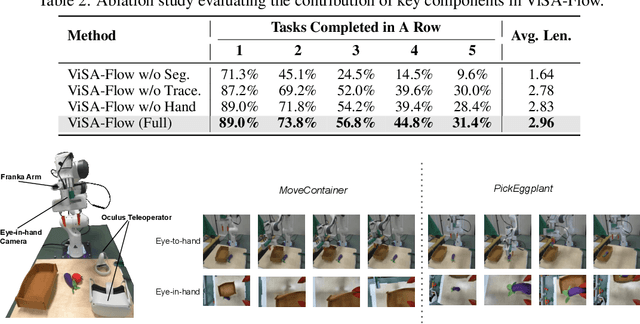
One of the central challenges preventing robots from acquiring complex manipulation skills is the prohibitive cost of collecting large-scale robot demonstrations. In contrast, humans are able to learn efficiently by watching others interact with their environment. To bridge this gap, we introduce semantic action flow as a core intermediate representation capturing the essential spatio-temporal manipulator-object interactions, invariant to superficial visual differences. We present ViSA-Flow, a framework that learns this representation self-supervised from unlabeled large-scale video data. First, a generative model is pre-trained on semantic action flows automatically extracted from large-scale human-object interaction video data, learning a robust prior over manipulation structure. Second, this prior is efficiently adapted to a target robot by fine-tuning on a small set of robot demonstrations processed through the same semantic abstraction pipeline. We demonstrate through extensive experiments on the CALVIN benchmark and real-world tasks that ViSA-Flow achieves state-of-the-art performance, particularly in low-data regimes, outperforming prior methods by effectively transferring knowledge from human video observation to robotic execution. Videos are available at https://visaflow-web.github.io/ViSAFLOW.
S$^2$-Diffusion: Generalizing from Instance-level to Category-level Skills in Robot Manipulation
Feb 13, 2025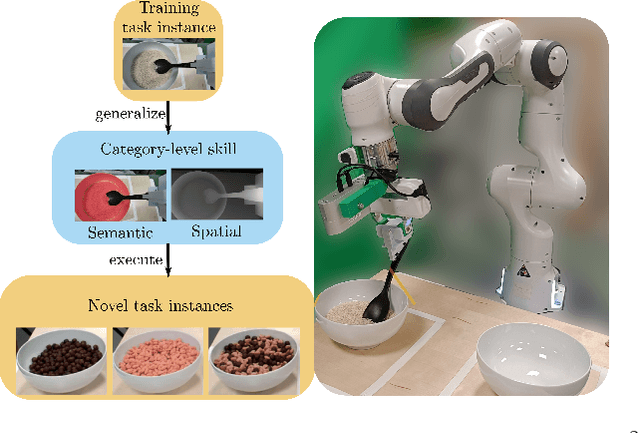
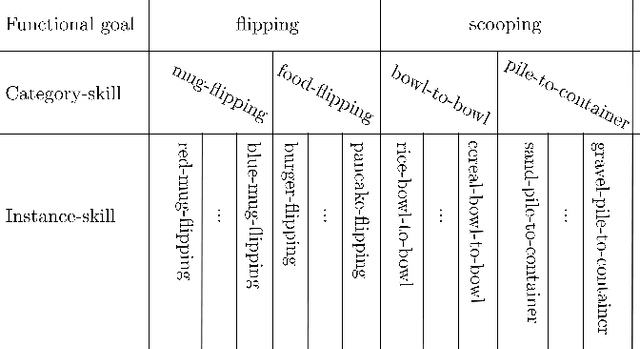
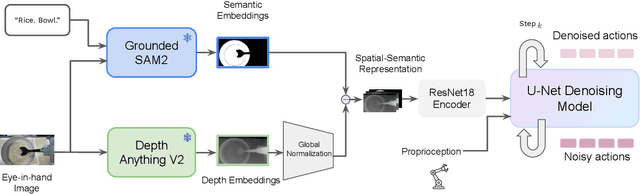

Recent advances in skill learning has propelled robot manipulation to new heights by enabling it to learn complex manipulation tasks from a practical number of demonstrations. However, these skills are often limited to the particular action, object, and environment \textit{instances} that are shown in the training data, and have trouble transferring to other instances of the same category. In this work we present an open-vocabulary Spatial-Semantic Diffusion policy (S$^2$-Diffusion) which enables generalization from instance-level training data to category-level, enabling skills to be transferable between instances of the same category. We show that functional aspects of skills can be captured via a promptable semantic module combined with a spatial representation. We further propose leveraging depth estimation networks to allow the use of only a single RGB camera. Our approach is evaluated and compared on a diverse number of robot manipulation tasks, both in simulation and in the real world. Our results show that S$^2$-Diffusion is invariant to changes in category-irrelevant factors as well as enables satisfying performance on other instances within the same category, even if it was not trained on that specific instance. Full videos of all real-world experiments are available in the supplementary material.
