 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreference Aligned Visuomotor Diffusion Policies for Deformable Object Manipulation
Feb 10, 2026Humans naturally develop preferences for how manipulation tasks should be performed, which are often subtle, personal, and difficult to articulate. Although it is important for robots to account for these preferences to increase personalization and user satisfaction, they remain largely underexplored in robotic manipulation, particularly in the context of deformable objects like garments and fabrics. In this work, we study how to adapt pretrained visuomotor diffusion policies to reflect preferred behaviors using limited demonstrations. We introduce RKO, a novel preference-alignment method that combines the benefits of two recent frameworks: RPO and KTO. We evaluate RKO against common preference learning frameworks, including these two, as well as a baseline vanilla diffusion policy, on real-world cloth-folding tasks spanning multiple garments and preference settings. We show that preference-aligned policies (particularly RKO) achieve superior performance and sample efficiency compared to standard diffusion policy fine-tuning. These results highlight the importance and feasibility of structured preference learning for scaling personalized robot behavior in complex deformable object manipulation tasks.
Learning Dexterous In-Hand Manipulation with Multifingered Hands via Visuomotor Diffusion
Mar 04, 2025We present a framework for learning dexterous in-hand manipulation with multifingered hands using visuomotor diffusion policies. Our system enables complex in-hand manipulation tasks, such as unscrewing a bottle lid with one hand, by leveraging a fast and responsive teleoperation setup for the four-fingered Allegro Hand. We collect high-quality expert demonstrations using an augmented reality (AR) interface that tracks hand movements and applies inverse kinematics and motion retargeting for precise control. The AR headset provides real-time visualization, while gesture controls streamline teleoperation. To enhance policy learning, we introduce a novel demonstration outlier removal approach based on HDBSCAN clustering and the Global-Local Outlier Score from Hierarchies (GLOSH) algorithm, effectively filtering out low-quality demonstrations that could degrade performance. We evaluate our approach extensively in real-world settings and provide all experimental videos on the project website: https://dex-manip.github.io/
S$^2$-Diffusion: Generalizing from Instance-level to Category-level Skills in Robot Manipulation
Feb 13, 2025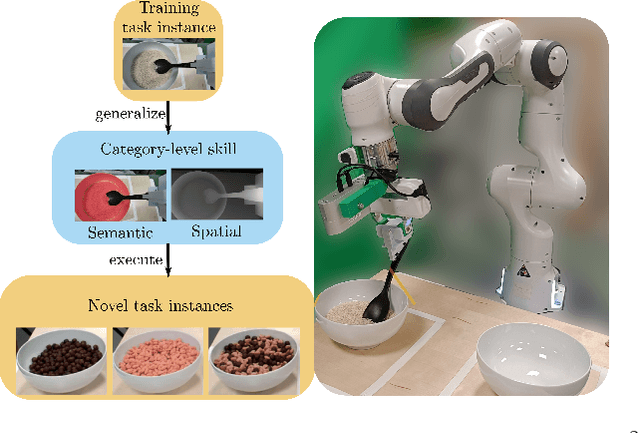
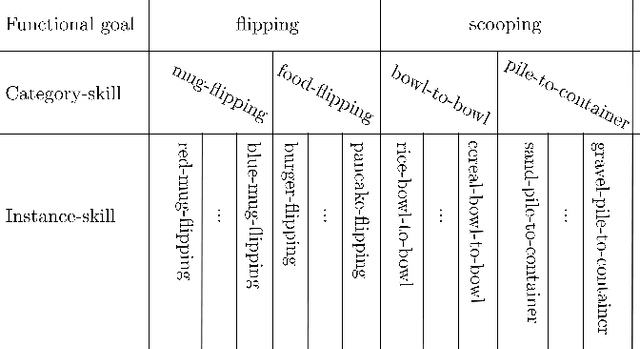
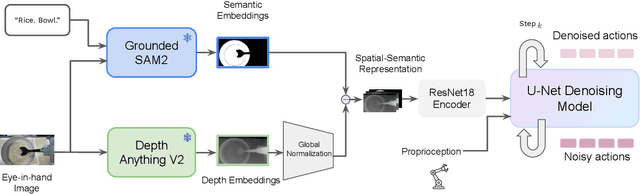

Recent advances in skill learning has propelled robot manipulation to new heights by enabling it to learn complex manipulation tasks from a practical number of demonstrations. However, these skills are often limited to the particular action, object, and environment \textit{instances} that are shown in the training data, and have trouble transferring to other instances of the same category. In this work we present an open-vocabulary Spatial-Semantic Diffusion policy (S$^2$-Diffusion) which enables generalization from instance-level training data to category-level, enabling skills to be transferable between instances of the same category. We show that functional aspects of skills can be captured via a promptable semantic module combined with a spatial representation. We further propose leveraging depth estimation networks to allow the use of only a single RGB camera. Our approach is evaluated and compared on a diverse number of robot manipulation tasks, both in simulation and in the real world. Our results show that S$^2$-Diffusion is invariant to changes in category-irrelevant factors as well as enables satisfying performance on other instances within the same category, even if it was not trained on that specific instance. Full videos of all real-world experiments are available in the supplementary material.
