 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS$^2$-Diffusion: Generalizing from Instance-level to Category-level Skills in Robot Manipulation
Paper and Code
Feb 13, 2025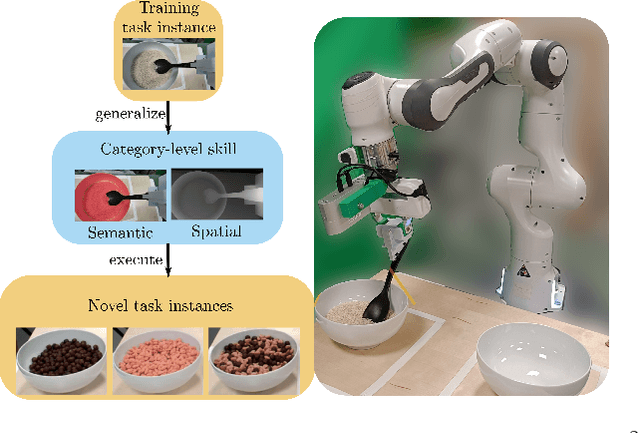
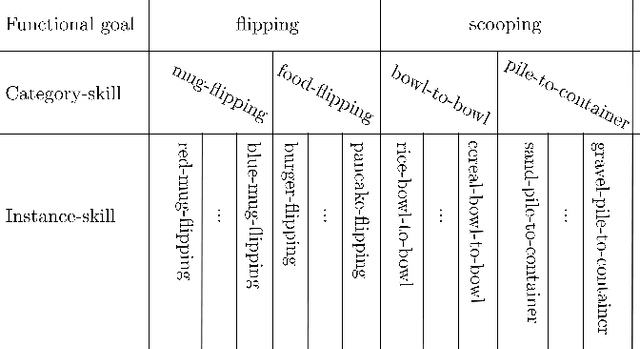
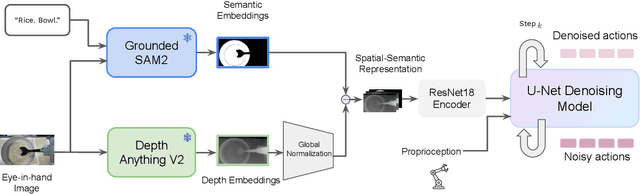

Recent advances in skill learning has propelled robot manipulation to new heights by enabling it to learn complex manipulation tasks from a practical number of demonstrations. However, these skills are often limited to the particular action, object, and environment \textit{instances} that are shown in the training data, and have trouble transferring to other instances of the same category. In this work we present an open-vocabulary Spatial-Semantic Diffusion policy (S$^2$-Diffusion) which enables generalization from instance-level training data to category-level, enabling skills to be transferable between instances of the same category. We show that functional aspects of skills can be captured via a promptable semantic module combined with a spatial representation. We further propose leveraging depth estimation networks to allow the use of only a single RGB camera. Our approach is evaluated and compared on a diverse number of robot manipulation tasks, both in simulation and in the real world. Our results show that S$^2$-Diffusion is invariant to changes in category-irrelevant factors as well as enables satisfying performance on other instances within the same category, even if it was not trained on that specific instance. Full videos of all real-world experiments are available in the supplementary material.