One Map to Find Them All: Real-time Open-Vocabulary Mapping for Zero-shot Multi-Object Navigation
Sep 18, 2024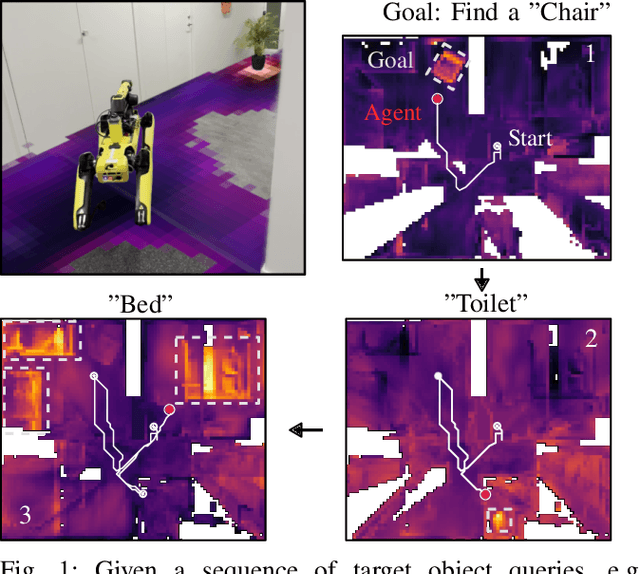
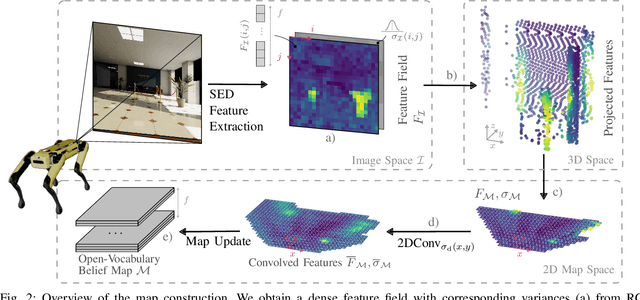
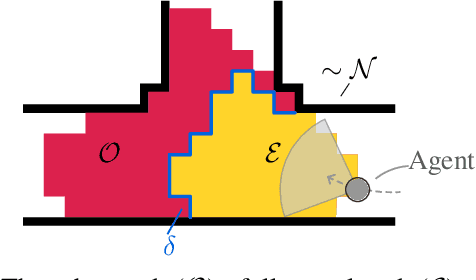
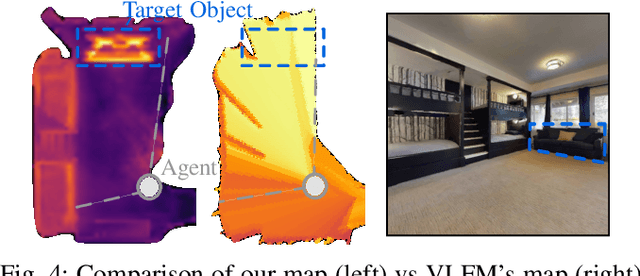
The capability to efficiently search for objects in complex environments is fundamental for many real-world robot applications. Recent advances in open-vocabulary vision models have resulted in semantically-informed object navigation methods that allow a robot to search for an arbitrary object without prior training. However, these zero-shot methods have so far treated the environment as unknown for each consecutive query. In this paper we introduce a new benchmark for zero-shot multi-object navigation, allowing the robot to leverage information gathered from previous searches to more efficiently find new objects. To address this problem we build a reusable open-vocabulary feature map tailored for real-time object search. We further propose a probabilistic-semantic map update that mitigates common sources of errors in semantic feature extraction and leverage this semantic uncertainty for informed multi-object exploration. We evaluate our method on a set of object navigation tasks in both simulation as well as with a real robot, running in real-time on a Jetson Orin AGX. We demonstrate that it outperforms existing state-of-the-art approaches both on single and multi-object navigation tasks. Additional videos, code and the multi-object navigation benchmark will be available on https://finnbsch.github.io/OneMap.