LLM-Driven Augmented Reality Puppeteer: Controller-Free Voice-Commanded Robot Teleoperation
Feb 13, 2025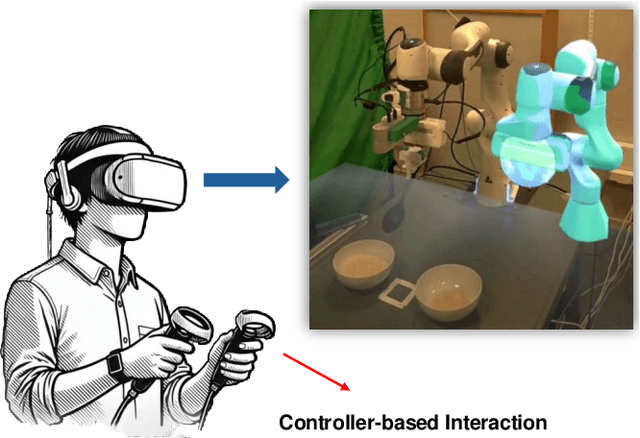
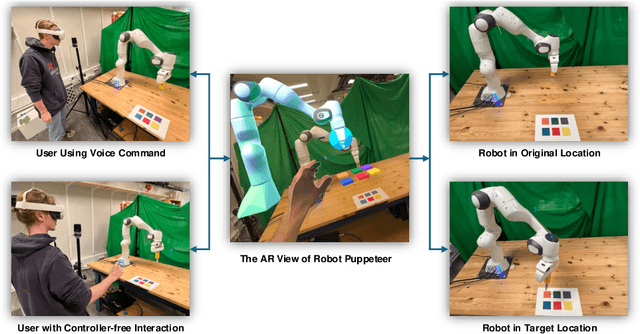
The integration of robotics and augmented reality (AR) presents transformative opportunities for advancing human-robot interaction (HRI) by improving usability, intuitiveness, and accessibility. This work introduces a controller-free, LLM-driven voice-commanded AR puppeteering system, enabling users to teleoperate a robot by manipulating its virtual counterpart in real time. By leveraging natural language processing (NLP) and AR technologies, our system -- prototyped using Meta Quest 3 -- eliminates the need for physical controllers, enhancing ease of use while minimizing potential safety risks associated with direct robot operation. A preliminary user demonstration successfully validated the system's functionality, demonstrating its potential for safer, more intuitive, and immersive robotic control.