PRIME: Scaffolding Manipulation Tasks with Behavior Primitives for Data-Efficient Imitation Learning
Mar 10, 2024Imitation learning has shown great potential for enabling robots to acquire complex manipulation behaviors. However, these algorithms suffer from high sample complexity in long-horizon tasks, where compounding errors accumulate over the task horizons. We present PRIME (PRimitive-based IMitation with data Efficiency), a behavior primitive-based framework designed for improving the data efficiency of imitation learning. PRIME scaffolds robot tasks by decomposing task demonstrations into primitive sequences, followed by learning a high-level control policy to sequence primitives through imitation learning. Our experiments demonstrate that PRIME achieves a significant performance improvement in multi-stage manipulation tasks, with 10-34% higher success rates in simulation over state-of-the-art baselines and 20-48% on physical hardware.
Transferring Knowledge for Reinforcement Learning in Contact-Rich Manipulation
Sep 19, 2022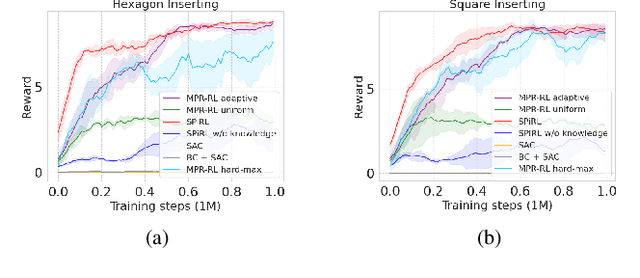
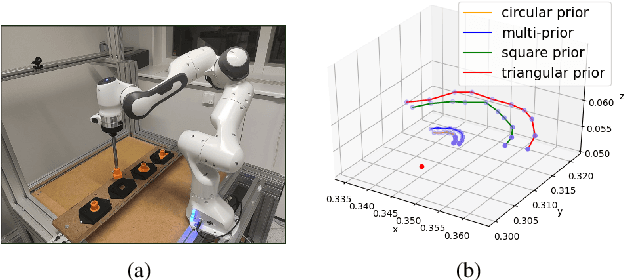
In manufacturing, assembly tasks have been a challenge for learning algorithms due to variant dynamics of different environments. Reinforcement learning (RL) is a promising framework to automatically learn these tasks, yet it is still not easy to apply a learned policy or skill, that is the ability of solving a task, to a similar environment even if the deployment conditions are only slightly different. In this paper, we address the challenge of transferring knowledge within a family of similar tasks by leveraging multiple skill priors. We propose to learn prior distribution over the specific skill required to accomplish each task and compose the family of skill priors to guide learning the policy for a new task by comparing the similarity between the target task and the prior ones. Our method learns a latent action space representing the skill embedding from demonstrated trajectories for each prior task. We have evaluated our method on a set of peg-in-hole insertion tasks and demonstrate better generalization to new tasks that have never been encountered during training.