Real-Time Operator Takeover for Visuomotor Diffusion Policy Training
Feb 04, 2025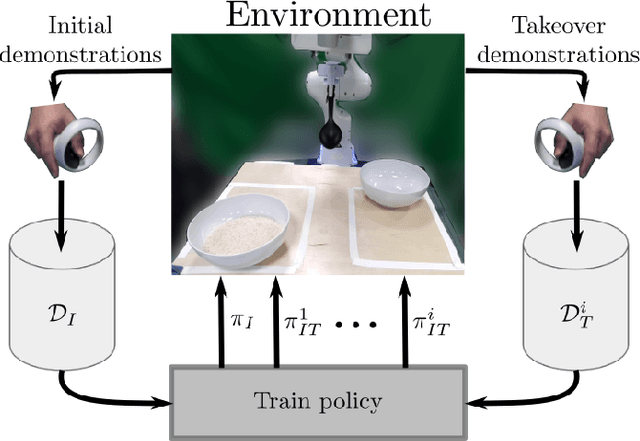

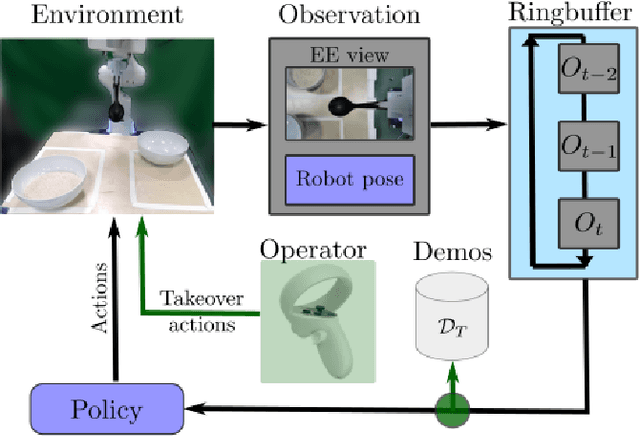
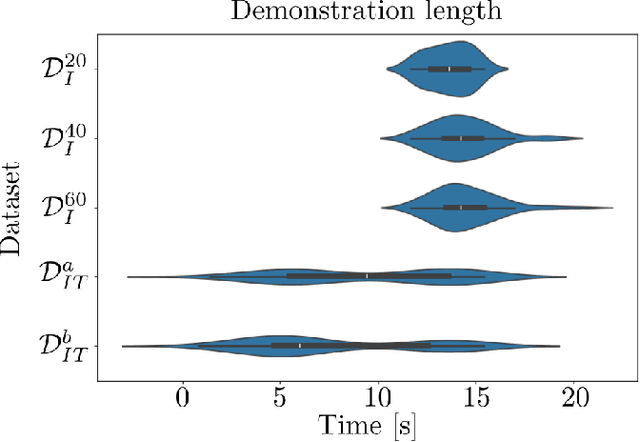
We present a Real-Time Operator Takeover (RTOT) paradigm enabling operators to seamlessly take control of a live visuomotor diffusion policy, guiding the system back into desirable states or reinforcing specific demonstrations. We presents new insights in using the Mahalonobis distance to automaicaly identify undesirable states. Once the operator has intervened and redirected the system, the control is seamlessly returned to the policy, which resumes generating actions until further intervention is required. We demonstrate that incorporating the targeted takeover demonstrations significantly improves policy performance compared to training solely with an equivalent number of, but longer, initial demonstrations. We provide an in-depth analysis of using the Mahalanobis distance to detect out-of-distribution states, illustrating its utility for identifying critical failure points during execution. Supporting materials, including videos of initial and takeover demonstrations and all rice-scooping experiments, are available on the project website: https://operator-takeover.github.io/
Puppeteer Your Robot: Augmented Reality Leader-Follower Teleoperation
Jul 16, 2024


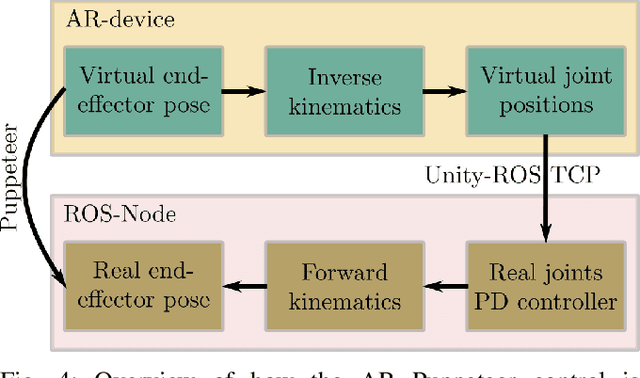
High-quality demonstrations are necessary when learning complex and challenging manipulation tasks. In this work, we introduce an approach to puppeteer a robot by controlling a virtual robot in an augmented reality setting. Our system allows for retaining the advantages of being intuitive from a physical leader-follower side while avoiding the unnecessary use of expensive physical setup. In addition, the user is endowed with additional information using augmented reality. We validate our system with a pilot study n=10 on a block stacking and rice scooping tasks where the majority rates the system favorably. Oculus App and corresponding ROS code are available on the project website: https://ar-puppeteer.github.io/
Low-Cost Teleoperation with Haptic Feedback through Vision-based Tactile Sensors for Rigid and Soft Object Manipulation
Mar 25, 2024



Haptic feedback is essential for humans to successfully perform complex and delicate manipulation tasks. A recent rise in tactile sensors has enabled robots to leverage the sense of touch and expand their capability drastically. However, many tasks still need human intervention/guidance. For this reason, we present a teleoperation framework designed to provide haptic feedback to human operators based on the data from camera-based tactile sensors mounted on the robot gripper. Partial autonomy is introduced to prevent slippage of grasped objects during task execution. Notably, we rely exclusively on low-cost off-the-shelf hardware to realize an affordable solution. We demonstrate the versatility of the framework on nine different objects ranging from rigid to soft and fragile ones, using three different operators on real hardware.
A Robotic Skill Learning System Built Upon Diffusion Policies and Foundation Models
Mar 25, 2024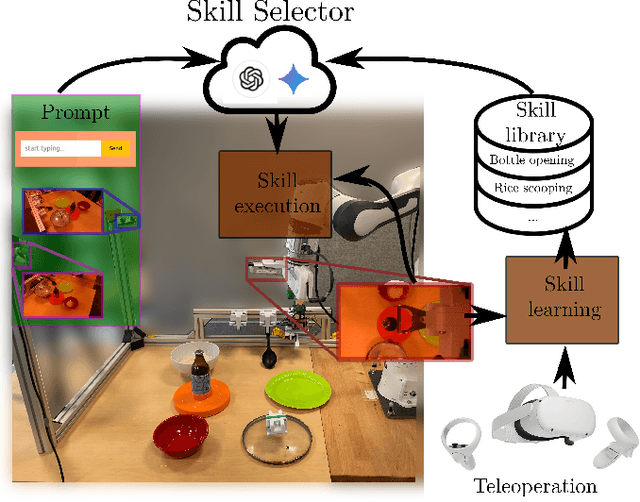

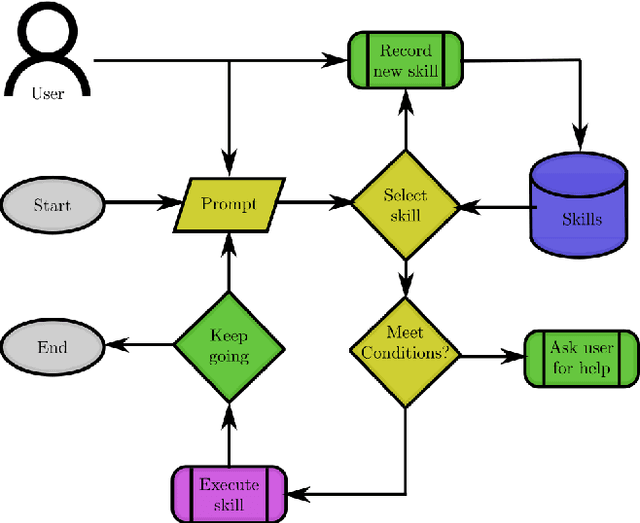
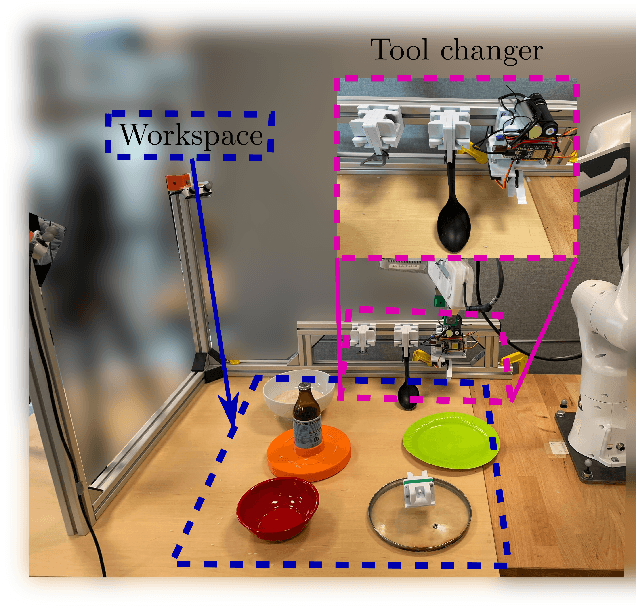
In this paper, we build upon two major recent developments in the field, Diffusion Policies for visuomotor manipulation and large pre-trained multimodal foundational models to obtain a robotic skill learning system. The system can obtain new skills via the behavioral cloning approach of visuomotor diffusion policies given teleoperated demonstrations. Foundational models are being used to perform skill selection given the user's prompt in natural language. Before executing a skill the foundational model performs a precondition check given an observation of the workspace. We compare the performance of different foundational models to this end as well as give a detailed experimental evaluation of the skills taught by the user in simulation and the real world. Finally, we showcase the combined system on a challenging food serving scenario in the real world. Videos of all experimental executions, as well as the process of teaching new skills in simulation and the real world, are available on the project's website.
Visual Action Planning with Multiple Heterogeneous Agents
Mar 25, 2024Visual planning methods are promising to handle complex settings where extracting the system state is challenging. However, none of the existing works tackles the case of multiple heterogeneous agents which are characterized by different capabilities and/or embodiment. In this work, we propose a method to realize visual action planning in multi-agent settings by exploiting a roadmap built in a low-dimensional structured latent space and used for planning. To enable multi-agent settings, we infer possible parallel actions from a dataset composed of tuples associated with individual actions. Next, we evaluate feasibility and cost of them based on the capabilities of the multi-agent system and endow the roadmap with this information, building a capability latent space roadmap (C-LSR). Additionally, a capability suggestion strategy is designed to inform the human operator about possible missing capabilities when no paths are found. The approach is validated in a simulated burger cooking task and a real-world box packing task.
AdaFold: Adapting Folding Trajectories of Cloths via Feedback-loop Manipulation
Mar 10, 2024
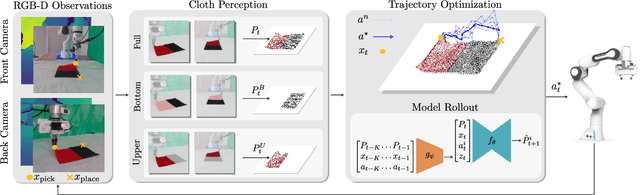

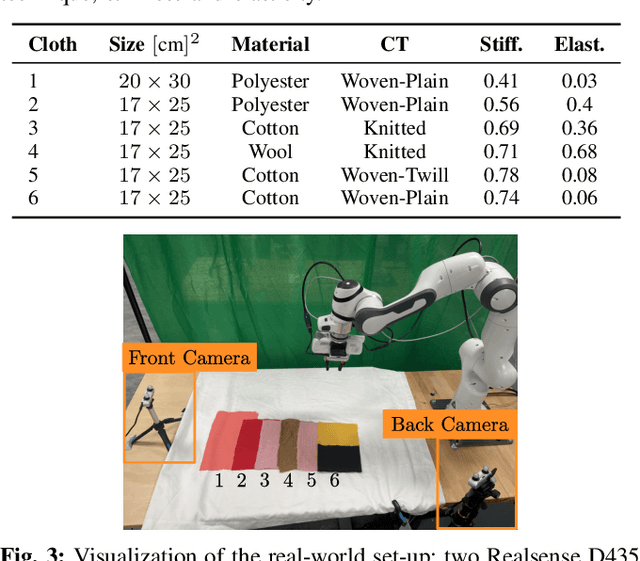
We present AdaFold, a model-based feedback-loop framework for optimizing folding trajectories. AdaFold extracts a particle-based representation of cloth from RGB-D images and feeds back the representation to a model predictive control to re-plan folding trajectory at every time-step. A key component of AdaFold that enables feedback-loop manipulation is the use of semantic descriptors extracted from visual-language models. These descriptors enhance the particle representation of the cloth to distinguish between ambiguous point clouds of differently folded cloths. Our experiments demonstrate AdaFold's ability to adapt folding trajectories to cloths with varying physical properties and generalize from simulated training to real-world execution.